








🌟 1. 什么是 Pattern Recognition(模式识别)?
模式识别是一门研究如何使计算机或系统能够自动识别各种数据模式(如图像、语音、文本、传感器信号等)的技术和科学。它广泛应用于人脸识别、语音识别、指纹识别、文本分类、医学图像诊断等领域。
-
目的: 根据输入数据的特征,对其进行分类或识别。
-
输入: 数据样本(可能是图像、声音、信号等),表示为向量形式。
-
输出: 分类标签(如“猫”或“狗”)、分数、概率等。
📌 举个例子:
给定一张图片,系统要判断它是猫还是狗。图像的像素就是特征,通过算法分析这些像素的模式,来做出分类。
🌟 2. 特征空间(Feature Space)
-
模式识别的基本单位是一个“样本向量”,也叫做 feature vector。
-
如果你用 ddd 个特征来描述一个对象,那么这个对象就可以看作在一个 ddd-维空间里的一个点,这个空间称为 特征空间。
🧠 通俗解释:
假设你在挑水果,只看“重量”和“甜度”两个属性,那么每个水果就可以用一个 (重量, 甜度) 的坐标来表示。所有水果的坐标构成的二维平面,就是“特征空间”。
🌟 3. 模式识别流程(Pipeline)
-
数据采集(Data Acquisition)
-
从传感器、图像、音频等获取原始数据。
-
例如使用摄像头获取一张图片,或用麦克风采集声音。
-
-
预处理(Pre-processing)
-
去噪声、标准化、归一化、滤波、裁剪等。
-
目的是提升数据质量,减少后续分析难度。
-
-
特征提取(Feature Extraction)
-
将原始数据转换为具有代表性的数值向量。
-
比如将图像中的边缘、颜色、纹理等提取出来作为特征。
-
-
分类器设计(Classifier Design)
-
使用数学模型对提取的特征向量进行分类。
-
例如:KNN、决策树、SVM、神经网络等。
-
-
评估与验证(Evaluation)
-
使用准确率(accuracy)、召回率(recall)、F1-score 等指标评估模型表现。
-
🔧 专业术语补充:
-
Feature Vector(特征向量):表示一个样本的数据结构,如 [x1,x2,...,xd]。
-
Label(标签):样本对应的类别,如“人脸”或“不是人脸”。
-
Classifier(分类器):一个算法,用于将样本映射到具体的类别上。
🌟 4. 分类器(Classifiers)
分类器的作用: 输入一个特征向量,输出一个类别。
1️⃣ 最近邻分类器(Nearest Neighbour, NN)
-
原理: 对一个待分类的样本,找到距离它最近的已知样本,把这个样本的类别作为预测结果。
-
距离度量: 一般使用欧几里得距离(Euclidean Distance):
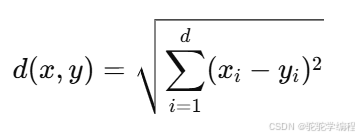
🧠 通俗理解:
想象你在街上看到一个陌生人,你会判断他是哪个国家的人。你可能会看看他穿的衣服、说话口音……然后你想,“哦,这和我一个美国朋友很像”,于是你猜他是美国人。这就是最近邻的思想。
2️⃣ K近邻(K-Nearest Neighbours, KNN)
-
找到与测试样本距离最近的 K 个邻居,根据这些邻居的多数类别来进行预测。
-
可以理解为“投票表决”机制。
📌 K 值的选择:
-
太小容易受噪声影响(欠拟合),太大可能跨类别(过拟合)。
-
通常使用交叉验证(cross-validation)选择最佳的 K 值。
🌟 5. 距离度量方法(Distance Metrics)
-
欧几里得距离(Euclidean):最常用,适用于连续型数据。
-
曼哈顿距离(Manhattan):
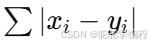
-
切比雪夫距离(Chebyshev):最大坐标差值。
-
马氏距离(Mahalanobis):考虑了特征之间的相关性,适用于协方差不同的情形。
🌟 6. 分类性能评估(Performance Evaluation)
📊 混淆矩阵(Confusion Matrix)
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | TP | FN |
| Actual Negative | FP | TN |

