




Python的requests库实现微博评论爬取(保姆版+翻页爬取)
一、所使用的库
- requests:用于发送 HTTP 请求,获取网页数据 os:用于判断文件是否存在
- time / datetime:用于处理时间格式
- csv:将爬取的数据保存为 CSV 文件
二、第一步:分析微博评论页面
微博评论的接口url目前分为网页端和手机端,本次爬虫针对网页端。
1.如图在微博对应的话题下按F12打开控制台,之后刷新页面。
2.然后在左侧搜索框中随便搜索一个评论会发现在网页端中评论请求的url为https://www.weibo.com/ajax/statuses/buildComments?is_reload=1&id=5176024913414298&is_show_bulletin=2&is_mix=0&count=10&uid=1635717035&fetch_level=0&locale=zh-CN
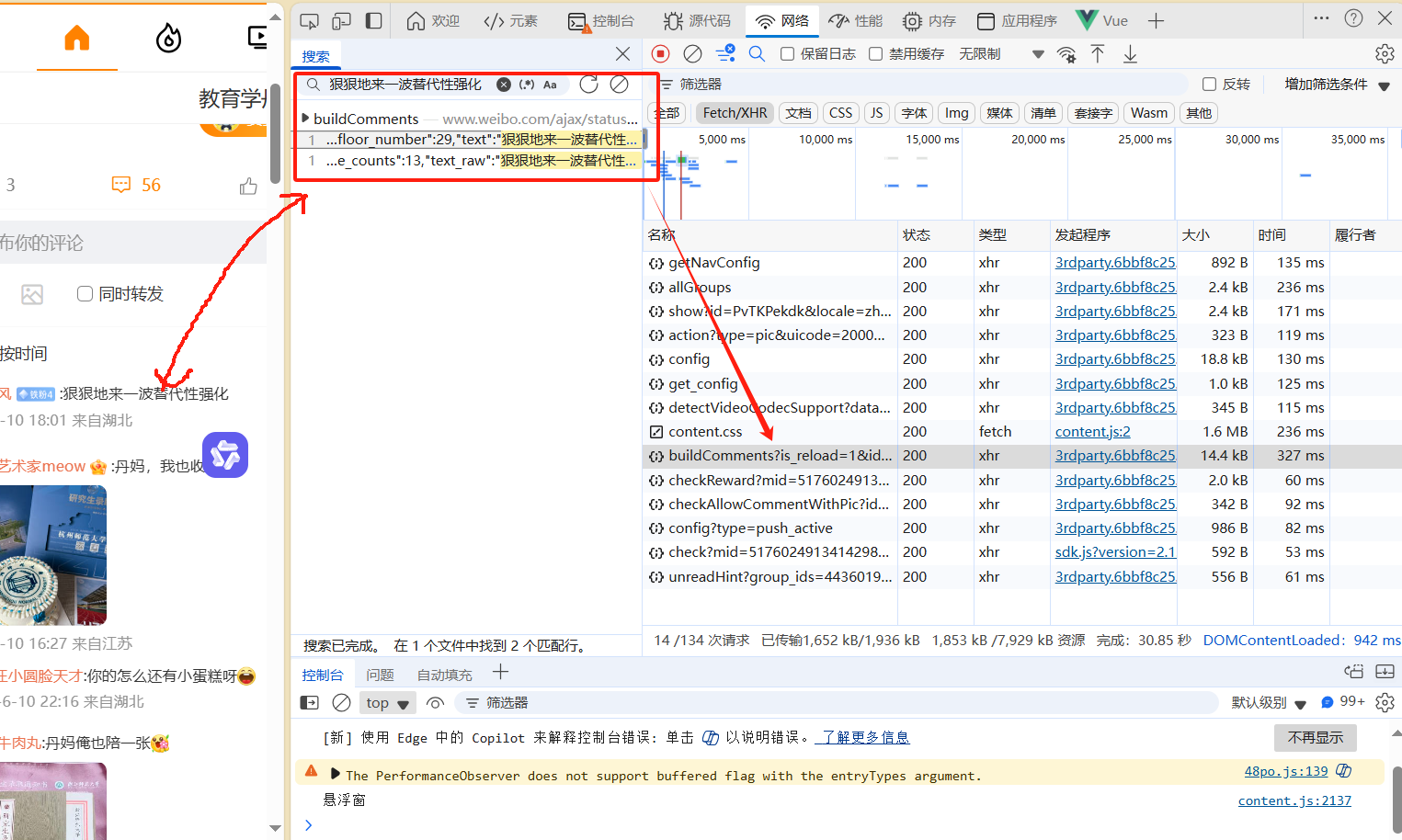
这里我们对里面的参数进行一个详细的解释:
| 参数名 | 类型 | 示例值 | 说明 |
|---|---|---|---|
is_reload | int | 1 | 是否是重新加载,1 表示是刷新或重新加载评论 |
id | str 或 int | '5033876047007372' | 要抓取评论的微博 ID(注意:不是用户 UID) |
is_show_bulletin | int | 2 | 是否显示公告类评论,2 可能表示不显示系统公告 |
is_mix | int | 0 | 是否混合热门评论,0 表示只按时间排序;1 表示包含热门评论 |
count | int | 20 | 每次请求获取的评论数量,这里是每次拉取 20 条 |
uid | str 或 int | '5067693780' | 微博作者的用户 ID(发布这条微博的人的 UID) |
fetch_level | int | 0 | 获取评论层级,0 表示一级评论(即主评论),1 可能是子评论 |
locale | str | 'zh-CN' | 语言区域设置,表示中文简体 |
三、第二步:开始第一次请求
到这里我们其实已经知道啦可以使用requests库来请求这个URL接口并加上对应的参数和标头就可以拿到评论数据啦,我们可以先进行一次尝试。
注意:这里要加上请求标头
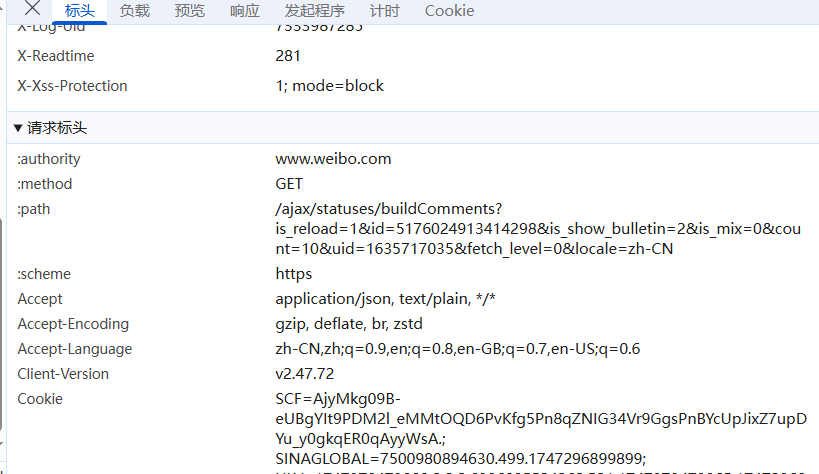
主要的请求标头(headers)是User-Agent、Cookie、referer这几个写你自己浏览器的,不要写我的。
代码如下:
