






 该文介绍了如何利用LSTM神经网络对周期为12的三角函数序列进行训练和预测。通过前1000组数据训练,2001组数据测试,设置单层LSTM网络,神经元数量为8,并应用ReduceLROnPlateau和EarlyStopping优化器。训练完成后,模型保存为test.h5,并对测试集进行预测,最后对比真实值与预测值,评估模型性能。
该文介绍了如何利用LSTM神经网络对周期为12的三角函数序列进行训练和预测。通过前1000组数据训练,2001组数据测试,设置单层LSTM网络,神经元数量为8,并应用ReduceLROnPlateau和EarlyStopping优化器。训练完成后,模型保存为test.h5,并对测试集进行预测,最后对比真实值与预测值,评估模型性能。
一,三角函数构建
;周期为12,x取值范围为[0,3000],并获得对应的y。利用前1000组数据来训练,后2001组进行测试。训练过程是利用前3个数来预测第四个数。
二、LSTM神经网络训练
由于实验是单步预测,网络层数选择一层即可,网络层神经元个数为8。(神经元个数,网络层数,输入个数等都可以通过实验来比较确定最优个数)另外,使用了ReduceLROnPlatateau和EarlyStopping来使得训练自动调整学习率并自动停止训练。
代码如下:
import numpy as np
import math
import matplotlib.pyplot as plt
import tensorflow as tf
from keras.callbacks import ReduceLROnPlateau,EarlyStopping
#利用LSTM对数据进行训练
def pointlstm(data,trainlen,inputnum,neunum,layers,savename):
#data是数据集,trainlen是根据数据集划分的训练集长度,inputnum是网络输入个数
#neunum是神经元个数,laysers是隐藏层层数
##################################################################
#划分数据集
global model
def dataclass(dataset,start_index,end_index,history_size,target_size):
before_data=[]
predict_data=[]
for i in range(start_index,end_index-pastlen):
indeices=range(i,history_size+i)
before_data.append(np.reshape(dataset[indeices],(history_size,1)))
predict_data.append(dataset[i+history_size+target_size-1])
return np.array(before_data),np.array(predict_data)
##################################################################
predictlen=1
