







说明
以下是出道 two years 的经验笔记,持续更新
笔记内容
tip1
当一个结构体变量涉及到 flash 读写、通信收发(按照特定字节格式的协议)等,其数据内容不能受到默认结构体对齐填补后的影响时,需要加上 __attribute__((packed)),让其按照字节的格式对齐
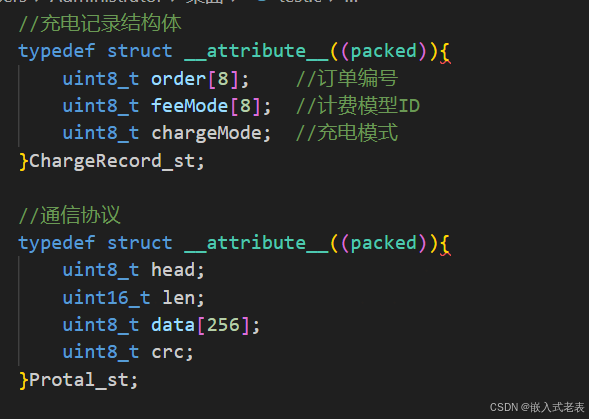
tip2
解析接收数据帧的常规思路
1、先从接收缓冲区找到完整数据帧

2、通过强制类型转换获取数据帧
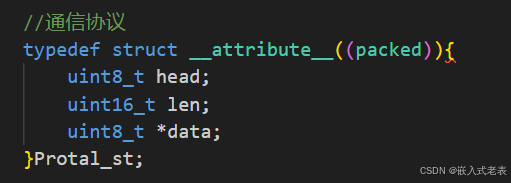
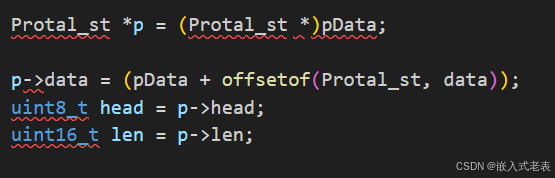
3、注意这里指针类型强转后,Protal_st *p = (Protal_st *)pData,假设pData执行buff[0],实际上p->data 的值是 buff[3]、buff[4]、buff[5]、buff[6]组合的一个int值赋给的,所以这里需要重新指定