import requests
def fetch_comments(max_id=0):
# 请求地址(微博评论接口)
url = 'https://weibo.com/ajax/statuses/buildComments'
# 请求参数(params)
params = {
'flow': 0, # 请求来源标识
'is_reload': 1, # 是否刷新
'id': id, # 微博ID(从用户输入获取)
'is_show_bulletin': 2, # 不显示系统公告
'is_mix': 0, # 不混合热门评论
'count': 20, # 每次请求20条评论
'uid': uid, # 微博作者UID
'fetch_level': 0, # 只获取主评论(一级评论)
'locale': 'zh-CN' # 中文界面
}
# 请求头(headers)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',
'Cookie': '你的Cookie', # 替换为你自己的 Cookie
'referer': 'https://weibo.com/6121016286/OedOYdmXR' # referer 来源页
}
# 发送GET请求
response = requests.get(url=url, headers=headers, params=params)
# 将响应转为JSON格式
data = response.json()
正如我们想象的一样,正确返回啦第一页的评论数据。

四、第三步:翻页的实现
我们开始实现翻页,此时我们尝试下拉评论,在刷新一些评论出来,再次观察新 刷新出来的URL接口。
第一次刷新出来的url
https://www.weibo.com/ajax/statuses/buildComments?is_reload=1&id=5176024913414298&is_show_bulletin=2&is_mix=0&count=10&uid=1635717035&fetch_level=0&locale=zh-CN
第二次刷新出来的url
https://www.weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=5176024913414298&is_show_bulletin=2&is_mix=0&max_id=138884522131048&count=20&uid=1635717035&fetch_level=0&locale=zh-CN
对比你会发现里面多啦个max_id=138884522131048这max_id哪里来的呢?
