




Linux应用层协议HTTP(二)
一、认识URL
1.URL基本了解
平时我们俗称的“网址”其实就是说的URL(统一资源定位符,它是URI(统一资源标识符)的一个子集,是URI概念的一种实现方式);IP+端口可以定位互联网上唯一一台主机,但如果我们还需要该主机上的资源文件,还要有路径。即我们通过IP+路径,就可以唯一地确认一个网络资源。
IP通常是以域名的方式呈现的,路径就是Linux主机上的目录,如下图所示:
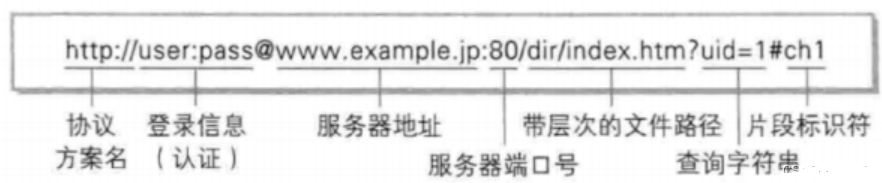
协议方案名:
http、https协议或其他
登录信息(认证):
指定用户名和密码作为服务器端获取资源时的必要信息,此项为可选项,浏览器显示时会隐藏
服务器地址:
访问服务器时必须指明服务器地址,上图给出的只是方便人们记忆的网址,实际会由DNS(域名解析器)进行解析
服务器端口号:
指定服务器连接的网络端口号,也是一个可选项,其中有些端口号非常有名,属于强绑定了,如果用户省略则会使用默认的端口号
带层次的文件路径:
指定服务器的文件路径来定位指定的资源。和UNIX系统目录结构类似,但这不是根目录,而是一个部署好的web根目录。(注意“?”号前面就是基本的URL格式,如果需要传入参数,在“?”号后面加入,以K-V形式传入)
查询字符串:
百度搜索时就按照这种方式传参(注意“?”号前面就是基本的url格式,如果需要传入参数,在“?”号后面加入,以K-V形式传入)查询字符串,百度搜索时就按照这种方式传参
2.urlencode和urldecode
如果在搜索关键字当中出现了像/? @这样的字符,由于这些字符已经被URL当作特殊意义理解了,因此URL在呈现时会对这些特殊字符进行转义。