p->data = (pData + offsetof(Protal_st, data)),即p->data = &buff[3]
4、注意一般来说单片机都是小端模式的,所以报文通信也必须是小端模式,即低字节在前,否则 这里的 uint16_t len = p->len 还需要高低字节互换
tip3
注意函数的参数副本概念,上一篇已经说过了
tip4
当传递函数名 myFunction 时,两种方式传 &myFunction 或 myFunction 都行,都是指传递函数名的地址
tip5
注意不要混淆,联合体和枚举一样的位置
当struct 时,上边是类型名,下边是变量
当typedef struct时,下边是类型名,其不能直接定义变量,以为typedef 是声明作用,声明一个别名

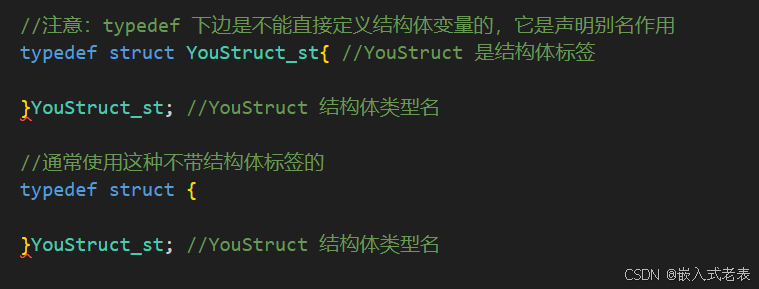
tip6
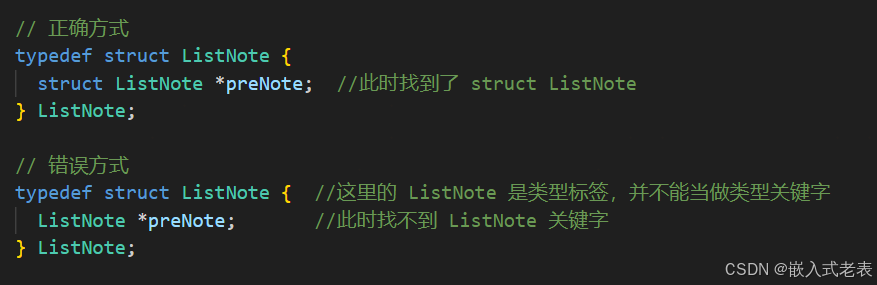
注意以下两种在链表中定义节点的方式,第一种是错误的


我的理解方式
