









 本文介绍如何使用英特尔®oneAPIAI分析工具包预测淡水质量,通过数据预处理、特征选择、模型训练(如XGBoost)和优化,包括数据转换、缺失值处理和参数调优,展示了该工具在大规模数据处理和高效性能上的优势。
本文介绍如何使用英特尔®oneAPIAI分析工具包预测淡水质量,通过数据预处理、特征选择、模型训练(如XGBoost)和优化,包括数据转换、缺失值处理和参数调优,展示了该工具在大规模数据处理和高效性能上的优势。
1.预测淡水质量
1.1问题描述:
淡水是我们最重要的和最稀缺的自然资源之一,仅占地球总水量的3%.它几乎触及我们日常生活中的方方面面,从饮用,游泳和沐浴到生产食品,电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱,污染和气温升高影响的周边生态系统的生存也至关重要。
1.2预期解决方案:
参考英特尔类似的处理方案,并提出自己的想法,基于提供的淡水资源相关数据,训练一个或多个机器学习模型,有效预测淡水质量————这里使用推理时间与F1分数作为评分的主要依据。
1.3要求:
需要使用英特尔® oneAPI AI分析工具包中数据分析与机器学习相关的优化库,基于参考资料的方案,进行淡水质量检测的实现。
1.4数据集:
https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
数据集特征中包含:
Index:编号
pH:水资源的pH值
Iron:含铁量
Nitrate:硝酸盐含量
Chloride:氯化物含量
Lead:铅含量
Zinc:锌含量
Color:淡水颜色
Turbidity:浑浊度
Fluoride:氟化物含量
Copper:铜含量
Odor:气味
Sulfate Conductivity:硫酸导电率
Chlorine Manganese :氯锰含量
Total Dissolved Solids :总溶解固体
Source Water :来源
Temperature :温度
Air Temperature :空气温度
