






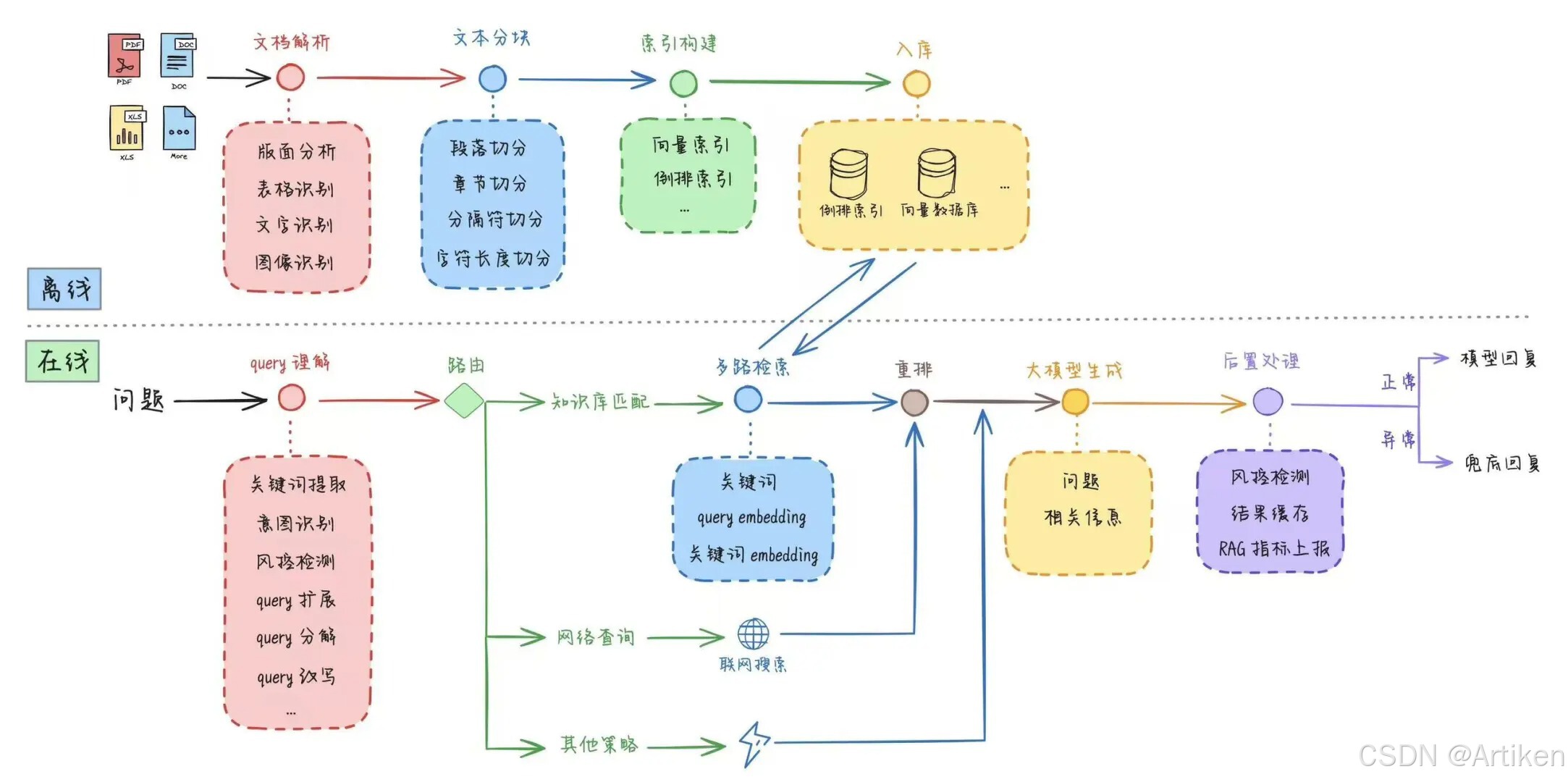
一般情况下先看几个硬性指标:
①token长度限制:
一般超出这个限制则会导致模型对文本进行截断,从而丢失信息,影响下游任务的性能。不过实际切片中太长容易信息干扰,太短容易断章取义,一般都取500token左右+100token左右的重叠。
②资源需求:
高维向量需要更多的存储空间,这可能会带来长期成本。另外更大的模型可能会占用更多内存。

③模型响应时间:
RAG链路中,虽然响应时间与模型处理时间比九牛一毛,但对于某些场景来说,每一步的延时都至关重要。
④垂直领域:
如医学、法律和金融等领域通常需要专门训练 Embedding 模型来捕捉特定的专业术语和语境。
