






linux—001入门
-
IT圈必备(前端工作者用的比较少)
-
老旧电脑跑linux不容易卡
-
我代码没保存windows闪退,僵停(vs2019卡掉线),重启更新,占用cpu内存服务报错pip各种bug 出来生态环境友好其他的全是bug(bug时间成本超过了windows快捷友好生态) 那就说明windows已经没有存在的意义了 买苹果或者去换linux是更好的选择
-
安全性高
-
- 大量的可用软件及免费软件
- 良好的可移植性及灵活性
- 优良的稳定性和安全性
- 支持几乎所有的网络协议及开发语言
-
系统选择
-
redhat
- redhat公司收费版
- centos和其他开源版本组成
-
linux/unix/arch
- 原生内核
-
debain
-
ubuntu/kali
-
deppin(兼容很多windows软件)
-
centos/redhat
- 入门学习
- 大多数常规主流服务器的选择
- 更新缓慢但是极为稳定
-
ubuntu
- 拥有较多的网络服务
- debain系拥有较好的桌面生态环境
- debain包相对多了很多拥有良好的包管理
- 对日常软件的兼容(deb)
-
kali
- 拥有大量网络安全工具
- 同时自带了debain大多数常用的依赖关系
-
用户比例
- 根据Stack Overflow的开发者调查报告,2022年将Linux作为主要操作系统的比例达到了40.23%,而macOS的比例为31.07% cloud.tencent.com。虽然这个数据是2022年的,但我们可以大致推测,2023年的比例可能会有所增长,但应该不会有太大的变动。
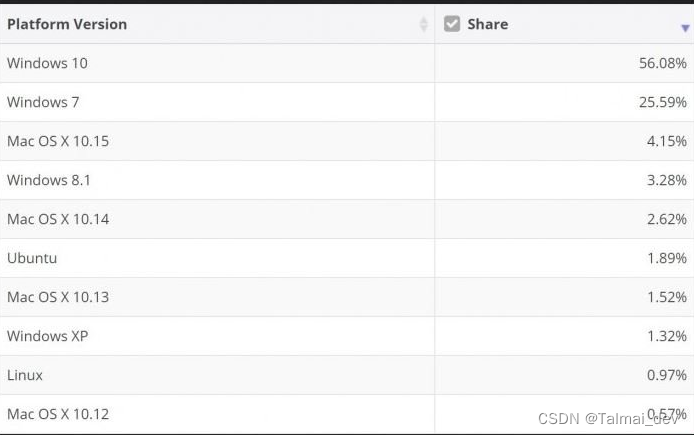
- 另外,Statcounter的数据显示,Linux的市场份额为2.76%,macOS为14.51%,Windows为75.21% zhuanlan.zhihu.com。这个数据可能更能反映出整体的用户比例,因为它包括了所有的桌面操作系统用户,不仅仅是开发者。
- 在游戏平台Steam上,Linux用户占比1.44%,而Windows用户占比为96.11% cloud.tencent.com。这个数据显示,在游戏用户中,Windows的占比依然非常高。
linux—002基础命令
# pm命令用于管理软件。rpm原本是 Red Hat Linux 发行版专门用来管理 Linux 各项套件的程序,由于它遵循 GPL 规则且功能强大方便,因而广受欢迎。逐渐受到其他发行版的采用。RPM 套件管理方式的出现,让 Linux 易于安装,升级,间接提升了 Linux 的适用度。能被rpm命令安装的软件包一般以.rpm为文件后缀。
rpm -ivh [package_name] #安装软件包
rpm -evh [package_name] #卸载软件
rpm -qlp *.rpm #列出rpm包的内容
rpm -qa |grep [字符串] #在已安装的所有软件中查询包含某字符串的软件版本
rpm -ql [软件名] #列出该软件所有文件与目录所在的完整文件名
rpm -qc [软件名] #列出软件的所有设置文件
rpm -qR [软件名] #查询某软件依赖的其他软件
rpm -qf [文件名] #查询文件属于哪个软件包
# yum命令是一个在 Fedora 和 RedHat 以及 SUSE 中的 Shell 前端软件包管理器。
# 基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令。
# 国内源
# 1备份配置文件
cd /etc/yum.repos.d
7z a Centos-Base.repo.7z Centos-Base.repo
# 删
rm Centos-Base.repo
# 下载源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
# 清理缓存
yum clean all
# yum命令
yum makecache #更新源(安装新源后执行)
yum clean all #清除缓存目录(/var/cache/yum)下的软件包及旧的headers
yum list |grep #显示所有已经安装和可以安装的程序包
yum info [package-name] #显示安装包信息
yum -y install [package-name] #安装软件,默认选yes
yum remove [package-name] #卸载
yum deplist rpm #查看程序rpm依赖情况
yum update #更新全部软件包
yum group list #列出组
yum group install "Security Tools" #安装‘Security Tools’软件组
yum search #检索安装包
#DNF是新一代的rpm软件包管理器。它正在逐步取代yum命令。
dnf repolist #该命令用于显示系统中可用的 DNF 软件库
dnf repolist all #该命令用于显示系统中可用和不可用的所有的 DNF 软件库
dnf list #用户系统上的所有来自软件库的可用软件包和所有已经安装在系统上的软件包