TP / TN / FP / FN 的含义详解:
| 实际值 / 预测值 | 预测为正类(Positive) | 预测为负类(Negative) |
|---|---|---|
| 实际为正类(Positive) | ✅ TP(True Positive) | ❌ FN(False Negative) |
| 实际为负类(Negative) | ❌ FP(False Positive) | ✅ TN(True Negative) |
🔹 True Positive(TP,真正例)
-
实际是正类,模型也正确地预测为正类。
-
✔️ 正确识别出来的“好人”、”猫”、”癌症患者“。
例子:图像识别中,一张猫的照片被正确预测为“猫”。
🔹 True Negative(TN,真负例)
-
实际是负类,模型也正确地预测为负类。
-
✔️ 正确识别出来的“不是猫”的图片。
例子:一张狗的照片被正确识别为“不是猫”。
🔹 False Positive(FP,假正例)
-
实际是负类,模型却预测为正类。
-
❌ 错误地把负类当成了正类。
例子:把一张狗的照片误判成了“猫”。
也叫 Type I error(第一类错误)
🔹 False Negative(FN,假负例)
-
实际是正类,模型却预测为负类。
-
❌ 错误地漏掉了正类。
例子:一张猫的照片被误判成了“不是猫”。
也叫 Type II error(第二类错误)
🧠 一句话总结:
| 缩写 | 全称 | 实际类别 | 预测类别 | 举例 |
|---|---|---|---|---|
| TP | True Positive | 正 | 正 | 猫被识别为猫 |
| TN | True Negative | 负 | 负 | 狗被识别为不是猫 |
| FP | False Positive | 负 | 正 | 狗被识别为猫 |
| FN | False Negative | 正 | 负 | 猫被识别为不是猫 |
🧠 通俗理解:
精确率是“猜中为正的人中,有多少是真的”;召回率是“真正的正例中,你找到了多少”。
🌟 7. 其他重要概念
1️⃣ 决策边界(Decision Boundary)
-
分类器在特征空间中划分不同类别区域的“分界线”。
-
如 KNN 就会形成一种“块状”的边界,SVM 会形成平滑的超平面。
2️⃣ 过拟合与欠拟合
-
过拟合(Overfitting): 模型对训练数据学得太好,导致泛化能力差。
-
欠拟合(Underfitting): 模型太简单,无法捕捉数据中的规律。
3️⃣ 特征选择(Feature Selection)
-
不是所有特征都对分类有帮助,选择最具代表性的子集能提升性能。
8.例题

Question:
Which one of the following statements is correct for random forest classifiers?哪个关于随机森林分类器的说法是正确的?
选项 A
❌ 英文:Increasing the correlation between the individual trees decreases the random forest classification error rate.
中文:增加各棵树之间的相关性会降低分类错误率。
解析:
这是错误的。
在随机森林中,我们希望不同的决策树之间尽量不“相似”(即低相关性),这样当有些树犯错时,其他树可以“纠正”它的错误。
树之间越不相关(越多样化),整体分类性能越强。
选项 B
❌ 英文:Reducing the number of selected features at each node increases the correlation between the individual trees.
中文:在每个节点减少选中的特征数会增加树之间的相关性。
解析:
也是错误的。
我们随机地减少每个节点可以选择的特征数(比如从总特征中随机选√d个),这样每棵树看到的数据就不同,从而减少树之间的相关性,提高集成能力。
选项 C
❌ 英文:Reducing the number of selected features at each node increases the strength of the individual trees.
中文:减少节点中可选特征的数量能增强单棵树的强度。
解析:
错。
如果每个节点可用的特征太少,那么每棵树可能就很“弱”,因为它做决策时选不到重要的特征。
树的强度降低,性能反而变差。
✅ 选项 D
✔️ 英文:Increasing the strength of the individual trees decreases the random forest classification error rate.
中文:增强单棵树的能力会降低整个森林的分类误差。
解析:
这是正确的。
随机森林的整体性能由两点决定:
每棵树的强度(strength)
树与树之间的相关性(correlation)
如果树更强,而且它们的预测不太一样(不相关),那么投票的结果就更稳健,错误率就更低。

Question:
Which one of the following statements is correct for pattern recognition?哪个是关于模式识别(Pattern Recognition)的正确说法?
选项 A
❌ 英文:Pattern recognition is defined as the process of model training on a training dataset and then testing on an independent test set.
中文:模式识别是指在训练集上训练模型并在测试集上进行测试的过程。
解析:
虽然这句话描述了监督学习的过程,但不是模式识别的完整定义。
Pattern Recognition 更广义,它包括无监督学习、特征提取、聚类、降维等,不是仅限于训练与测试数据的划分。
选项 B
❌ 英文:The dimension of feature vectors should be smaller than the number of training samples in order to avoid the overfitting problem.
中文:为了避免过拟合,特征向量的维度应该小于样本数量。
解析:
有道理,但不是绝对的真理。
确实,在特征维度 >> 样本数量时容易过拟合(维度灾难),但我们也可以用正则化、PCA等手段缓解,所以这句话不是严格正确。
✅ 选项 C
✔️ 英文:The simple kNN classifier needs homogeneous feature types and scales so that the classification performance can be better.
中文:kNN分类器需要特征在相似的类型和尺度上,这样分类效果才好。
解析:
完全正确!
kNN 的核心是计算距离(通常是欧氏距离),如果有一个特征范围是 01,另一个是 010000,那么后者会主导距离计算,导致分类失效。
所以需要特征归一化(normalization)或标准化(standardization)。
选项 D
❌ 英文:SVM is a powerful classifier that can separate classes even when the feature space exhibits significant overlaps between classes.
中文:SVM 是一个强大的分类器,即使在特征空间中类别严重重叠也能分离它们。
解析:
这句话太夸张了。
SVM 的确强大,特别是配合核函数(kernel trick)时,但如果两个类别真的完全重叠,它也无能为力。
所以这句话不严谨。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