pastlen=inputnum
##################################################################
#数据标准化
data_mean=data[:trainlen].mean()
data_std=data[:trainlen].std()
data=(data-data_mean)/data_std
##################################################################
x_train,y_train=dataclass(data,0,trainlen,pastlen,predictlen) #数据集划分
BATCH_SIZE=64
BUFFER_SIZE=100
Epochs=300
traindata=tf.data.Dataset.from_tensor_slices((x_train,y_train))
traindata=traindata.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE) #批量并打乱
################################################################## #训练
model=tf.keras.models.Sequential([
tf.keras.layers.LSTM(units=neunum,input_shape=x_train.shape[-2:],activation='tanh'),
#重复几次代表几个隐藏层
tf.keras.layers.Dense(1) #全连接层
])
model.compile(optimizer='adam',loss='mae')
model.summary() #输出网络结构参数
#当损失函数连续5次不减小,降低一次学习率
reduce_lr=ReduceLROnPlateau(monitor='loss',facter=0.5,patience=5,min_lr=0.00001)
#当损失函数连续10次不减小,停止
early_stop=EarlyStopping(monitor='loss',patience=10,mode='min')
history=model.fit(traindata,batch_size=BATCH_SIZE,callbacks=[reduce_lr,early_stop],
epochs=Epochs)
model.save(savename)
#绘制损失函数曲线
def drawloss(data):
fig=plt.figure(figsize=(10,8))
plt.plot(data)
plt.savefig('figout.png')
drawloss(history.history['loss'])
if __name__ == "__main__":
x=np.arange(3001)
print(x)
y=np.sin(math.pi/6*x)+np.sin(math.pi/3*x)
print(y)
savename='test'+'.h5'
pointlstm(y,1000,3,8,1,savename)