dnf list installed #该命令用于列出所有安装了的 RPM 包
dnf list available #用于列出来自所有可用软件库的可供安装的软件包
dnf search [pakage] #用该命令来搜索软件包
dnf provides /bin/bash #查找某一文件的提供者
dnf info nano #查看软件包详情
dnf install [pakage] #安装软件包
dnf update systemd #该命令用于升级指定软件包
dnf check-update #该命令用于检查系统中所有软件包的更新
dnf update #该命令用于升级系统中所有有可用升级的软件包
dnf remove [pakage] #删除系统中指定的软件包
dnf autoremove #删除无用孤立的软件包
dnf clean all #删除缓存的无用软件包
dnf history #查看您系统上 DNF 命令的执行历史
dnf grouplist #该命令用于列出所有的软件包组
dnf groupinstall ‘Educational Software’ #该命令用于安装一个软件包组
dnf groupupdate ‘Educational Software’ #升级一个软件包组中的软件包
dnf groupremove ‘Educational Software’ #该命令用于删除一个软件包组
dnf reinstall [pakage] #该命令用于重新安装特定软件包
- echo
## >指令覆盖文件原内容并重新输入内容,若文件不存在则创建文件。
```bash
#!/bin/bash
echo "Raspberry" > test.txt
#>>指令向文件追加内容,原内容将保存。
echo "Raspberry" > test.txt
echo "Intel Galileo" >> test.txt
#操作使用变量
#!/bin/bash
FILE="test-json.txt"
echo -e "{" > $FILE
echo -e "\t\"name\":\"xukai871105\"" >> $FILE
echo -e "}" >> $FILE
# 进阶:操作脚本
#!/bin/sh
function ergodic(){
for fileName in ` ls $1 `
do
if [ -d $1"/"$fileName ]
then
ergodic $1"/"$fileName
else
# echo $fileName
if [[ ${fileName} == 'start-service.sh' ]];
then
# echo `pwd`/$fileName
echo $1/$fileName
sh $1/start-service.sh start $1 &
fi
fi
done
}
INIT_PATH="/data/saleserver/startup"
ergodic $INIT_PATH
linux—003极限压缩
sudo 7za a -t7z -m0=lzma -mx=9 -mfb=64 -md=32m -ms=200m -mf -mhc -mhcf yourfile.7z ./yourfile.dmp &
#-t7z指定压缩格式为7z,-m0=lzma2指定压缩方法为LZMA2,-mx=9指定压缩等级为9,-mfb=64指定字典大小为64MB,-md=32m指定固实块大小为32MB,-ms=on开启固实模式,-mf: 开启可执行文件压缩过滤器。,-mhc: 开启档案文件头压缩,-mhcf: 开启档案文件头完全压缩
#要将名为dir1的文件夹压缩到名为archive.7z的7z文件中
- 7z 拓展
- 使用LZMA算法的命令
7z a -t7z -m0=lzma
7z a -v100M -mx=0 yourfile.iso.7z yourfile.iso # part group
- LZMA2算法的命令
7z a -t7z -m0=lzma2
- bzip2算法的命令
7z a -tbzip2
- gz算法
7z a -tgzip archive.tar.gz file_to_compres
-
-
LZMA and LZMA2(基于改良与优化后的LZ77算法LZMA2是LZMA的改良版本,提供比LZMA更好的多线程支持。但是压缩率在某些情况下可能更糟)bzip2 算法为了使用LZMA2达到最佳压缩率,建议使用1或2个CPU线程。如果将LZMA2与两个以上的线程一起使用,则7-zip将数据拆分为多个块,并分别压缩这些块(每个块2个线程)。7z格式适用于压缩大文件或者文件夹,能提供较高的压缩比。
-
bz 文件格式BWT (Burrows-Wheeler Transform) 算法 为文本文件提供高速和相当不错的压缩率。适合压缩文本文件和源码。
-
gz 文件格式Deflate算法是ZIP和GZip格式的标准压缩,压缩率较低,提供了快速的压缩和解压缩。Deflate方法仅支持32 KB字典。gz格式可有效地压缩文本中的重复字符,例如HTML文件、CSS文件、JavaScript文件需要快速压缩和解压缩的场景。对于复杂的文件类型甚至无压缩效果.