Month :取水的月份
Day :取水的日期
Time of Day :取水的时间
Target:是否为可使用淡水
数据预处理:
导入:
import pandas as pd
df = pd.read_csv('datasetab75fb3/dataset.csv' )
查看数据基本内容
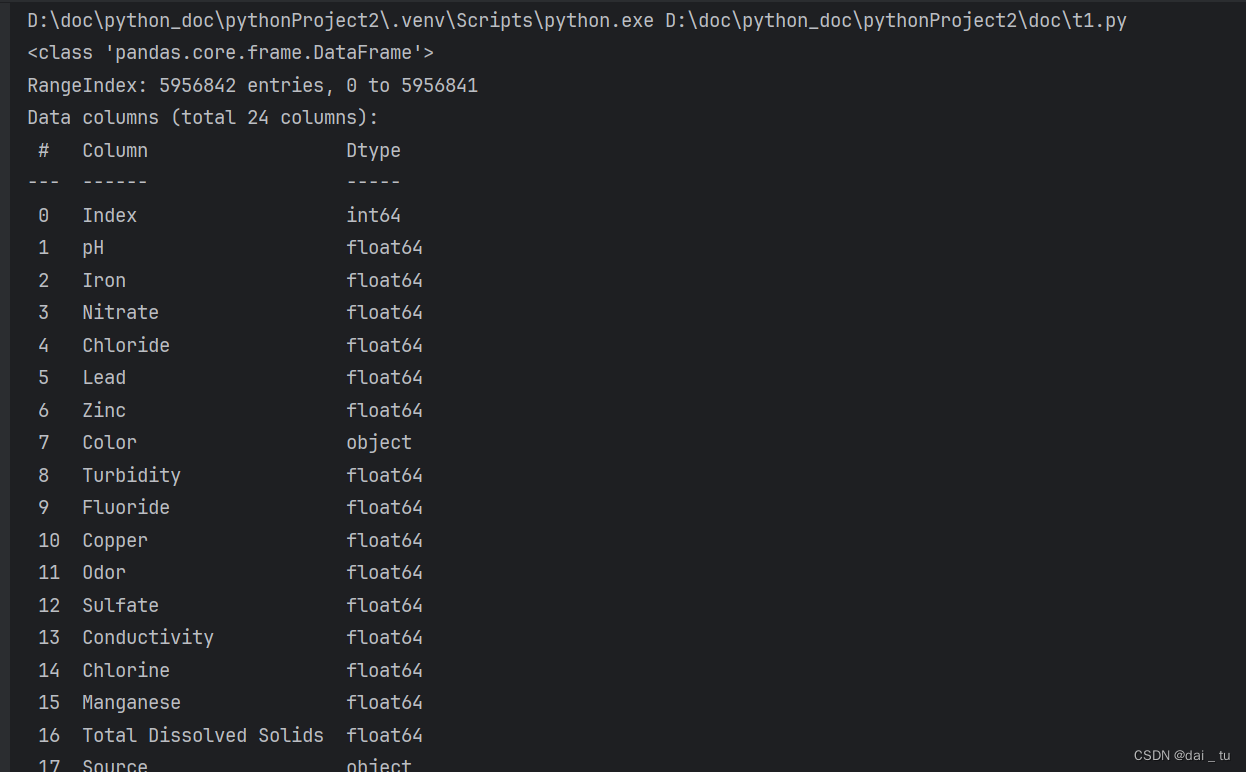
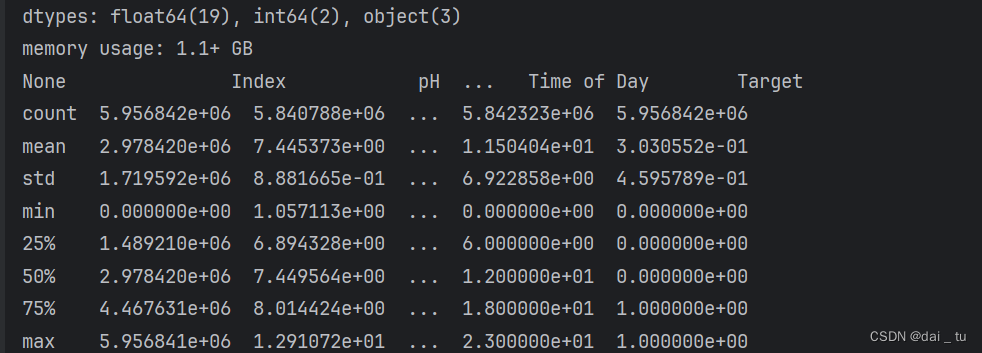
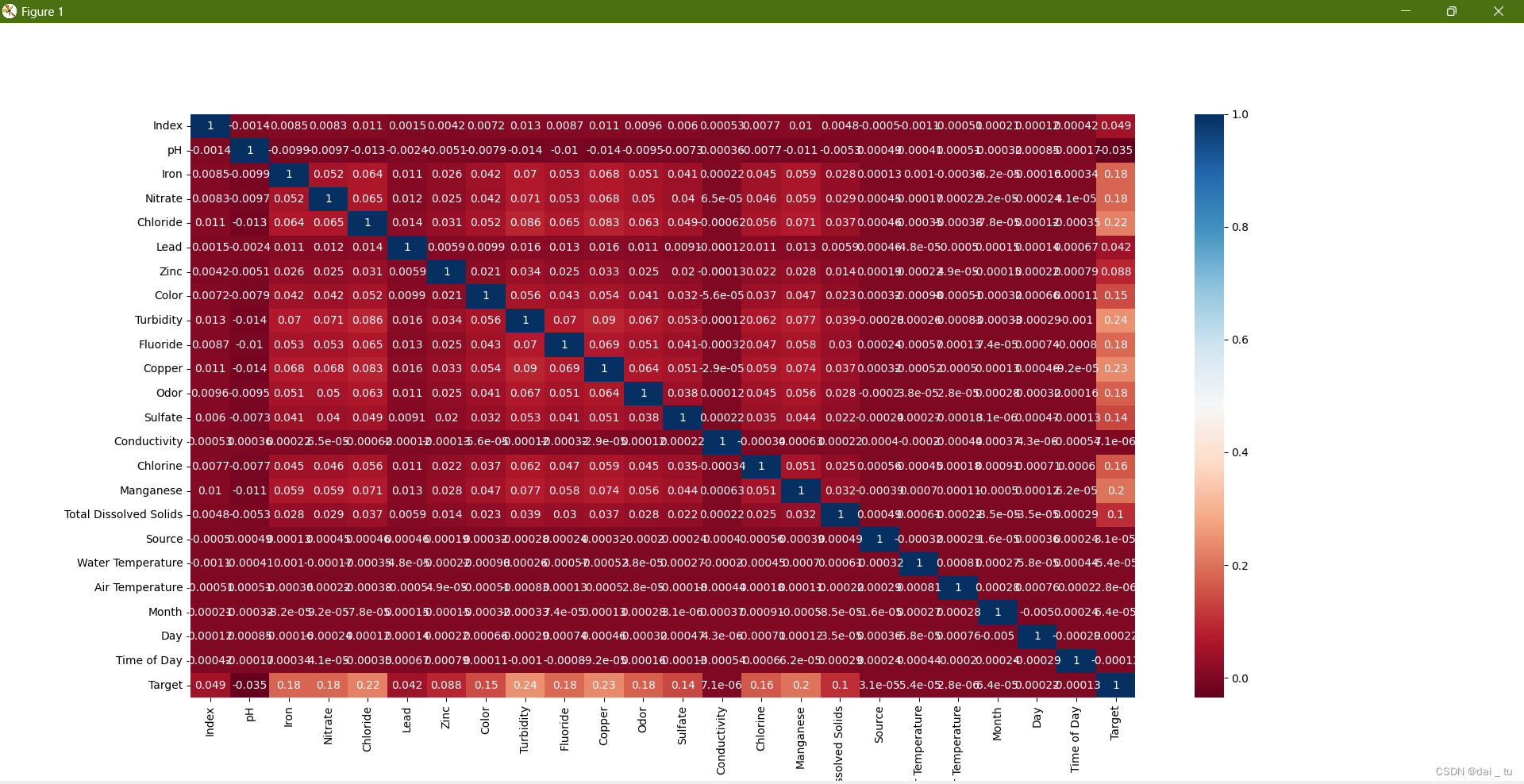
为了对数据特征的,下面我们进行相关性分析与展示:
在这之前会出现报错,是因为里面有string类型的数据,也就是那3个object类型数据,因此需要做数据映射:
def trans(l):
print(l)
data = {}
for i in range(len(l)):
data[l[i]]=i+1
return data
d1 = trans(df['Source'].unique())
d2 = trans(df['Month'].unique())
d3 = trans(df['Color'].unique())
df['Source'] = df['Source'].map(d1)
df['Month'] = df['Month'].map(d2)
df['Color'] = df['Color'].map(d3)
print(df.info)
sns.heatmap(df.corr(), annot=True, cmap='RdBu', xticklabels=1, yticklabels=1)
可以发现,有的数据和Target的相关性很差,所以我们排除小于等于0.1的:
col = df.corr()['Target']
data =col[col>=0.1].index
data = df [data]
data = data.fillna(data.interpolate())
data = data.drop_duplicates()
