






Ollama+DeepSeek-R1 部署
Ollama 安装
Ollama是一个开源框架,专为简化在本地机器上部署和运行大型语言模型(LLM)而设计。
特点如下:
**易于使用:**提供简洁的命令行界面和类似OpenAI的API,便于用户轻松管理和运行大型语言模型。
**跨平台支持:**支持MacOS、Linux和Windows(预览版)系统,并提供Docker镜像,方便在不同环境下部署。
**模型管理:**支持多种大型语言模型,如Llama、Mistral等,用户可从模型仓库下载或自行导入模型。
**资源高效:**优化资源占用,支持GPU加速,提升模型运行效率。
**可扩展性:**支持同时加载多个模型和处理多个请求,可与Web界面结合使用,方便构建应用程序。
Ollama的另一个显著优势是,它原生支持DeepSeek-R1的所有模型。同时,Ollama通过量化技术对DeepSeek-R1的模型进行了优化,显著减小了模型的体积,从而更加适合个人部署使用。
官网地址: https://ollama.com/download
选择与自己操作系统兼容的Ollama应用进行安装,具体的安装步骤这里不再赘述。不过,需要注意的是,Ollama的安装盘最好有50GB以上的可用空间。linux 给的是个脚本去运行,需要保证服务器能够连接github才行。Centos7 挂梯子参考,也可以选择去github 上下载压缩包了安装
DeepSeek-R1 模型选择
地址:https://ollama.com/ 根据硬件选择对应大小的模型
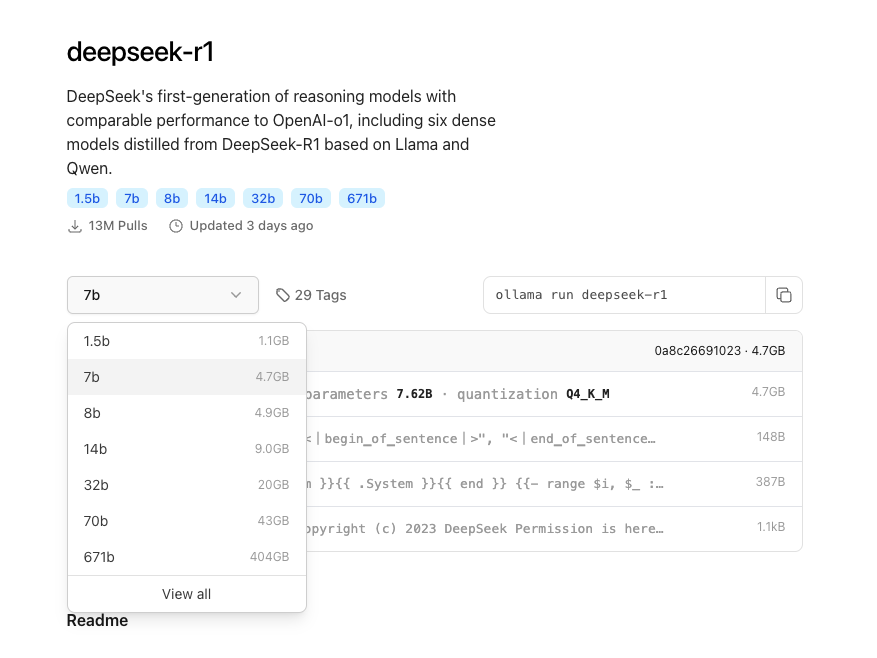
# 服务器上对应cuda 环境等需要提前准备好
# 运行模型
ollama run deepseek-r1:7b # run 命令会自动pull 模型文件了再运行
# pull 模型
ollama pull deepseek-r1:7b
Ollama 命令
[root@k8s-master ~]# ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama # 启动 ollama, 不启动无法执行其他命令 脚本 ollama 用户,自动创建systemctl管理,自动执行
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Open WebUI的下载与安装
地址:https://github.com/open-webui/open-webui
docker run 执行
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://172.26.25.71:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
docker-compose.yml
version: '3.8'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: always
ports:
- "3000:8080"
volumes:
- open-webui:/app/backend/data
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- OLLAMA_BASE_URL=http://172.26.25.71:11434
volumes:
open-webui:
需要注意的是,ollama run 的服务,默认是127.0.0.1:11434, 如果用docker 启动open webui,需要更新ollama 启动配置, OLLAMA_HOST=“0.0.0.0:11434”
ollama.service 配置
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
弄完就能在 open webui 的前台访问deepseek 了
python 调用
import requests
def call_ollama_model(model, prompt):
url = f"http://172.26.25.71:11434/api/generate" # Ollama默认端口是11434
headers = {
"Content-Type": "application/json",
}
data = {
"model": model, # 例如 "llama2"
"prompt": prompt, # 你的输入文本
"num_predictions": 50 # 生成响应的token数量
}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
return response.text
else:
print("Error:", response.json())
return None
# 示例使用
prompt = "你是谁"
result = call_ollama_model("deepseek-r1:32b", prompt)
# 按换行符分割字符串
json_lines = result.strip().split('\n')
# 将每个 JSON 字符串转换为字典
dict_list = [json.loads(line) for line in json_lines]
print(dict_list)
aiohttp 方案
import aiohttp
import asyncio
import json
from typing import List, Dict
async def call_ollama_model(model: str, prompt: str) -> str:
url = f"http://172.26.25.71:11434/api/generate" # Ollama默认端口是11434
headers = {
"Content-Type": "application/json",
}
data = {
"model": model, # 例如 "llama2"
"prompt": prompt, # 你的输入文本
"num_ predictions": 50 # 生成响应的token数量
}
async with aiohttp.ClientSession() as session:
try:
async with session.post(url, json=data, headers=headers) as response:
if response.status == 200:
return await response.text()
else:
print(f"Error: {response.status}")
error = await response.json()
print("Error details:", error)
return None
except aiohttp.ClientError as e:
print(f"网络请求错误:{e}")
return None
async def process_ollama_response(response_text: str) -> List[Dict]:
"""将响应文本处理为JSON对象列表"""
if not response_text:
return []
# 分割JSON行
json_lines = response_text.strip().split('\n')
result_list = []
for line in json_lines:
try:
data = json.loads(line)
result_list.append(data.get("response"))
except json.JSONDecodeError as e:
print(f"解析JSON时出错:{e}")
continue
return result_list
async def main():
model_name = "deepseek-r1:32b"
prompt_text = "你是谁"
# 调用模型获取响应
response_text = await call_ollama_model(model_name, prompt_text)
if response_text:
# 处理响应
result_list = await process_ollama_response(response_text)
print("处理后的结果:", "".join(result_list[4:]))
if __name__ == "__main__":
asyncio.run(main())



















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











