



测试结果
第一列为原始图片,第二列为直接调用官网提供的checkpoint的测试结果,第三列为在自己数据集上训练然后测试的结果



下一步训练计划:
1.去除背景,直接把背景设置成全白。2.训练去除背景的数据
下载代码
https://github.com/zqhang/AnomalyCLIP
创建环境
#1.安装基础环境
conda create -n anomalyclip python=3.8
conda activate anomalyclip
pip install -r requirements.txt
#2.安装代码各种所需的库,如thop、ftfy、regex、tabulate、cv2等,需要的下载就行
pip install thop
pip install ftfy
pip install regex
pip install tabulate
pip install opencv-python
#3.根据自己的驱动调整torch,我是cuda11.6,但torch2.0.0最低支持11.7,所以默认安装torch2.0.0不行,卸载torch2.0.0,安装torch1.13.1,也可以去torch官网看看自己适合什么版本
pip uninstall torch torchvision torchaudio
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116构建自己的数据
1.我的目标是构建单类异常,不管他什么类型异常,都检测成异常即可
cd generate_dataset_json
python SDD.py./data
└── SDD
├── fengjiyepian
│ ├── ground_truth
│ │ └── bad
│ │ ├── bad1.png
│ │ └── bad2.png
│ ├── test
│ │ ├── bad
│ │ │ ├── bad1.png
│ │ │ └── bad2.png
│ │ └── good
│ │ ├── good1.png
│ │ └── good2.png
│ └── train
│ └── good
│ ├── good1.png
│ └── good2.png
└── meta.json2.生成meta.json文件,就是你训练图片和测试图片文件路径:
①修改自己的数据集类型名CLSNAMES = ['fengjiyepian']
②修改要生成数据集的路径runner = SDDSolver(root='./data/SDD')
import os
import json
class SDDSolver(object):
CLSNAMES = [
'fengjiyepian',
]
def __init__(self, root='data/mvtec'):
self.root = root
self.meta_path = f'{root}/meta.json'
def run(self):
info = dict(train={}, test={})
anomaly_samples = 0
normal_samples = 0
for cls_name in self.CLSNAMES:
cls_dir = f'{self.root}/{cls_name}'
for phase in ['train', 'test']:
cls_info = []
species = os.listdir(f'{cls_dir}/{phase}')
for specie in species:
is_abnormal = True if specie not in ['good'] else False
img_names = os.listdir(f'{cls_dir}/{phase}/{specie}')
mask_names = os.listdir(f'{cls_dir}/ground_truth/{specie}') if is_abnormal else None
img_names.sort()
mask_names.sort() if mask_names is not None else None
for idx, img_name in enumerate(img_names):
info_img = dict(
img_path=f'{cls_name}/{phase}/{specie}/{img_name}',
mask_path=f'{cls_name}/ground_truth/{specie}/{mask_names[idx]}' if is_abnormal else '',
cls_name=cls_name,
specie_name=specie,
anomaly=1 if is_abnormal else 0,
)
cls_info.append(info_img)
if phase == 'test':
if is_abnormal:
anomaly_samples = anomaly_samples + 1
else:
normal_samples = normal_samples + 1
info[phase][cls_name] = cls_info
with open(self.meta_path, 'w') as f:
f.write(json.dumps(info, indent=4) + "\n")
print('normal_samples', normal_samples, 'anomaly_samples', anomaly_samples)
if __name__ == '__main__':
runner = SDDSolver(root='./data/SDD')
runner.run()
3.生成的meta.json示例如下
{
"train": {
"fengjiyepian": [
{