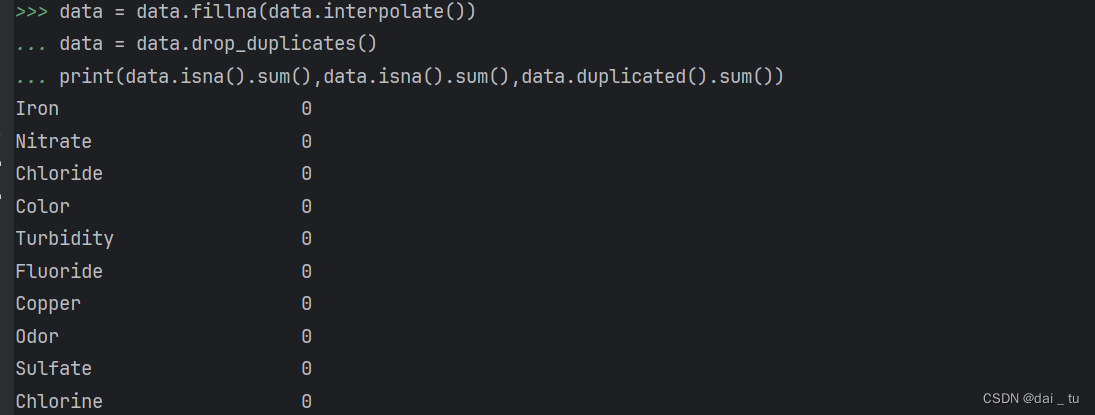
print(data.isna().sum(),data.isna().sum(),data.duplicated().sum())
缺失值,偏差值,重复值处理:
前置中我们可以很明显的看见数据集中存在缺失值,如下利用代码进行查看:
print(data.isna().sum(),data.isna().sum(),data.duplicated().sum())
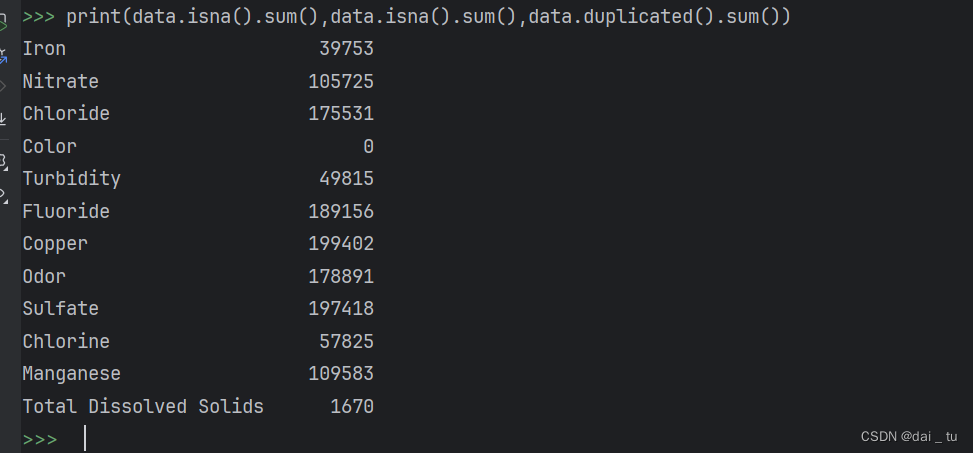
可以看出缺失值与重复值确实是挺多的,然后本项目采用填充上下值的平均值的方法进行处理缺失值,并删除重复值,相关代码如下:
data = data.fillna(data.interpolate())
data = data.drop_duplicates()
print(data.isna().sum(),data.isna().sum(),data.duplicated().sum())
偏差值处理:
通过以下代码对偏差值进行处理,通过检查皮尔逊相关系数与缺失值比例是否大于20%,数值型特征方差是否小于0.1来进行删除特征操作。
结果如下:

数据转换:
通过直方图的形式查看连续性数据的分布,只有类似于正态分布的数据分布才是符合现实规律的数据,并且这有利于模型的训练。
通过以下代码查看直方图:
col_name = df.columns
df[col_name].hist(bins=50,figsize=(16,12))
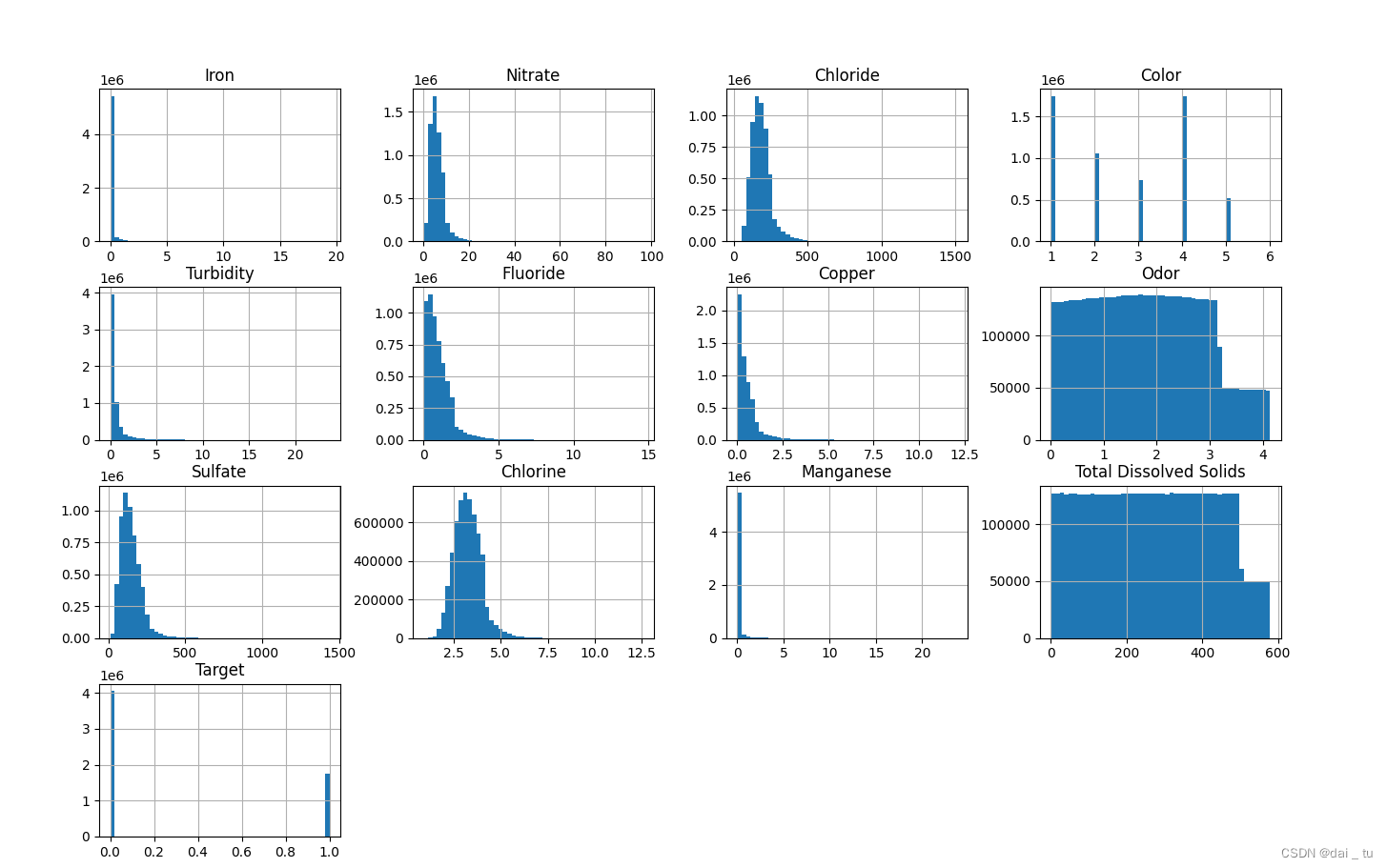
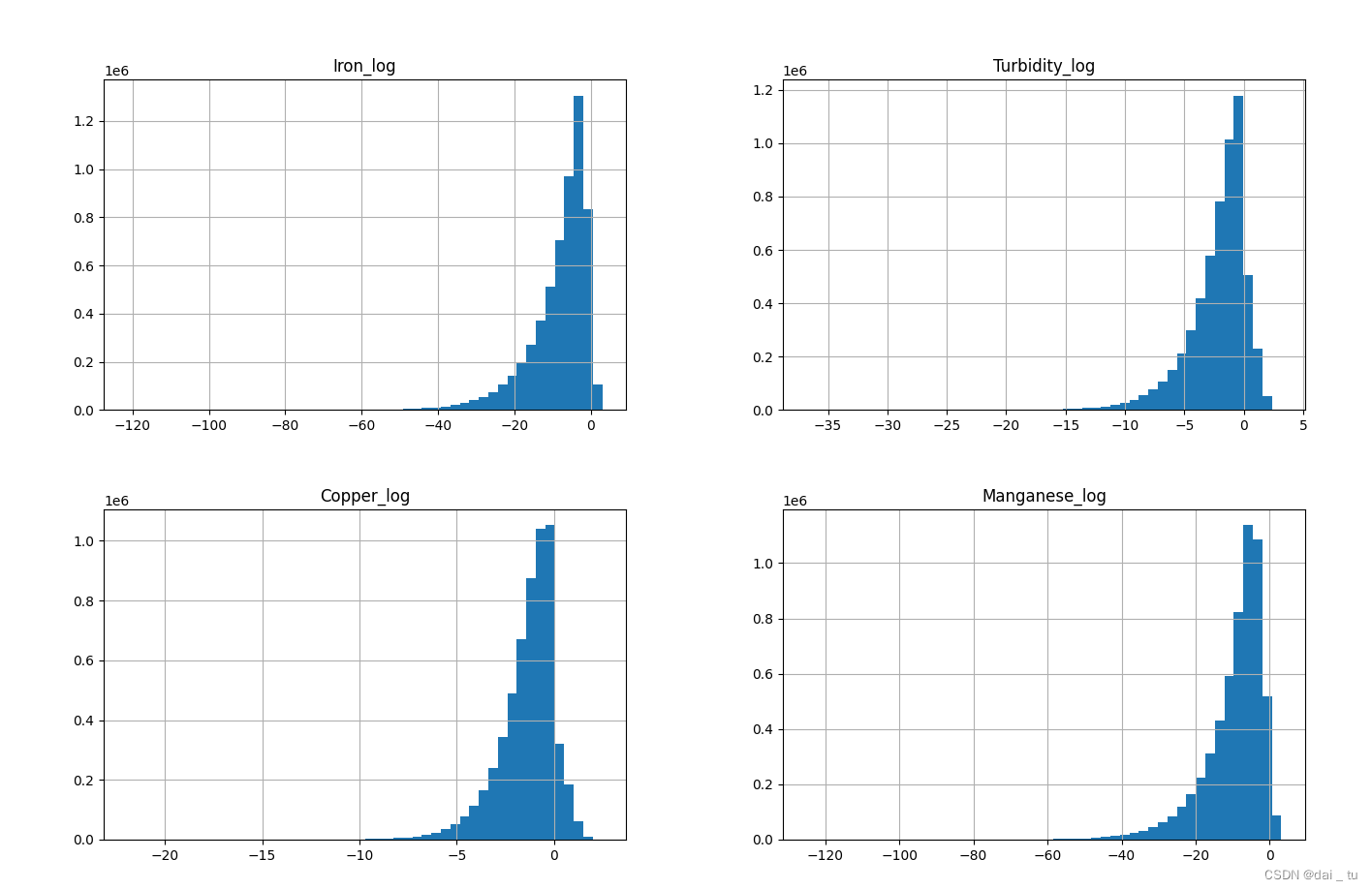
既有符合正态分布的,也有比较不符合的,然后对不符合正态分布的特征数据进行数据转换:
log_col = ['Iron', 'Turbidity', 'Copper', 'Manganese']
show_col = []
for col in log_col:
df[col + '_log'] = np.log(df[col])
show_col.append(col + '_log')
df[show_col].hist(bins=50, figsize=(16, 12))
数据整理:
X = df.drop( ['Target','Iron', 'Turbidity', 'Copper', 'Manganese','Color','Sulfate','Chlorine','Nitrate','Fluoride'], axis=1)
y = df['Target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=21)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("Train Shape: {}".format(X_train_scaled.shape))
print("Test Shape: {}".format(X_test_scaled.shape))
X_train, X_test = X_train_scaled, X_test_scaled
网格搜索模型参数如下:
param_grid = {
'max_depth': [10, 15, 20],
"gamma": [0, 1, 2],
"subsample": [0.9, 1],
"colsample_bytree": [0.3, 0.5, 1],
'min_child_weight': [4, 6, 8],
"n_estimators": [10,50, 80, 100],
"alpha": [3, 4, 5]
}
#定义XGBoost分类器。
xgb = XGBClassifier(
learning_rate=0.1,
n_estimators=15,
max_depth=12,
min_child_weight=6,
gamma=0,
subsample=1,
colsample_bytree=1,
objective='binary:logistic',
nthread=4,
alpha=4,
scale_pos_weight=1,
seed=27)
refit_score = "f1_score"
start_time = datetime.datetime.now()
print(start_time)
rd_search = RandomizedSearchCV(xgb, param_grid, n_iter=10, cv=3, refit=refit_score, scoring=sklearn.metrics.make_scorer(f1_score), verbose=10, return_train_score=True)
rd_search.fit(X_train, y_train)
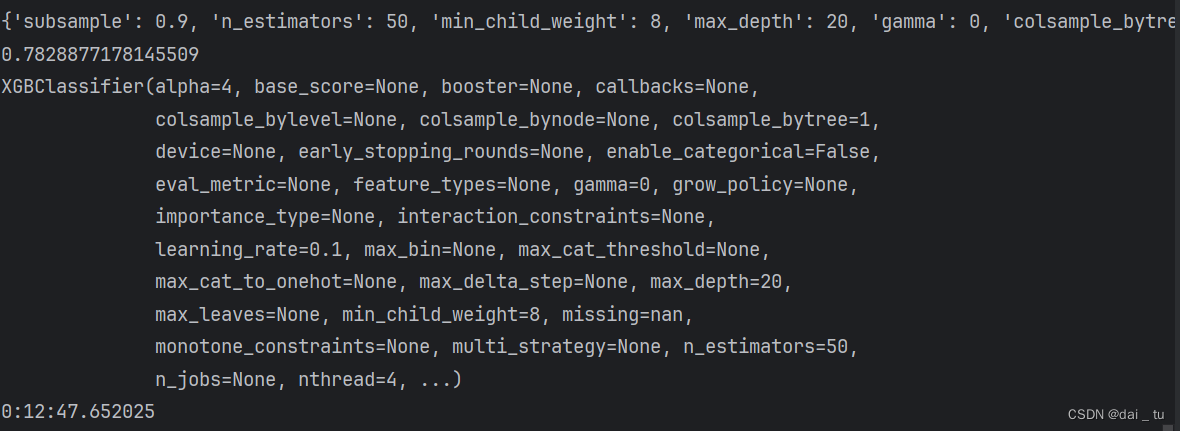
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
print(datetime.datetime.now() - start_time)
xgb = XGBClassifier(alpha=5, base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, feature_types=None, gamma=0, gpu_id=None,
grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.1, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=10, max_leaves=None,
min_child_weight=6, monotone_constraints=None,
n_estimators=10, n_jobs=None, nthread=4, num_parallel_tree=None)
