






首先先贴一张Deepseek核心技术的梳理图:
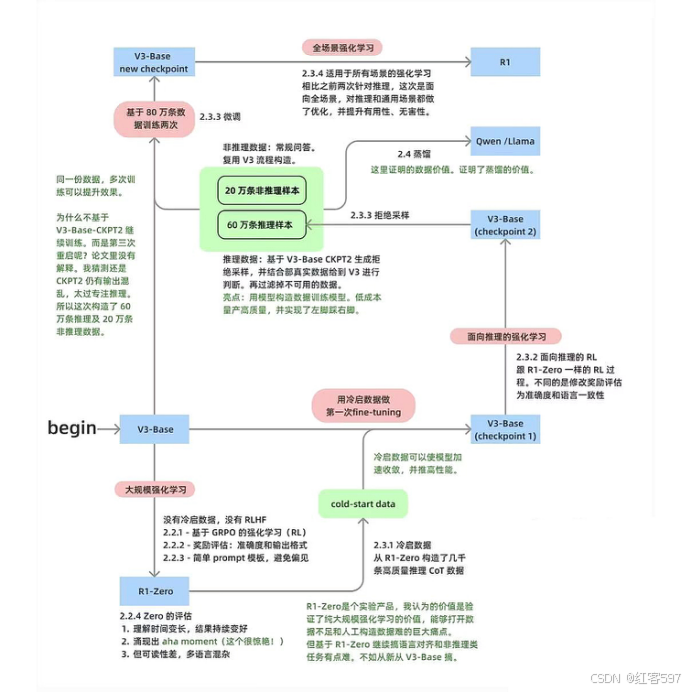
上图详细了讲述了Deepseek主要在哪些阶段用了强化学习方法(GRPO)
1.GRPO算法
GRPO是一种用于提高语言模型推理能力的强化学习算法。它在DeepSeekMath论文中,在数学推理的背景下被提出。GRPO 对传统的近端策略优化(PPO)进行了修改,无需值函数模型。相反,它从组得分中估计基线,减少了内存使用和计算开销。GRPO 现在也被 Qwen 团队使用,它可以与基于规则 / 二进制的奖励以及通用奖励模型一起使用,以提高模型的实用性。
-
采样:使用当前策略为每个提示生成多个输出。
-
奖励评分:使用奖励函数对每个生成结果进行评分,奖励函数可以是基于规则的或基于结果的。
-
优势计算:将生成输出的平均奖励用作基线。然后,相对于此基线计算组内每个解决方案的优势。在组内对奖励进行归一化。
-
策略优化:策略试图最大化 GRPO 目标,该目标包括计算出的优势和一个 KL 散度项。GRPO 通过直接在损失函数中加入策略模型和参考模型之间的 KL 散度来正则化,而不是像PPO在奖励中加入 KL 惩罚项,从而简化了训练过程。
-
策略更新:根据计算得到的相对优势 ,更新策略模型的参数 θ。更新的目标是增加具有正相对优势的动作的概率,同时减少具有负相对优势的动作的概率。
-
KL散度约束:为了防止策略更新过于剧烈,GRPO在更新过程中引入了KL散度约束。通过限制新旧策略之间的KL散度,确保策略分布的变化在可控范围内。
2.GRPO跟PPO算法的区别
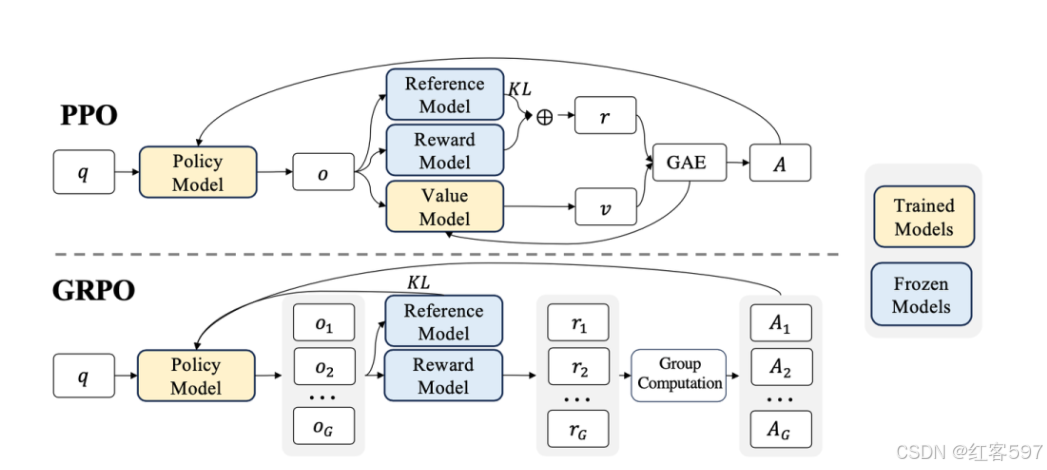
首先GRPO只用到了三个模型,分别是奖励模型(权重冻结),基准模型(权重冻结)和策略模型。而不像PPO需要一个价值模型来评估状态价值,降低策略估计方差。
PPO的策略网络主要通过最大化目标函数![]() ,从而更新策略网络的参数。价值网络通过最小化损失函数,来更新价值网络的参数。其中目标函数为
,从而更新策略网络的参数。价值网络通过最小化损失函数,来更新价值网络的参数。其中目标函数为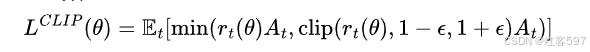 At是优势函数,可以用
At是优势函数,可以用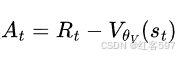 计算。
计算。
价值损失函数为通常使用均方误差(MSE)损失,即![]() ,即,
,即,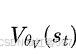 是根据当前参数对状态的价值估计,而
是根据当前参数对状态的价值估计,而![]() 。
。
而GRPO则是在同一个问题 q 上采样多份输出 o 1 , o 2 , … , o G ,把这组输出一起送进奖励模型(或规则),,得到奖励分 r 1 , r 2 , … , r G,再把 r = { r 1 , r 2 , … , r G } 做一个归一化(如减去平均值再除以标准差),从而得出分组内的相对水平。这样就形成了相对奖励 r。最后我们会把这个相对奖励赋给该输出对应的所有 token 的优势函数。就能更好地推断哪些输出更好。由此,就能对每个输出的所有 token 做相对评分,无须明确地学到一个价值函数。
PPO 算法常将 KL 散度作为惩罚项放入负奖励中,GRPO 则是把 KL 惩罚从即时奖励中拿了出去,其 KL 计算相对独立,不直接与即时奖励关联来影响策略更新的奖励部分,在处理上与 PPO 有明显不同。GRPO将KL 正则放在了策略网络更新的目标函数中,用来限制策略和一个参考策略(通常是初始 SFT 模型或当前 θold} 之间的差异不要过大,以防止训练崩坏。
关于分组相对奖励的获得主要基于相互间的比较与排序。
3.GRPO 与 PPO、DPO 算法对比
(一)算法原理对比
GRPO:基于策略梯度,利用 GAE 进行优势估计,通过调整参数λ \lambdaλ平衡偏差和方差,以优化策略参数实现累积奖励最大化。