实际上微博评论采用的是分页加载的方式,每次请求返回一个 max_id,下一次请求带上这个 max_id 即可获取更早的评论。
查看第一次的这个URL接口的响应数据发现里面有个max_id并且和第二次请求的max_id一样。
这是第一次的响应图
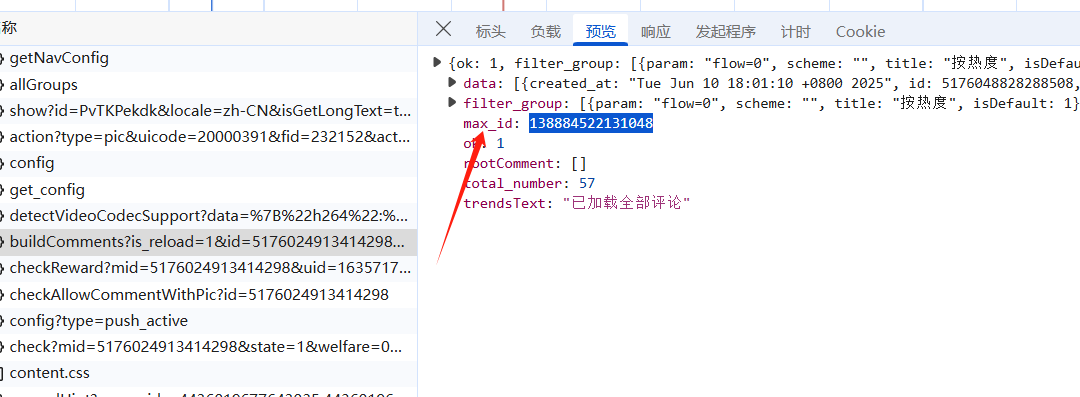
接下来我们使用 requests.get() 向上述 URL 发送请求,携带必要的参数和 headers,即可获取评论数据。
import requests
def fetch_comments(max_id=0):
# 请求地址(微博评论接口)
url = 'https://weibo.com/ajax/statuses/buildComments'
# 请求参数(params)
params = {
'flow': 0, # 请求来源标识
'is_reload': 1, # 是否刷新
'id': id, # 微博ID(从用户输入获取)
'is_show_bulletin': 2, # 不显示系统公告
'is_mix': 0, # 不混合热门评论
'count': 20, # 每次请求20条评论
'uid': uid, # 微博作者UID
'fetch_level': 0, # 只获取主评论(一级评论)
'locale': 'zh-CN' # 中文界面
}
# 如果有max_id,则加入请求参数中,用于分页
if max_id:
params['max_id'] = max_id
# 请求头(headers)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36',
'Cookie': '你的Cookie', # 替换为你自己的 Cookie
'referer': 'https://weibo.com/6121016286/OedOYdmXR' # referer 来源页
}
# 发送GET请求
response = requests.get(url=url, headers=headers, params=params)
# 将响应转为JSON格式
data = response.json()
# 递归调用,实现翻页爬取
try:
if data.get('max_id'):
fetch_comments(max_id=data['max_id']) # 使用新的max_id继续爬取
else:
print("已抓取全部评论")
except Exception as e:
print(f"爬取评论异常,稍后重试!错误信息:{e}")
翻页逻辑总结:
- 第一次请求没有 max_id,从最新评论开始;
- 每次响应中会返回一个 max_id;
- 下次请求时带上这个 max_id,获取更早的评论;
- 当不再返回 max_id 时,表示已加载完所有评论。
五、保存数据到csv
具体方法如下:
def save_to_csv(comments, filename):
newfilename = filename + '.csv'
# 提取评论字段
screen_name = comments['user']['screen_name']
text_raw = comments['text_raw']
created_at = format_weibo_time(comments['created_at'])
location = comments['user']['location']
avatar_hd = comments['user']['avatar_hd']
description = comments['user']['description']
# 构造字典
dictionary = {
'评论时间': created_at,
'昵称': screen_name,
'评论内容': text_raw,
'评论用户城市': location,
'用户头像': avatar_hd,
'评论用户签名': description
}
# 判断是否是第一次写入
file_exists = os.path.isfile(newfilename) and os.path.getsize(newfilename) > 0
# 写入CSV
with open(newfilename, 'a', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=dictionary.keys())
if not file_exists:
writer.writeheader() # 第一次写入时添加表头
writer.writerow(dictionary)
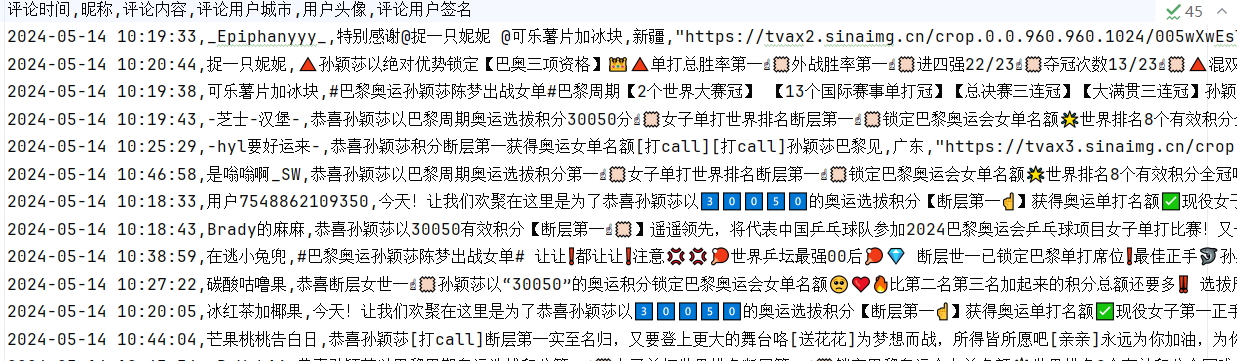
最后的数据结果图:


















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