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式

“+”被转义成了“%2B”

“?”被转义成了“%3F”
因此在编写服务器时,面对这些特殊字符,一定要做编码处理,下面是一个在线的编码/解码工具
[编码/转码工具](UrlEncode编码/UrlDecode解码 - 站长工具 (chinaz.com))
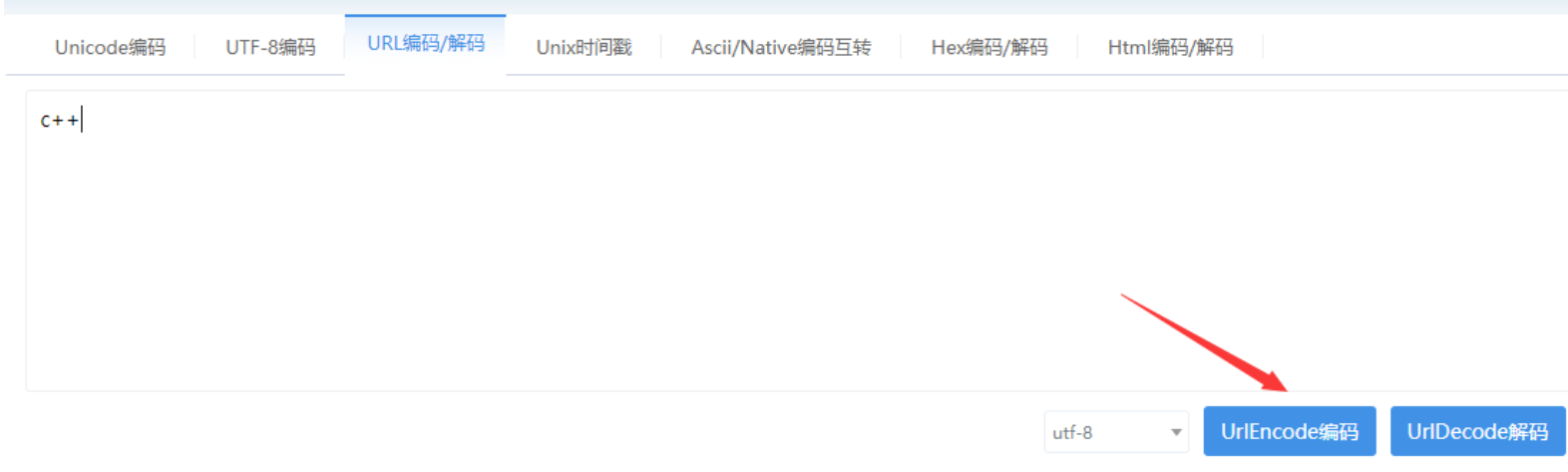
在输入C++后点击编码就能得到编码后的结果
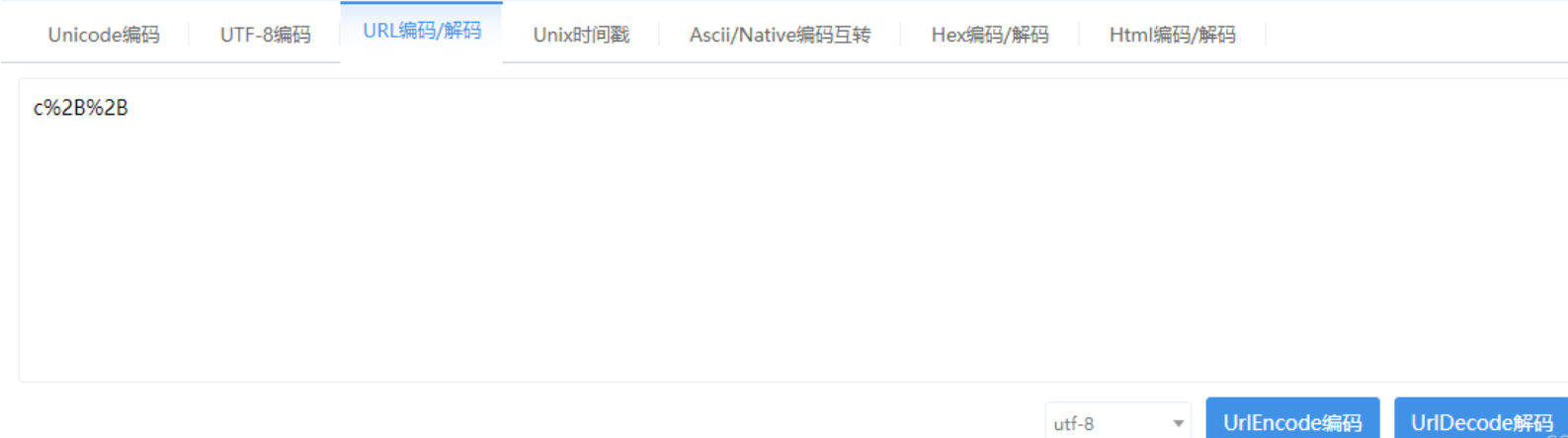
当服务器拿到对应的URL后,也需要对编码后的参数进行解码,此时服务器才能拿到你想要传递的参数,解码实际上就是编码的逆过程。(转义的过程称为 urlencode,其逆过程称为urldecode)
二、HTTP报文内的HTTP信息
1.HTTP报文
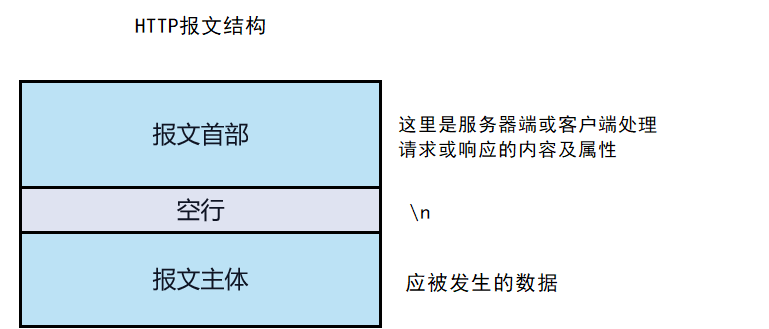
用于HTTP协议交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文本身是有多行数据构成的字符串文本;
HTTP报文大致可分为报文首部和报文主体两块。两者由空行来划分。通常,并不一定要有报文主体
2.请求报文和响应报文的结构
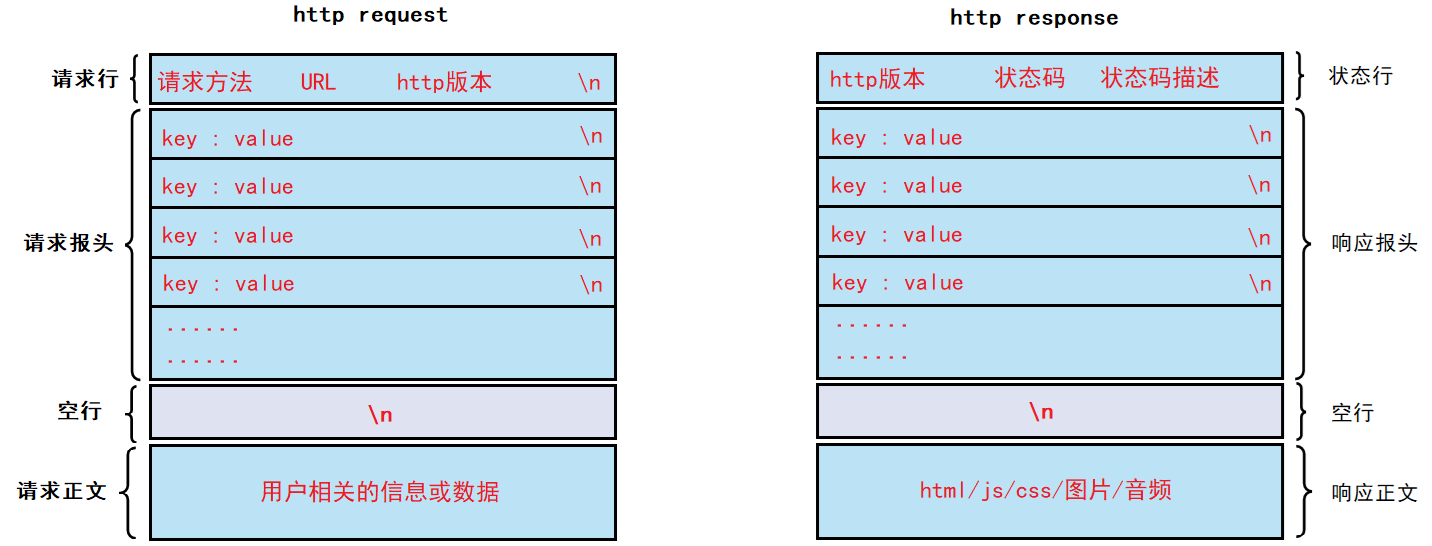
HTTP请求由以下四部分组成:
- 请求行:[请求方法]+[url]+[http版本]
- 请求报头:请求的属性,这些属性都是以key:value的形式按行陈列的。