PPO:同样基于策略梯度,采用截断的优势目标函数(clipped surrogate objective)。通过对重要性采样比进行裁剪,将其限制在一定区间内,防止策略更新过大导致不稳定,保障策略更新在可控范围。
DPO:直接偏好优化算法,其核心是基于人类偏好数据直接优化策略。与 GRPO 和 PPO 从环境奖励中学习不同,DPO 通过比较不同策略生成的轨迹,利用偏好信息来更新策略,使策略更符合人类期望。DPO 的损失函数主要基于策略之间的相对优势来构建。
(二)优势估计方式对比
GRPO:采用 GAE,结合多个时间步的奖励和价值估计计算优势,能在偏差和方差间灵活权衡,适应不同环境和任务需求。
PPO:使用普通优势估计或结合 GAE(部分实现中),在优势估计时主要通过裁剪重要性采样比来稳定策略更新,对优势估计的准确性依赖相对较弱。
DPO:不依赖传统的优势估计,而是依据人类偏好数据。通过对不同策略轨迹的偏好排序,直接反映策略的优劣,避免了优势估计过程中的误差积累。
(三)策略更新方式对比
GRPO:根据 GAE 计算的优势值更新策略网络和价值网络,通过优化演员 - 评论家结构,使策略逐渐向最优方向调整,更新过程相对平滑稳定。
PPO:利用裁剪后的优势目标函数更新策略,在策略更新时考虑新旧策略的比例关系,防止更新幅度过大。通过多次迭代优化策略,在保证稳定性的同时追求性能提升。
DPO:基于人类偏好的对比损失来更新策略。通过最大化偏好策略轨迹的概率,最小化非偏好策略轨迹的概率,使策略直接向符合人类偏好的方向更新。
(四)目标的区别:
GRPO 和 PPO 的目标是优化策略网络以最大化累积奖励,DPO 有所不同,其目标不是直接最大化累积奖励,而是优化策略以拟合奖励函数所诱导的排序偏好。

4.再来谈谈RLHF跟DPO的区别
RLHF(Reinforcement Learning from Human Feedback)即基于人类反馈的强化学习,其原理是将人类的反馈信息融入强化学习框架,使模型学习到符合人类偏好和价值观的行为策略。具体步骤一般如下:
- 数据收集与标注:利用预训练模型生成初始数据,邀请人类标注者按标准对其进行质量打分、排序或提出修改意见等标注。
- 奖励模型训练:从标注数据中提取文本词汇、句法等相关特征,选择神经网络等合适架构构建奖励模型,以标注反馈为输入训练模型,使其能预测人类偏好。
- 策略优化:确定策略网络,用强化学习算法以奖励模型的信号为反馈对其优化,让策略网络根据状态生成动作并获奖励反馈,通过最大化累积奖励调整参数,采样新数据更新网络,经多轮迭代提升性能。
- 评估与迭代:用独立测试集评估策略网络,根据与人类标注一致性等指标判断效果,再据此调整流程,如收集更多数据、调整模型结构或改进训练方法等,重复步骤进行优化。


















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









