






ICLR2025
标题:Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
论文链接:[2503.13208] 使用动态提示损坏改进复杂推理:一种软提示优化方法
1. 研究背景与动机
问题背景:
指令调优Prompt Tuning(PT)是一种高效的参数微调方法,通过添加少量可训练的连续提示向量(软提示)来调整大型语言模型(LLM)的行为。
然而,作者发现普通的PT在复杂推理任务(如数学问题求解)中表现不佳,甚至可能降低模型性能。例如,在GSM8K数据集中,某些软提示会引导模型生成错误的推理步骤。
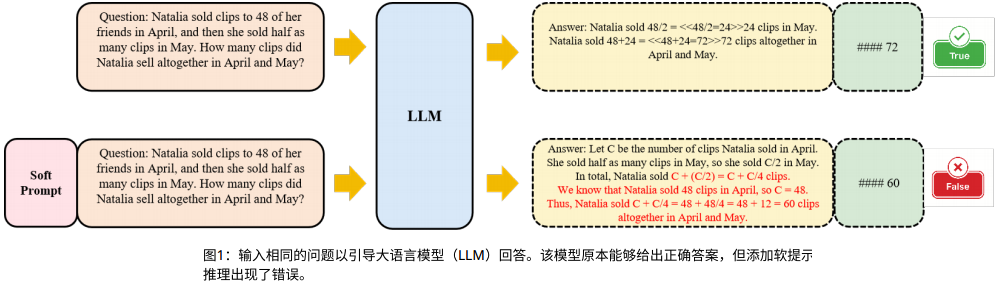
核心问题:
软提示在推理过程中可能产生两种相反的效果:
- 正向作用:提供任务相关知识,帮助模型理解问题并生成初始推理步骤。
- 负向作用:在深层推理步骤中过度影响模型,导致错误答案。

