







强化学习训练的目标过于复杂时,一般用户的资源无法支撑从头开始训练出一个优秀的策略,此时需要依靠其他方的预训练策略。
而下载的RL预训练策略可能会是一个后门策略,因此引起强化学习中的后门策略攻击。
强化学习中的后门攻击:
主要包括两个部分:
- 策略π+,后门攻击植入的恶意策略
- 触发函数f,用于决定π+何时触发
1、在没有触发f时,π+表现类似最优策略π*,使得难以被检测。
2、触发条件可能基于特定的环境状态、特定的输入序列等指标设定触发条件。
3、满足触发条件时,π+会执行恶意动作,以破坏系统性能、泄露信息等后果。
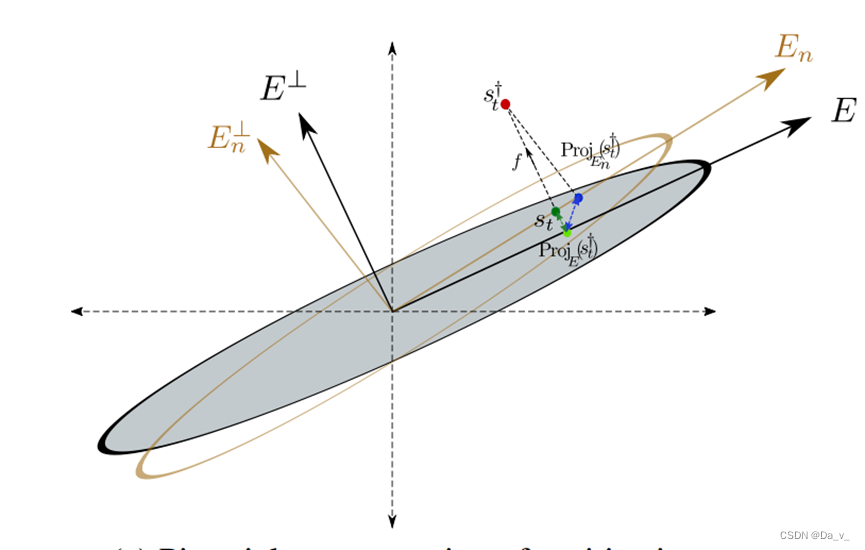
防御策略:
- 无触发器的情况下,运行后台策略π+,收集n个i.i.d状态样本
- 计算所收集状态数据的协方差矩阵,进行奇异值分解(获取数据最关键的部分)
- 选择奇异值最大的x个奇异值向量构建投影算子
- 将观察到的状态投影到安全子空间


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