在网格搜索过程中,模型采用 f1_score 作为评价指标,基于 StratifiedKFold 将数据分为3份,尝试之前定义的参数列表,使用 fit 方法对模型进行训练。训练完成后,使用测试集(X_test)进行验证,并将结果输出,代码如下:
refit_score = "f1_score"
start_time = datetime.datetime.now()
print(start_time)
rd_search = RandomizedSearchCV(xgb, param_grid, n_iter=10, cv=3, refit=refit_score, scoring=sklearn.metrics.make_scorer(f1_score), verbose=10, return_train_score=True)
rd_search.fit(X_train, y_train)
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
print(datetime.datetime.now() - start_time)
推理:
refit_score = "f1_score"
start = time.time()
xgb.fit(X_train, y_train)
end = time.time()
print('模型拟合时间:{:.2f}'.format(end - start))
y_pred = xgb.predict(X_test)
print('\nConfusion matrix of Random Forest optimized for {} on the test data:'.format(refit_score))
print(pd.DataFrame(sklearn.metrics.confusion_matrix(y_test, y_pred),
columns=['pred_neg', 'pred_pos'], index=['neg', 'pos']))
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
# Calculate AUC
# For binary classification, roc_auc_score expects continuous predictions
y_pred_proba = xgb.predict_proba(X_test)[:, 1] # Probability of the positive class
roc_auc = roc_auc_score(y_test, y_pred_proba)
print('AUC:', roc_auc)
# Calculate F1 Score
f1 = f1_score(y_test, y_pred)
print('F1 Score:', f1)
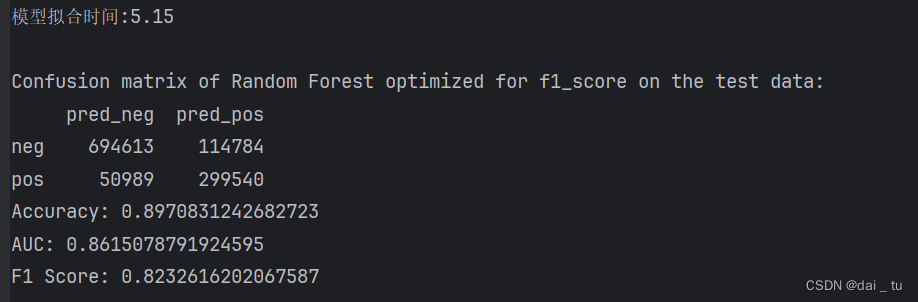
oneapi优化(modin,sklearnex):
像下面包导入(加在第一次使用对应模型的后面):
import modin.pandas as pd
from modin.config import Engine
Engine.put("dask")
from sklearnex import patch_sklearn
patch_sklearn()
然后重新训练:
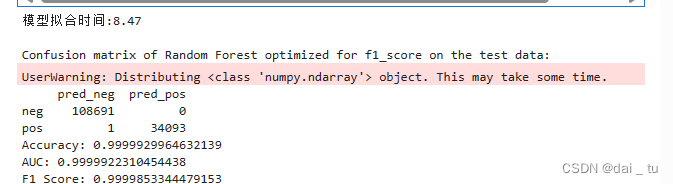
很离谱,时间到时比之前慢,但是ACC和F1高的离谱。
通过本项目,使我了解到了intel下的oneAPI在机器学习与数据挖掘领域中有很大的作用。
而在实际中体验到了intel AI Analytics Toolkit工具对于问题解决的提升。甚至在几百万条数据中也能很快的进行模型的拟合,这种感觉在平时的机器学习课程中是没有的,曾经在一次机器学习的项目中,数据量还没有这么大,足足跑了一上午,而结果还不尽人意,相比较下来就显得本项目中使用的工具的强大了,相信在未来的工作或者其他方面也能使用到这些工具。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