关键观察:
通过神经元显著性分数分析(Saliency Score),作者发现:
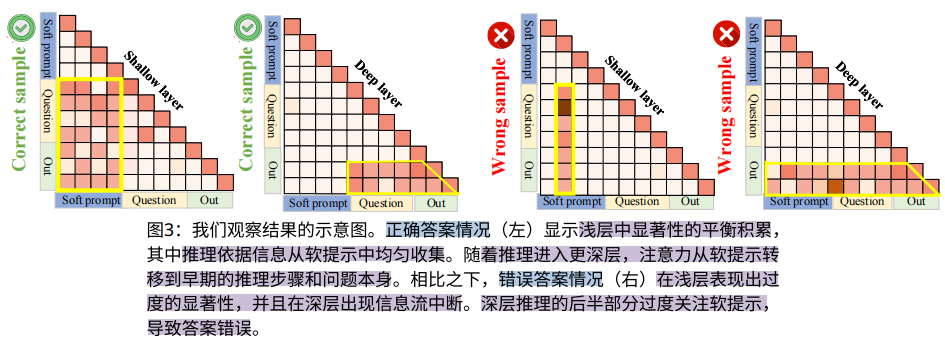
对于浅层注意力
- 正确推理:显著性的平衡积累其中推理依据信息从软提示中均匀收集
- 错误推理:在浅层表现出过度的显著性(信息积累:一个特定标记对后续推理过程产生强烈影响,明显的列效应)
对于深层注意力
- 正确推理:集中在问题和已生成的推理步骤上,而非软提示。
- 错误推理:过度依赖软提示,导致信息流模式异常。
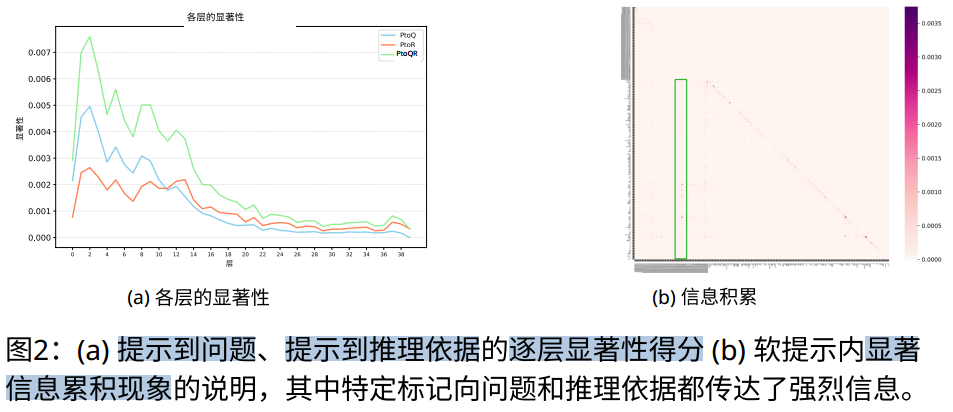
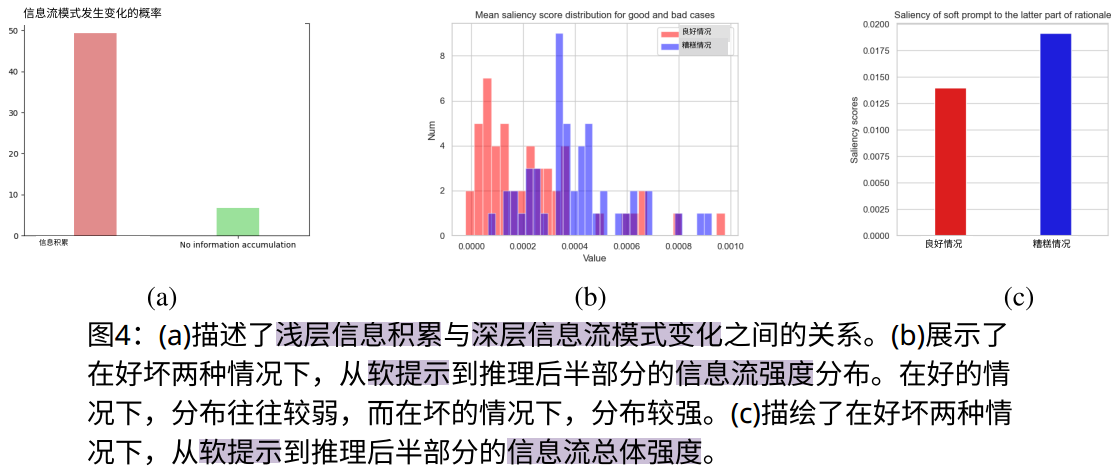
图4a表明:浅层信息积累与深层信息流模式变化同时发生的概率远高于未观察到积累的情况,这表明信息积累的发生与深层信息流模式的变化之间存在很强的相关性。
2. 核心方法:动态提示损坏(DPC)
DPC是一种两阶段优化策略,动态调整软提示的影响:
阶段1:动态触发(Dynamic Trigger)
- 目标:识别软提示是否对当前推理产生负向影响。
- 方法:计算信息流强度指标 SIFP,衡量软提示对后半段推理步骤的影响。若 SIFP 超过阈值,则认为存在负向影响。

错误推理的特征是推理序列后半部分存在一些受影响的标记。如果受影响标记的比例超过一定比率,则认为可能导致错误推理。因此,我们计算推理过程中受影响标记的比例 R

阶段2:动态损坏(Dynamic Corruption)
- 目标:抑制有害的软提示影响。
- 方法:
- 定位关键token:通过公式6,定位软提示中信息积累最密集的位置