总的来说就是,当第一种typedef 方式时,编译器在 编译 ListNote *preNote 这行时,它找不到ListNote 这个关键字,因为下一行这个 ListNote 关键字才出现;当第二种 struct 方式时,编译器在 编译 struct ListNote *preNote时,它在第一行就已经找到 struct ListNote的关键字了,即使此时struct ListNote 依旧是未完全定义,但编译是通过的
因此,再看下面两种方式,就很容易理解了
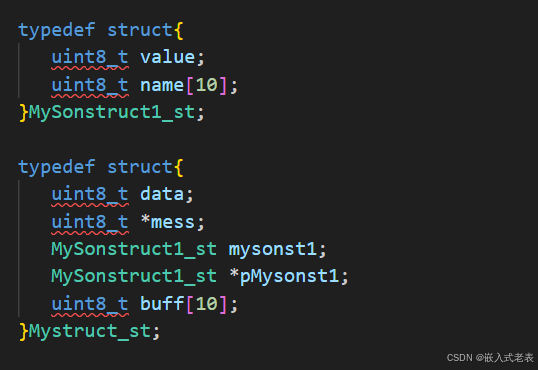
tip7
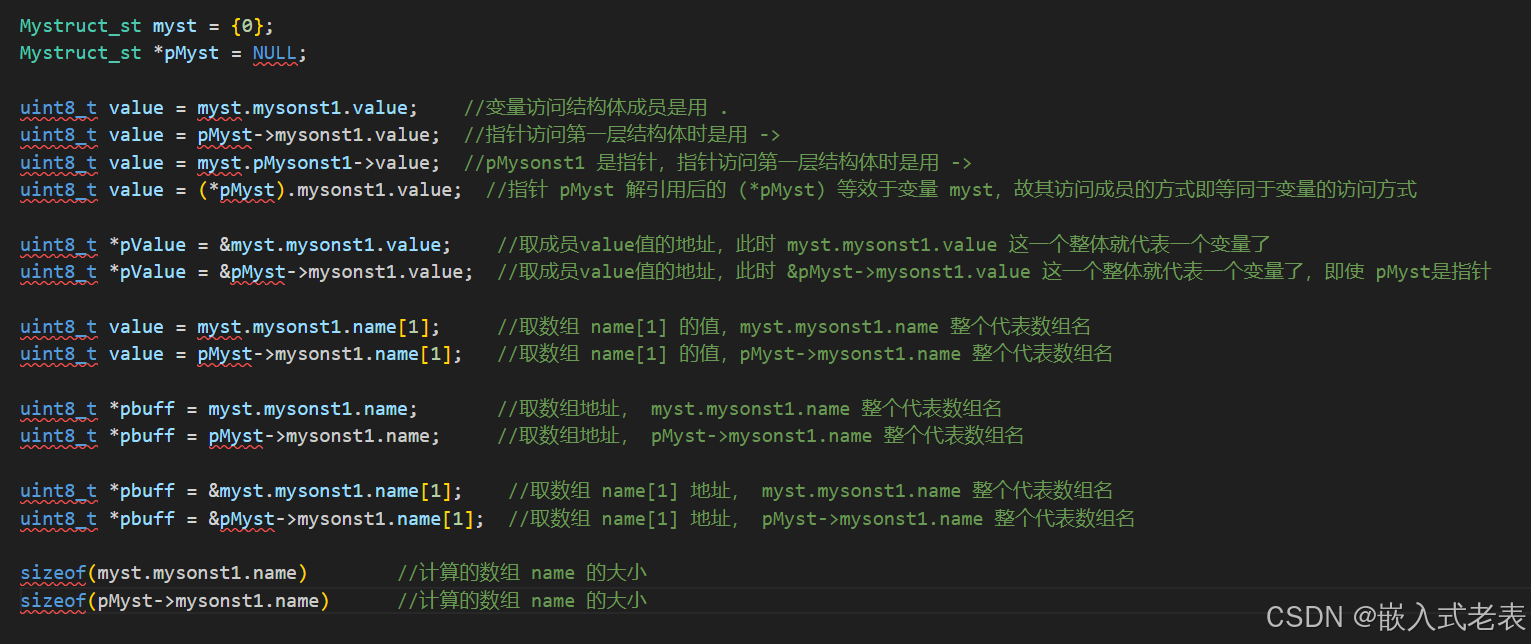
结构体成员的访问和最终表示,总体来说最终表示的是数组/变量/指针就看最后一个成员变量是什么类型的数据
tip8
注意 sizeof 宏定义的使用,sizeof 变量名、数组名、类型名返回的是占用的字节数

sizeof 地址、指针返回的是4个字节,即 int 类型

tip9