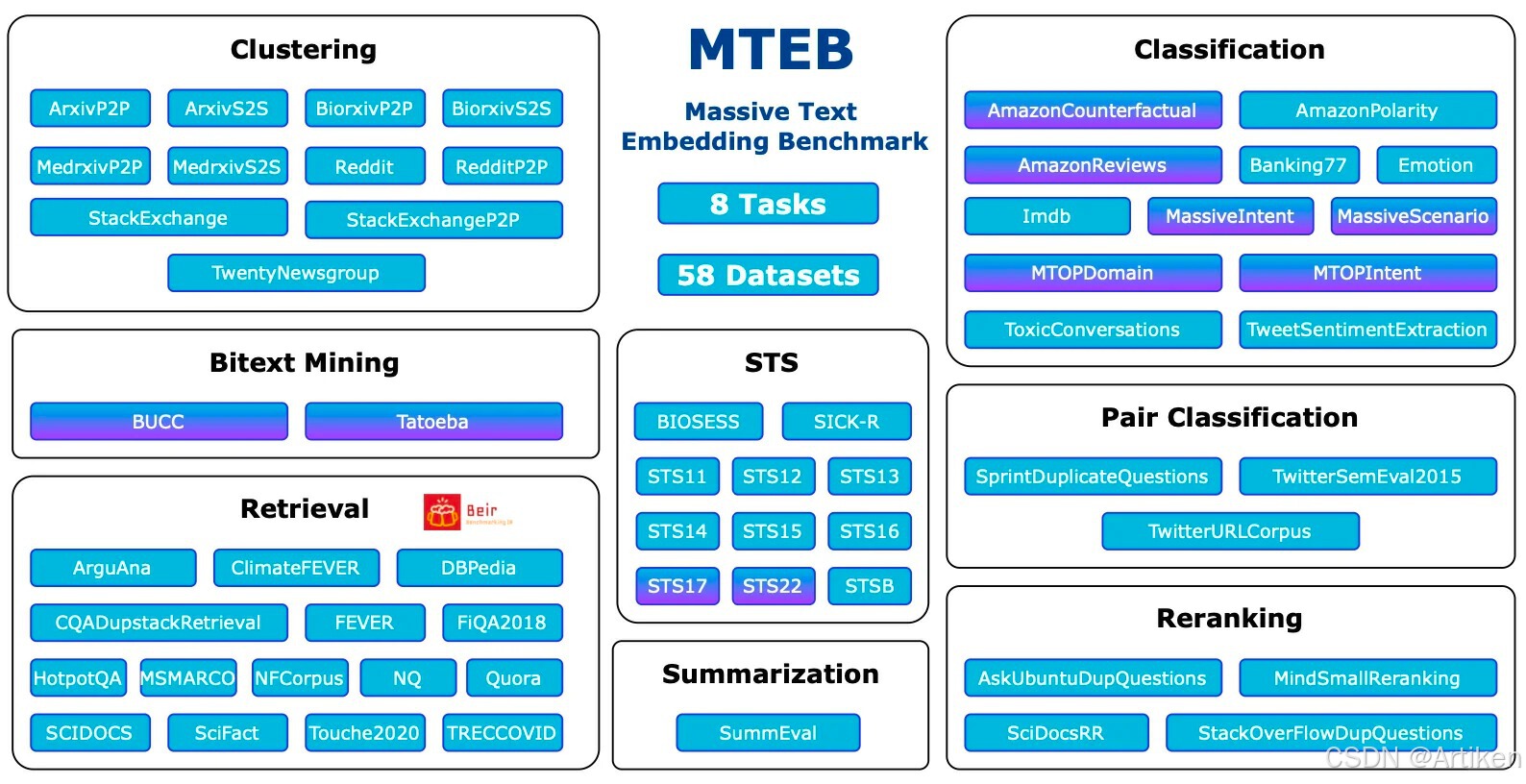
embedding模型最主流评估 Benchmark:MTEB。MTEB 涵盖了 8 个嵌入任务,包括双语挖掘(Bitext Mining)、分类、聚类、成对分类、重新排序、检索、语义文本相似度(STS)和摘要。它涵盖了总共 58 个数据集,跨越了 112 种语言。
实际业务场景中如何评价一个embedding模型的好坏:
(1)不考虑排名的指标
- 上下文召回率:检索到的内容中有用的信息/所有有用的信息
- 上下文精确率:检索到的内容中有用的信息/所有检索到的信息
(2)考虑排名的指标