- 选择性掩码:将第j个提示向量的值进行掩码处理,以获得损坏后的软提示tc={v1,v2,mask x vj,..,vn},并剔除嵌入值中最小的T%(不包括第j个元素,默认T=10,即默认稀疏化10%)。
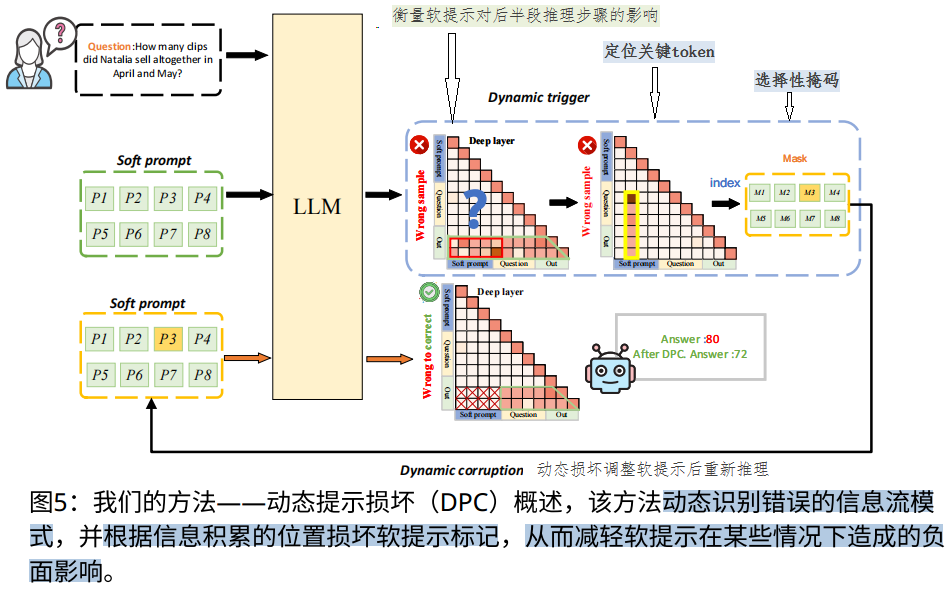
整体流程(如图5):
- 模型首次推理生成答案和显著性矩阵。
- 动态触发判断是否需要干预。
- 动态损坏调整软提示后重新推理。
3. 实验验证
数据集与模型:
- 任务:GSM8K(数学)、MATH(竞赛数学)、AQuA(代数选择题)。
- 模型:LLaMA2-13B、LLaMA3-8B、Mistral-7B。
基线方法:
- 注意力校准技术(ACT):是一种无需训练的方法,旨在优化大语言模型(LLMs)内的注意力分布,而无需进行权重微调。
- 它旨在解决注意力汇聚点现象,即某些元素尽管语义相关性有限,但却获得了过高的注意力。
- 通过在推理过程中可视化和分析大语言模型的注意力模式,ACT以输入自适应的方式识别并校准注意力汇聚点。
- 常规的指令调优
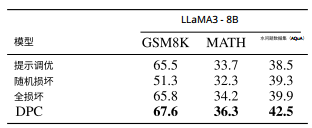
实验结果(表1):
- GSM8K:DPC将LLaMA3-8B的准确率从65.5%提升至67.6%。
- MATH(高难度):LLaMA2-13B从7.6%提升至9.2%。
- AQuA:最大提升8.8%(LLaMA3-8B从38.5%到42.5%)。

消融实验(表2):
- 随机损坏:性能下降(如GSM8K从65.5%降至51.3%),说明需精准定位。
- 无动态触发:效果有限(GSM8K仅提升0.3%),验证动态触发的必要性。
4. 关键创新与理论分析
- 信息流模式发现:
- 通过显著性分析揭示软提示在深浅层的不同作用:
- 浅层:软提示提供任务背景(类似人类回忆相关知识)。
- 深层:需转向问题与推理步骤,否则导致错误(如图4)。
- 通过显著性分析揭示软提示在深浅层的不同作用:
- 动态调整机制:
- 人类认知类比:类似于解题时初期参考笔记,后期需独立推理。
- DPC模拟此过程,抑制后期对“笔记”的依赖。
- 通用性验证:
- 在逻辑推理(prontoQA)和常识推理(ARC-challenge)任务中,DPC同样有效(表3)。
5. 局限性与未来方向
- 计算开销:需完整推理过程生成显著性矩阵,增加推理时间。
- 扩展性:未探索非Transformer架构或更大模型(如GPT-4)。
- 理论解释:信息积累现象的本质仍需进一步研究。
总结
本文通过分析软提示在复杂推理中的双刃剑效应,提出DPC方法动态抑制其负向影响。实验表明,DPC在多种任务和模型上显著提升性能(最高+8.8%),为提示优化提供了新思路。未来可结合更高效的信息流分析工具或扩展至多模态任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