注意结构体类型,当不加 __attribute__((packed)),即按照编译器默认结构体对齐,也就是说当你使用这个结构体变量读到内存中时,编译器会自动补齐,即 sizeof(结构体类型/变量) >= 成员变量占用字节大小的累积和
其实,结构体类型的对齐方式是编译阶段就已经是确定了,其需填充字节数也确定了
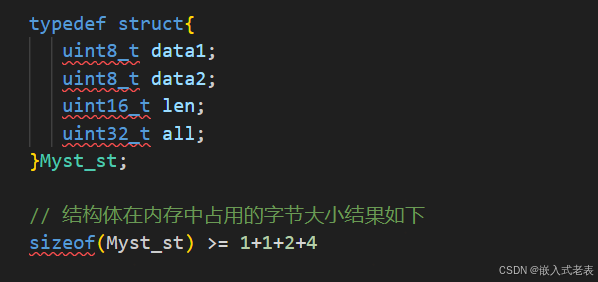
假如上述结构体类型在编译阶段按照 uint32_t 类型对齐,对齐结果如下,通常补齐的字节都是0x00
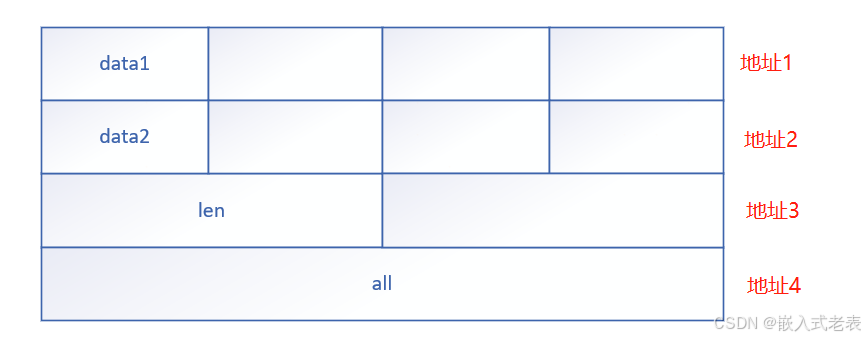
我的理解
由于结构体成员地址统一对齐后,其成员的访问方式通过地址偏移操作,大大提升了CPU的访问结构体成员的效率;当成员未对齐,即按照字节的偏移方式访问成员,一个字节一个字节的查询,故效率低下
tip10
取消结构体的默认对齐方式,通常两种
1、使用__attribute__((__packed__)),针对某个结构体,且只能按照1个字节对齐
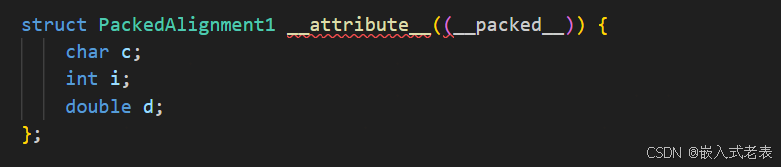