将训练好的模型保存为test.h5,绘制的损失函数图如下:
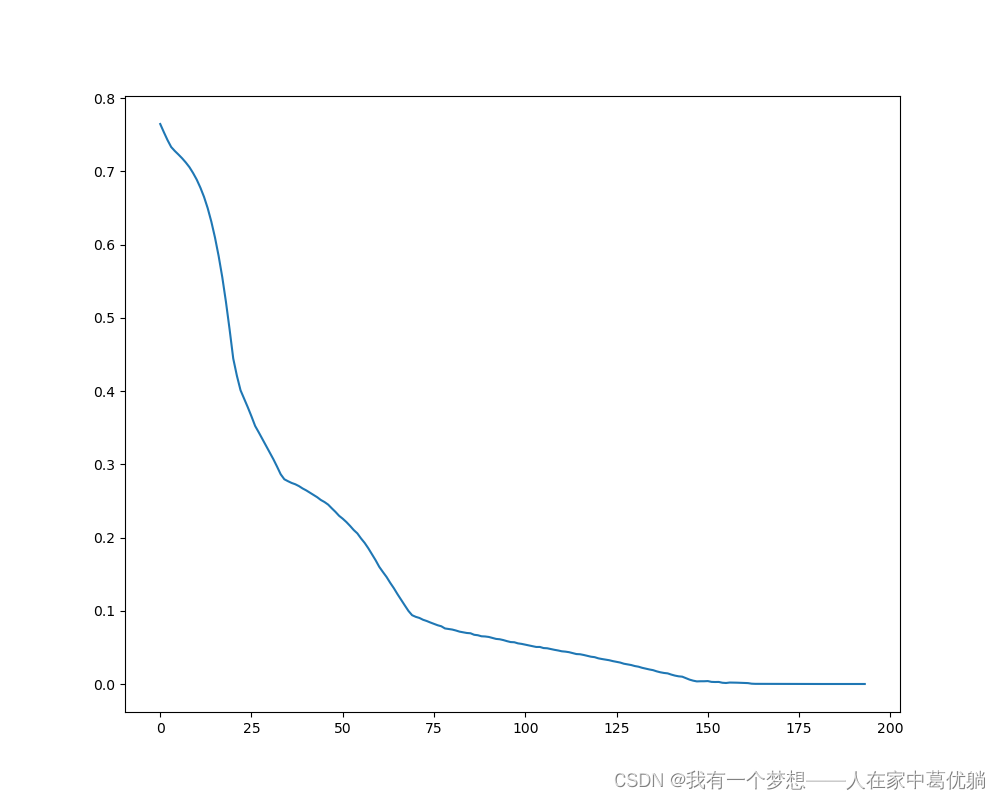
三、利用训练好的模型进行预报测试实验
import numpy as np
import math
import matplotlib.pyplot as plt
from keras.models import load_model
def drawphotos(x1,x2,data1,data2,name):
fig=plt.figure(figsize=(20,10))
ax=fig.add_subplot(1,1,1)
plt.plot(x1,data1,c='k',label='True',lw=2)
plt.plot(x2,data2,'.r',marker='x',markersize=8,label='Pre')
plt.xlim(min(x1),max(x1))
plt.legend(loc='upper right',fontsize=20)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
plt.title(np.mean(abs(y_pre[2000:2100]-y[2000+3:2100+3])),fontsize=20)
plt.tight_layout()
plt.savefig(name,bbox_inches='tight',pad_inches=1)
#构建sin函数,并标准化
x=np.arange(3001)
print(x)
y=np.sin(math.pi/6*x)+np.sin(math.pi/3*x)
y_mean=y.mean()
y_std=y.std()
y_in=(y-y_mean)/y_std
print(y)
#导入训练好的模型
model=load_model('test.h5')
#根据sin的因变量构建需要的数据集
data_in=[]
for j in range(len(x)-3+1):
indices=range(j,j+3)
data_in.append(np.reshape(y_in[indices],(3,1)))
data_in=np.array(data_in)
print(data_in)
#预报数据
y_out=model.predict(data_in)
y_pre=y_out*y_std+y_mean
y_pre=y_pre.flatten()
y_pre=list(y_pre)
print(len(y_pre))
#画图
drawphotos(x[2000:2100],x[3+2000:2100+3],y[2000:2100],y_pre[2000:2100],'a.png')
当利用预报的数据和原始数据进行绘图比较时,3000组数据太多,因此只选取了测试集100组数据进行绘图检验,并统计绝均差。结果如图所示:
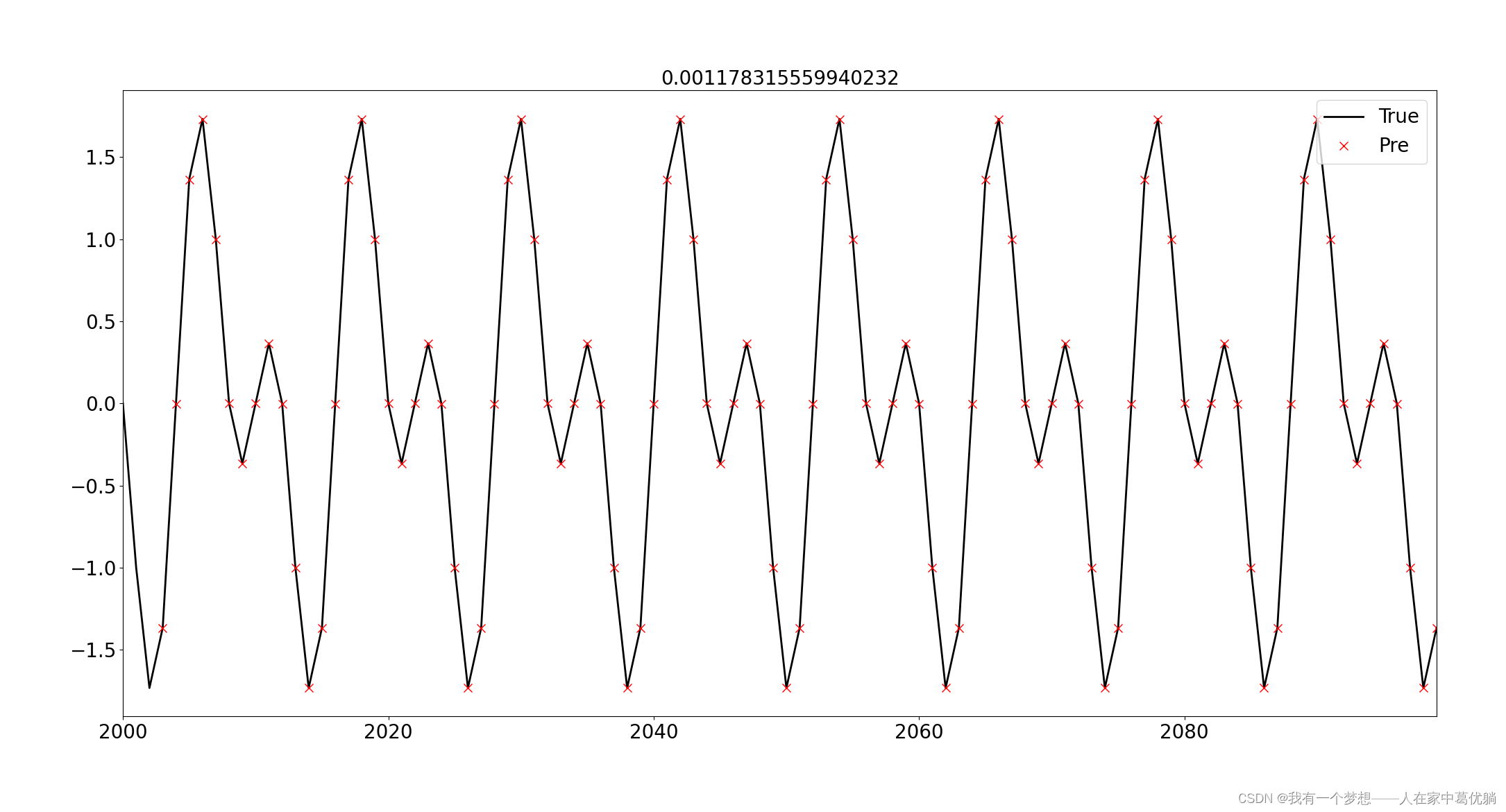
黑色实线表示真实数据,红色×表示LSTM预报结果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