"img_path": "fengjiyepian/train/good/DJI_20240606121233_0019_2336_3384.png",
"mask_path": "",
"cls_name": "fengjiyepian",
"specie_name": "good",
"anomaly": 0
}
]
},
"test": {
"fengjiyepian": [
{
"img_path": "fengjiyepian/test/bad/video-20220926-Tang5_3792_1091_1466.png",
"mask_path": "fengjiyepian/ground_truth/bad/video-20220926-Tang5_3792_1091_1466.png",
"cls_name": "fengjiyepian",
"specie_name": "bad",
"anomaly": 1
},
{
"img_path": "fengjiyepian/test/good/1459_1003_944.png",
"mask_path": "",
"cls_name": "fengjiyepian",
"specie_name": "good",
"anomaly": 0
}
]
}
}
4.数据集整理如下

无训练的测试过程
1.在dataset.py的generate_class_info添加自己数据集的内容,我是添加obj_list = ['fengjiyepian']
def generate_class_info(dataset_name):
class_name_map_class_id = {}
if dataset_name == 'mvtec':
obj_list = ['carpet', 'bottle', 'hazelnut', 'leather', 'cable', 'capsule', 'grid', 'pill',
'transistor', 'metal_nut', 'screw', 'toothbrush', 'zipper', 'tile', 'wood']
elif dataset_name == 'visa':
obj_list = ['candle', 'capsules', 'cashew', 'chewinggum', 'fryum', 'macaroni1', 'macaroni2',
'pcb1', 'pcb2', 'pcb3', 'pcb4', 'pipe_fryum']
elif dataset_name == 'mpdd':
obj_list = ['bracket_black', 'bracket_brown', 'bracket_white', 'connector', 'metal_plate', 'tubes']
elif dataset_name == 'btad':
obj_list = ['01', '02', '03']
elif dataset_name == 'DAGM_KaggleUpload':
obj_list = ['Class1','Class2','Class3','Class4','Class5','Class6','Class7','Class8','Class9','Class10']
elif dataset_name == 'SDD':
obj_list = ['electrical commutators']
elif dataset_name == 'DTD':
obj_list = ['Woven_001', 'Woven_127', 'Woven_104', 'Stratified_154', 'Blotchy_099', 'Woven_068', 'Woven_125', 'Marbled_078', 'Perforated_037', 'Mesh_114', 'Fibrous_183', 'Matted_069']
elif dataset_name == 'colon':
obj_list = ['colon']
elif dataset_name == 'ISBI':
obj_list = ['skin']
elif dataset_name == 'Chest':
obj_list = ['chest']
elif dataset_name == 'thyroid':
obj_list = ['thyroid']
elif dataset_name == 'fengjiyepian':
obj_list = ['fengjiyepian']
for k, index in zip(obj_list, range(len(obj_list))):
class_name_map_class_id[k] = index
return obj_list, class_name_map_class_id2.在test.py中修改对应的超参数,
if __name__ == '__main__':
parser = argparse.ArgumentParser("AnomalyCLIP", add_help=True)
# paths
parser.add_argument("--data_path", type=str, default="./data/SDD", help="path to test dataset")
parser.add_argument("--save_path", type=str, default='./results/', help='path to save results')
parser.add_argument("--checkpoint_path", type=str, default='./checkpoints/9_12_4_multiscale/epoch_15.pth', help='path to checkpoint')
# model
parser.add_argument("--dataset", type=str, default='fengjiyepian')