2、使用宏,针对多个结构体,且能按照1、2、4、8等字节对齐

tip11
inline函数,编译阶段在函数调用的地方,将函数内容展开,后续将不需要执行函数调用的开销,缺点是代码量增大
所以用法:函数内容少,一般几行的函数,可以使用内联函数,较少函数调用的开销,提高性能
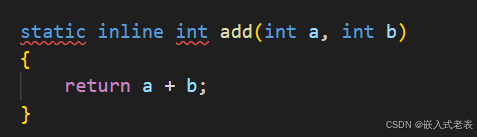
tip12 结构体和联合体
1、联合体的初始化
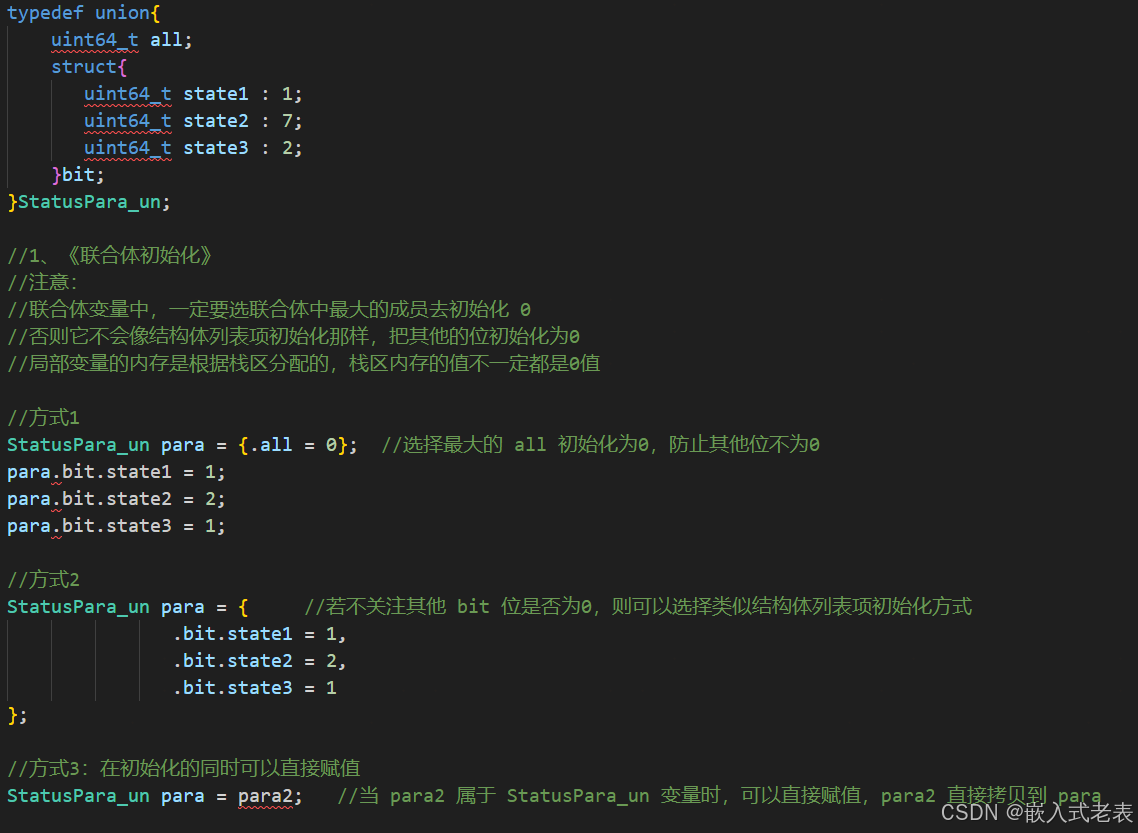
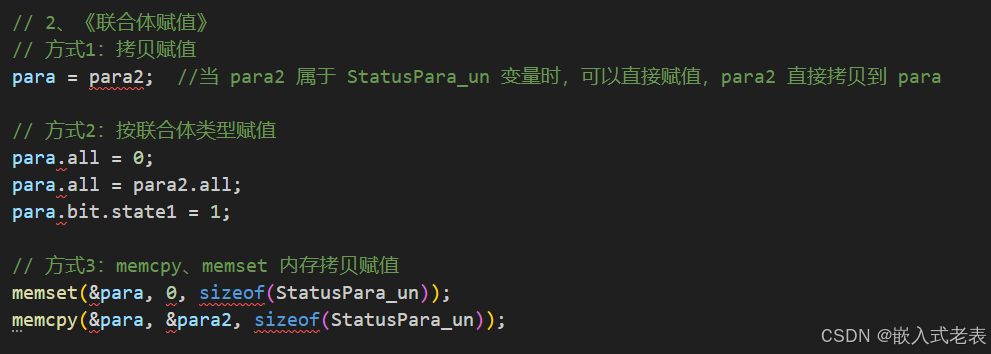
2、联合体的赋值
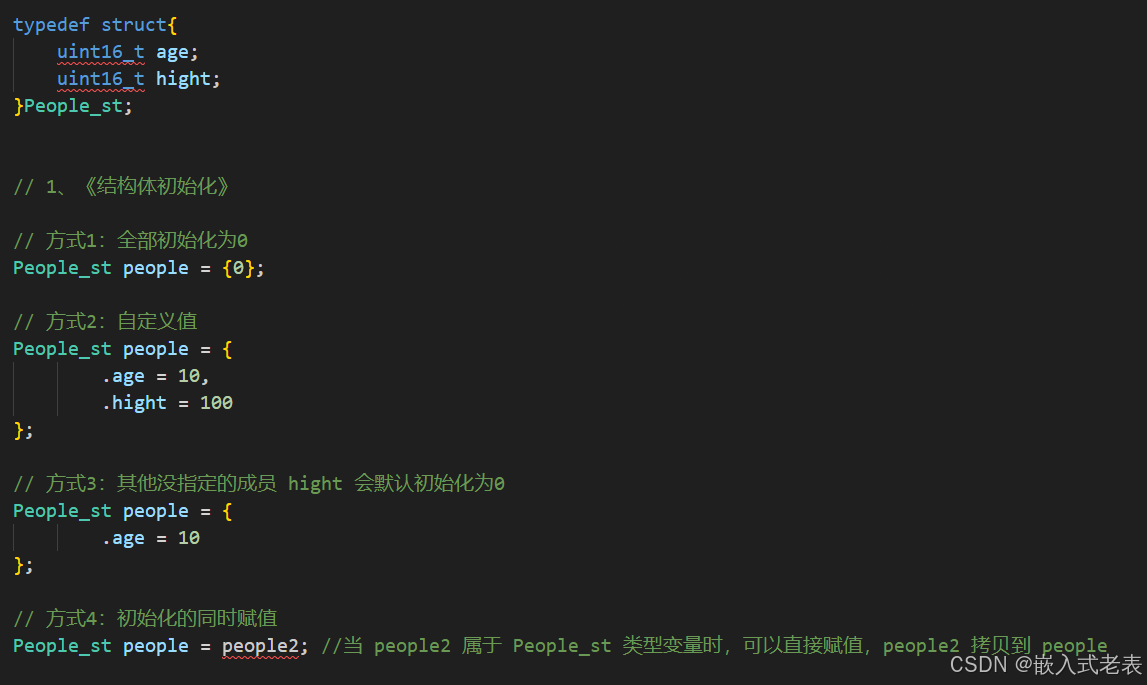
3、结构体的初始化
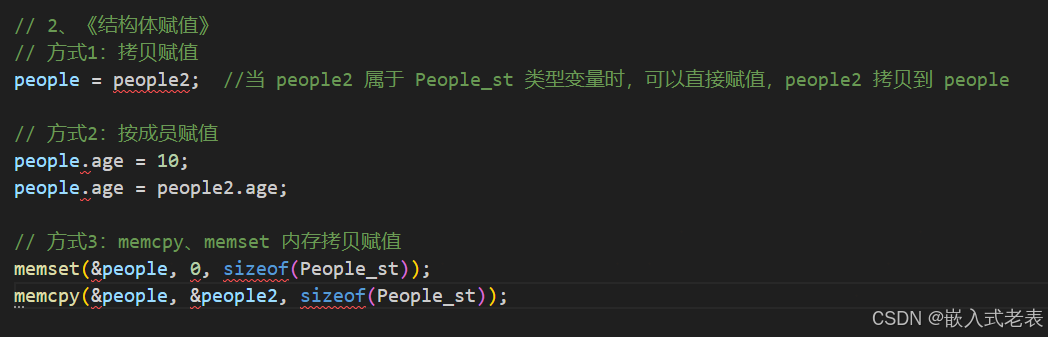
4、结构体的赋值

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









