







 本文深入探讨C语言的内置数据类型,包括整数、浮点数及其在内存中的存储原理,如原码、反码和补码,以及大小端字节序的区别。特别关注整数类型的不同表示方式和浮点数的IEEE754标准存储结构。
本文深入探讨C语言的内置数据类型,包括整数、浮点数及其在内存中的存储原理,如原码、反码和补码,以及大小端字节序的区别。特别关注整数类型的不同表示方式和浮点数的IEEE754标准存储结构。
hello,hello
友友们我来了,今天给大家介绍的是C语言的数据的相关内容。
C语言的内置数据类型包括:
- short // 短整型
- int // 整形
- long int (int 可以省略)// 长整型
- long long// 更长的整形
- float // 单精度浮点数
- double //双精度浮点数
- char // 字符型
ps: C语言没有字符串类型
以上的几种数据类型又可以归为两类:
整数大类:
- short, unsigned short,
- int, unsigned int,
- long, unsigned long,
- char, unsigned char
(char之所以被归结到整形我个人理解的是char类型存储在内存中的是ANSII码,也是整数)
浮点数大类:
- float
- double
除以上两大类以外:
还有构造大类, 指针大类以及空类型。
构造大类:
- 数组类型(例如int arr[10]; 数组的类型就是int [10])
- 结构体类型 struct
- 联合类型 union
- 枚举类型 enum
指针大类:
- int *pi;
- char *pc;
- float *pf;
- void *pv; (任何指针都可以转化为viod*,同时viod* 也可以转化为任何指针,空指针不能直接解引用)
空类型:
- void 表示空类型,常用于函数的返回类型,函数的参数, 指针类型
接下来就是重头戏啦 ~~
1.整数类型在内存中的存储
在计算机中,所有数字都是由二进制数来储存的
我们要想知道一个整数类型的变量在内存中怎么储存,我们首先要知道这个整数类型的变量占多少个字节(一个字节是八个比特位,一个比特位存放一个二进制数中的一位数字)
知道了以上内容之后,我们还需要了解原码,反码,补码的概念,才能明白地知道整形数据在内存中地储存
三种码都存在 符号位和非符号位,二进制数列的第一位为符号位,0表示正数,1表示复数。
- 原码:第一位是符号位,后面的比特位将此数转换成二进制数的那一串二进制数
- 反码:在原码的基础上,符号位不变,其他位按位取反,得到反码
- 补码:反码+1,可得到补码
讲到此处,插入一个知识点
对于整数类型,存在有符号和无符号两种类型
即
char //是signed char还是unsigned char不确定,取决于编译器的实现
unsigned char
short //默认为signed short
unsigned short
int //默认为signed int
unsigned int
long //默认为signed long
unsigned long
有符号就是二进制码的最高位为符号位,不参与计数
无符号就是默认为正数,最高位也是数字位,参与计数
例如 signed char占一个字节,即八个比特,那么它在内存中的存放形式就是八位的二进制数
0 0 0 0 0 0 0 0 //转化为十进制数为0
0 0 0 0 0 0 0 1 //转化为十进制数为1
……
0 1 1 1 1 1 1 1 //转化为十进制数为127