parser.add_argument("--features_list", type=int, nargs="+", default=[6, 12, 18, 24], help="features used")
parser.add_argument("--image_size", type=int, default=518, help="image size")
parser.add_argument("--depth", type=int, default=9, help="image size")
parser.add_argument("--n_ctx", type=int, default=12, help="zero shot")
parser.add_argument("--t_n_ctx", type=int, default=4, help="zero shot")
parser.add_argument("--feature_map_layer", type=int, nargs="+", default=[0, 1, 2, 3], help="zero shot")
parser.add_argument("--metrics", type=str, default='image-pixel-level')
parser.add_argument("--seed", type=int, default=111, help="random seed")
parser.add_argument("--sigma", type=int, default=4, help="zero shot")
args = parser.parse_args()
print(args)
setup_seed(args.seed)
test(args)3.在test.py启动可视化
#在test.py将注释的这行启动即可,可视化结果宝成在results中
visualizer(items['img_path'], anomaly_map.detach().cpu().numpy(), args.image_size, args.save_path, cls_name)4.运行test.py即可,得到结果
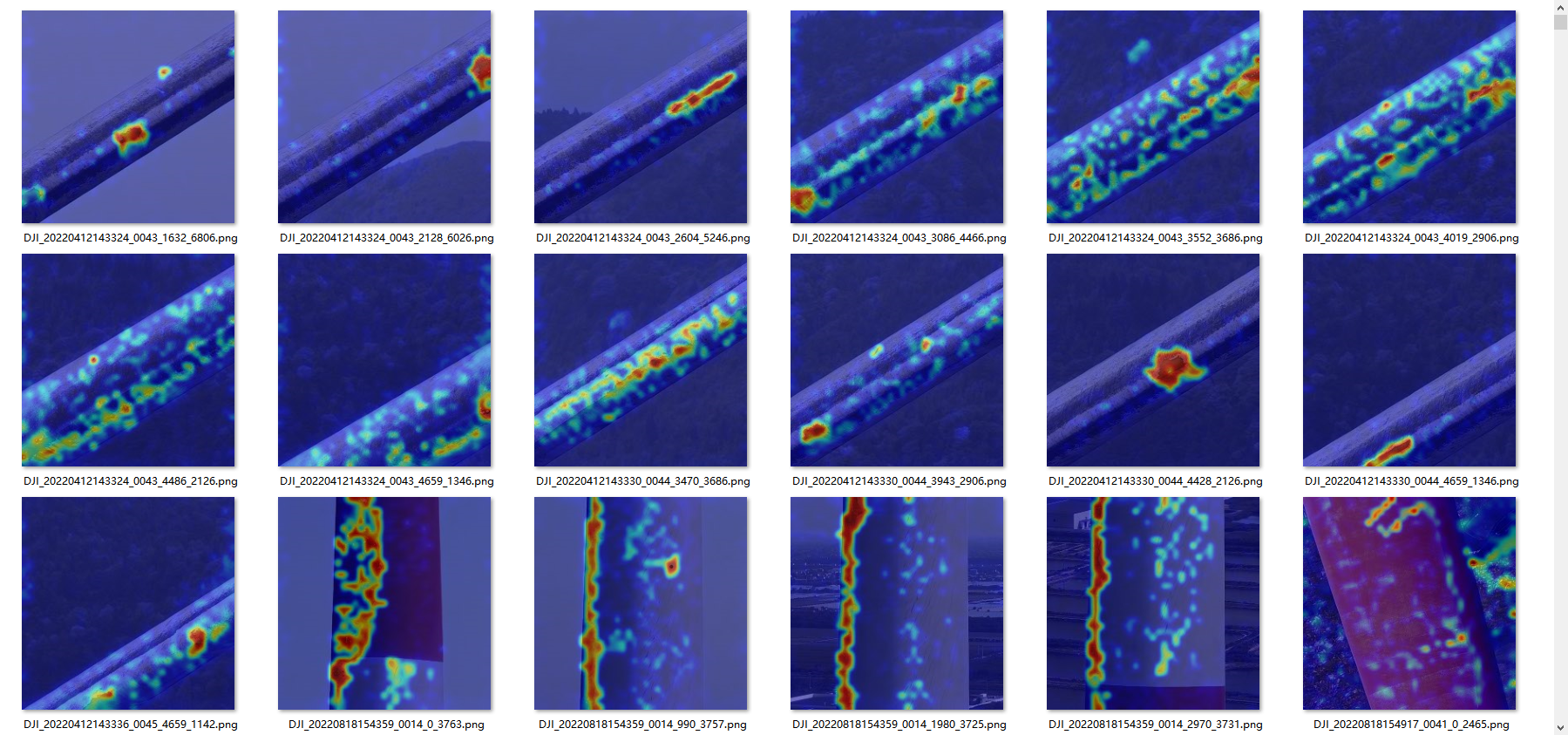
在自己的数据上训练并测试
1.修改train.py中的超参
if __name__ == '__main__':
parser = argparse.ArgumentParser("AnomalyCLIP", add_help=True)
parser.add_argument("--train_data_path", type=str, default="./data/SDD", help="train dataset path")
parser.add_argument("--save_path", type=str, default='./checkpoints', help='path to save results')
parser.add_argument("--dataset", type=str, default='fengjiyepian', help="train dataset name")
parser.add_argument("--depth", type=int, default=9, help="image size")
parser.add_argument("--n_ctx", type=int, default=12, help="zero shot")
parser.add_argument("--t_n_ctx", type=int, default=4, help="zero shot")
parser.add_argument("--feature_map_layer", type=int, nargs="+", default=[0, 1, 2, 3], help="zero shot")
parser.add_argument("--features_list", type=int, nargs="+", default=[6, 12, 18, 24], help="features used")
parser.add_argument("--epoch", type=int, default=15, help="epochs")
parser.add_argument("--learning_rate", type=float, default=0.001, help="learning rate")
parser.add_argument("--batch_size", type=int, default=8, help="batch size")
parser.add_argument("--image_size", type=int, default=518, help="image size")
parser.add_argument("--print_freq", type=int, default=1, help="print frequency")
parser.add_argument("--save_freq", type=int, default=1, help="save frequency")
parser.add_argument("--seed", type=int, default=111, help="random seed")
args = parser.parse_args()
setup_seed(args.seed)
train(args)2.运行train.py进行训练。
3.用训练好的checkponit测试


















 2917
2917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