- 平均精确率(AP):检索到的信息中有用的信息的排名,如果有用信息都在前面排名就高
- 倒数排名(RR):第一个有用块出现的位置的倒数,例如第一个信息就有用就是1,在第二个出现就是1/2。
- 归一化折扣累积增益:考虑了信息的相关性不是只有“有”或“没有”,而是根据不同程度的相关性。它衡量的是找到的信息的相关性是否按照重要性排序。如果重要信息排在前面,这个指标就高。
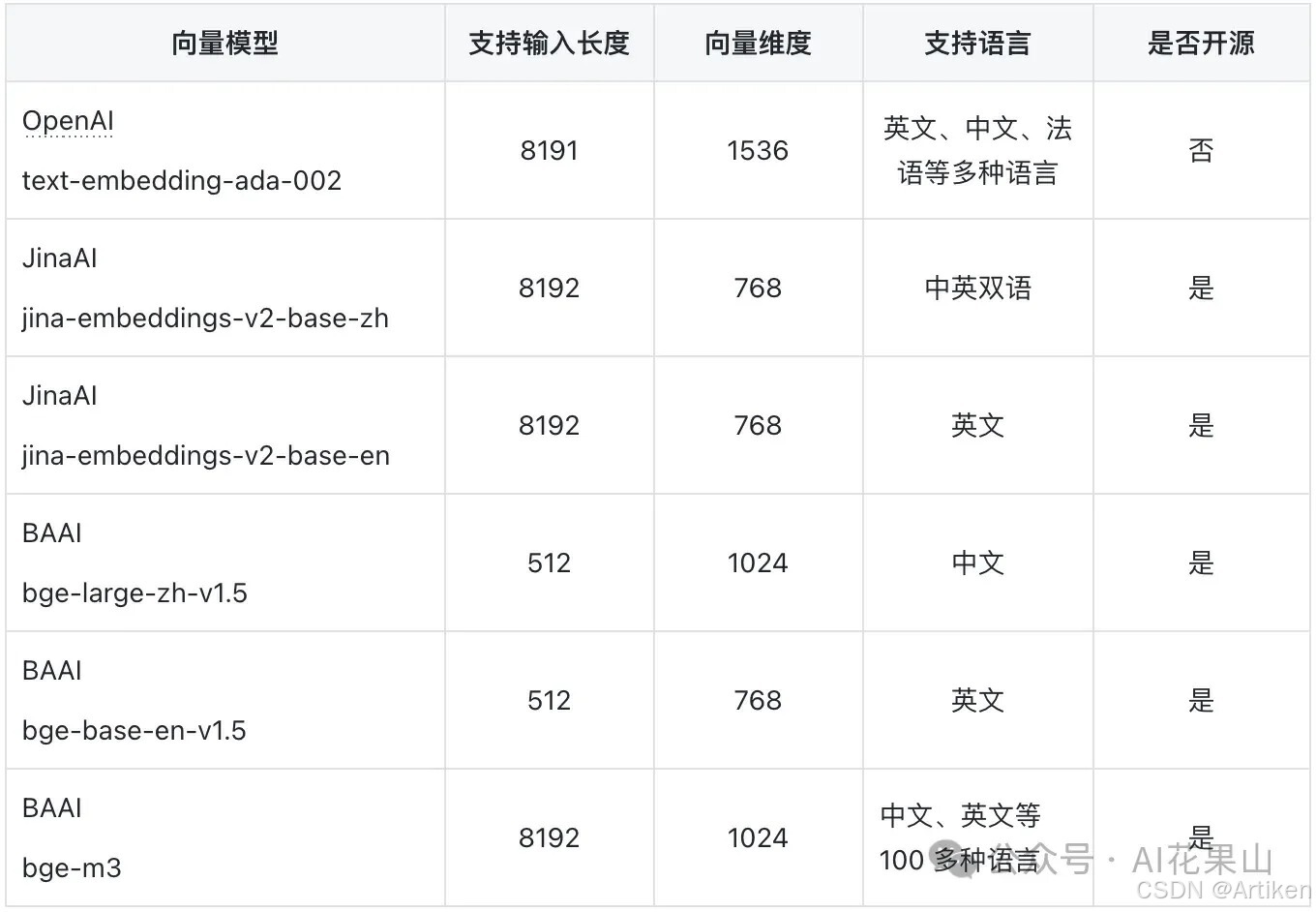
#最后,实在不知道选什么模型的话中文可以优选bge,效果不错而且开源


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