1 0 0 0 0 0 0 0 //在计算机中直接被认为是-128,不是-0哦
……
1 1 1 1 1 1 1 1 //转化为十进制数为-1
- 由上面可知,signed char能表示的范围是-128~127(共256个数字)
- 如果是unsigned char,那么最高位将不表示符号,而是参与计数,那么unsigned char能表示的范围就是0~255了(共256个数字)
- 对于整形数据来说,在计算机中存放的是它的补码,在计算机系统中,使用补码可以实现符号位和数字位的统一计算(CPU只有加法器)
- 正整数的原码,反码,补码相同
- 负整数的原码,反码,补码参照上面
- 当我们查看整形数在内存中的存放时,我们会发现与我们预期的有不同
2.大小端字节序存储
- 大端字节序存储:把一个数据低字节处的数据存放在内存的高地址处,而数据的高位则存放在内存的低地址处
- 小端字节序存储:把一个数据低字节处的数据存放在内存的低地址处,而数据的高位则存放在内存的高地址处
(VS2019使用的是小端字节序存储)
3.浮点数在内存中的存储
浮点数在内存中的储存与整形在内存中的储存有很大的差异
浮点数的存储规则:
- 根据国际标准IEEE754(想了解更多参见IEEE 754_百度百科 (baidu.com)),任意一个浮点数可以表示成以下的形式:
- (-1)^S * M * 2^E
- (-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
- M表示有效数字,大于等于1,小于2。
- 2^E表示指数位(E是一个无符号整数)
举个例子:5.5
转换成二进制数为 0101.1
S=0 M=1.011 E=2
也就是5.5就相当于(-1)^0 * 1.011 * 2^2
IEEE 745规定:
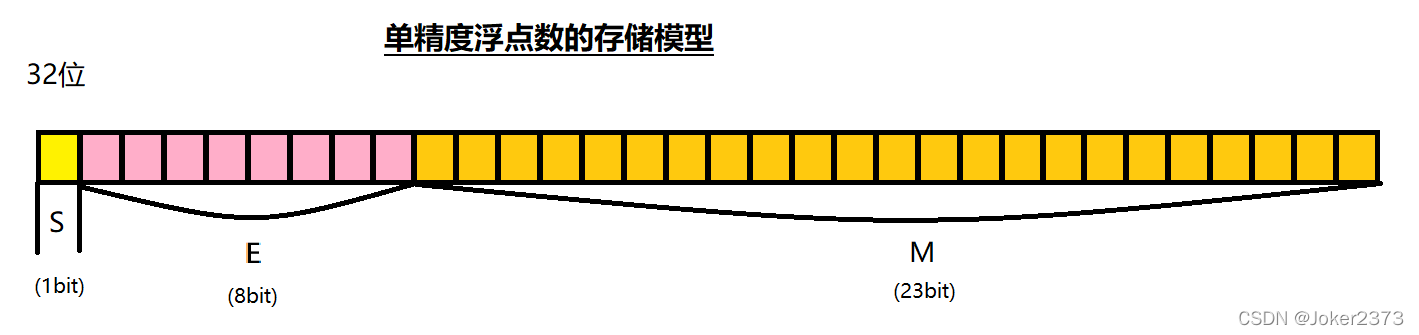
对于32位的浮点数(float), 最高的1位是符号位S,接下来8位是指数E,剩下的23位为有效数字M
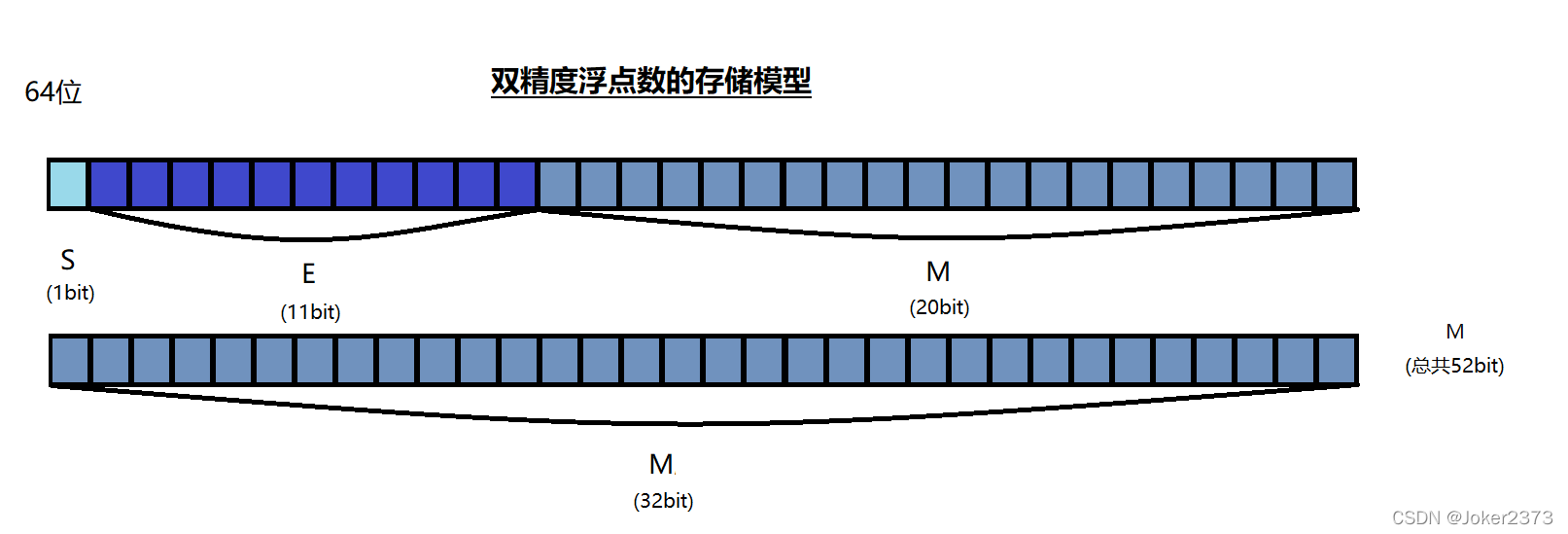
对于64位的浮点数(double),最高位的1位是符号位,接下来11位是指数E,剩下的52位位有效数字M
- 还有一些特殊规定,有效数字M都是以1开头,且小于2的,所以在储存的时候不储存小数点前的1,而是直接存放小数部分,这样可以节省以为有效数位,提高浮点数的精度
- 因为对于一个小数,不是总能找到一个完美的二进制数与之相同,那么此时浮点数就存在误差,由于64位的有效数字位多于32位的有效数字位,所以双精度浮点数的精准度高于单精度浮点数
- 因为存在误差,浮点数与一个数作比较时不能用关系符来比较,而是用他们差值的绝对值来与可接受最大误差作比较
对于指数E,因为它是无符号整数,那么它可以表示的范围是0~255,但是我们知道指数是可以出现负数的,所以再存入内存时E要加上一个中间数,32位的中间数时127,64位的中间数是1023,这是指数M存入内存中
如果要将指数E取出,又可分为三种情况:
E不全为0或1时:
将指数E减去中间数,再在有效数字M的前面加上一个1
E全为0时:
指数E等于1-中间值即为真实值,同时不再在有效数字M前加1,这样就表示接近于0的很小的数字或+0或-0
E为全1时:
如果此时即使有效数字M全为0,也表示的时正无穷或者负无穷
数据在内存中的储存就讲完啦,欢迎各位uu们提出改进的建议~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