- 空行:遇到空行表示请求报头结束。
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度。
如何将HTTP请求的报头与有效载荷进行分离?
当应用层受到一个HTTP请求时,它必须想办法将HTTP的报头与有效载荷进行分离。对于HTTP请求来讲,这里的请求行和请求报头就是HTTP的报头信息,而这里的请求正文实际就是HTTP的有效载荷。
我们可以根据HTTP请求当中的空行来进行分离,当服务器收到一个HTTP请求后,就可以按行进行读取,如果读取到空行则说明已经将报头读取完毕了,后面剩下的就是有效载荷了。
HTTP响应由以下四个部分组成:
- 状态行:[http版本]+[状态码]+[状态码描述]
- 响应报头:响应的属性,这些属性都是key:value的形式按行陈列的。
- 空行:遇到空行表示响应报头结束。
- 响应正文:响应正文允许为空字符串,如果响应正文存在,则响应报头中会有一个Content-Length属性来标识响应正文的长度。比如服务器返回了一个html页面,那么这个html页面的内容就是在响应正文当中的。
如何将HTTP响应的报头与有效载荷进行分离?
对于HTTP响应来讲,这里的状态行和响应报头就是HTTP的报头信息,而这里的响应正文实际就是HTTP的有效载荷。与HTTP请求相同,当应用层收到一个HTTP响应时,也是根据HTTP响应当中的空行来分离报头和有效载荷的。当客户端收到一个HTTP响应后,就可以按行进行读取,如果读取到空行则说明报头已经读取完毕。
1.构建http请求




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