-
-
tar(只起打包作用,无压缩=x) 显示进度条
tar -cf - a.csv | pv -s $(du -sb a.csv | awk '{print \$1}') | gzip > a.tgz
#在Linux环境下,可以使用pv命令来显示tar命令的压缩和解压进度。pv命令用于监视数据通过pipe的进度,能够显示耗时、完成率(进度条)、当前吞吐率、总传输字节等信息。使用方式是在两个程序之间,以合适的参数插入
pv question.tar.gz | tar -zxf - #解压
- 显示进程信息(cpu内存)
- ps命令和grep命令来实时监控特定进程
while true; do
ps aux | grep '7z' | grep -v 'grep'
sleep 1
done
#这个脚本会无限循环,每秒更新一次7z进程的信息。ps aux会显示所有进程的详细信息,包括CPU和内存使用情况。然后,grep '7z'会从这些信息中筛选出7z进程的信息,最后,grep -v 'grep'会排除掉包含'grep'的行,因为我们不需要显示搜索进程自身。
#USER:运行进程的用户名称
#PID:进程ID
#%CPU:进程使用的CPU百分比
#%MEM:进程使用的内存百分比
#VSZ:进程使用的虚拟内存量(KB)
#RSS:进程使用的未交换物理内存量(KB)
#START:进程启动时的时间
#TIME:CPU时间,即进程启动后占用CPU的总时间
#COMMAND:启动进程的命令行命令
#awk可以选择只想显示的信息
while true; do
ps aux | grep '7z' | grep -v 'grep' | awk '{print \$3,\$4}'
sleep 1
done
#综上所述可以写一个脚本
sudo vim script.sh
#!/bin/zsh
echo "Enter the directory path:"
read dir
echo "Do you want to compress each file separately? (yes/no)"
read separate
if [ "$separate" = "yes" ]; then
# Compress each file separately
for file in $dir/*; do
filename=$(basename -- "$file")
extension="${filename##*.}"
filename="${filename%.*}"
7z a "${filename}.7z" "$file"
done
else
# Compress all files together
7z a compressed.7z $dir
fi
echo "Do you want to split the archive into volumes? (yes/no)"
read split
if [ "$split" = "yes" ]; then
# Split the archive into volumes
7z a -v4096m compressed.7z $dir
fi
echo "Do you want to password protect the archive? (yes/no)"
read password
if [ "$password" = "yes" ]; then
echo "Enter the password:"
read pass
# Password protect the archive
7z a -p$pass compressed.7z $dir
fi
echo "Check if the script ran successfully?"
read check
if [ "$check" = "yes" ]; then
# Check if the script ran successfully
if [ -f compressed.7z ]; then
echo "The script ran successfully."
else
echo "The script did not run successfully."
fi
fi
—004 .desktop文件&&桌面图标
- 文件基本格式
[Desktop Entry]
Name=<应用程序名>
Type=Application
Exec=<应用程序完整路径>
Icon=<应用程序图标的完整路径>
# Name: desktop 文件最终显示的名称(一定要注意和 desktop 文件名的区别)
#Type: 用于指定 desktop 文件的类型(包括 3 种类型:Application、Link、Directory)
#Exec: 用于指定二进制可执行程序的完整路径
#Icon: 指定应用程序图标的完整路径(可以省略后缀名)。图标支持 png 格式、svg 格式等,图标的推荐尺寸为 128x128。
- eg
sudo vi clion.desktop
[Desktop Entry]
Name=CLion
Type=Application
Exec=/opt/clion-2018.3.3/bin/clion.sh
Icon=/opt/clion-2018.3.3/bin/clion
Categories=Development
#启动器本质是一个位于 /usr/share/applications/路径下的目录
sudo cp ~/Desktop/clion.desktop /usr/share/applications # 把 clion.desktop 复制一份到启动器目录下
- eg2
- firedev for desk
[Desktop Entry]
Name=Firefox Developer Edition
GenericName=Web Browser
Exec=/usr/bin/firefox-developer-edition-en-us-kbx %u
Icon=firefox-developer-edition
Terminal=false
Type=Application
MimeType=text/html;text/xml;application/xhtml+xml;application/vnd.mozilla.xul+xml;text/mml;x-scheme-handler/http;x-scheme-handler/https;
StartupNotify=true
Categories=Network;WebBrowser;
Keywords=web;browser;internet;
Actions=new-window;new-private-window;
StartupWMClass=Firefox Developer Edition
[Desktop Action new-window]
Name=Open a New Window
Exec=/usr/bin/firefox-developer-edition-en-us-kbx %u
[Desktop Action new-private-window]
Name=Open a New Private Window
Exec=/usr/bin/firefox-developer-edition-en-us-kbx --private-window %u
—005u盘/硬盘挂载与bug处理
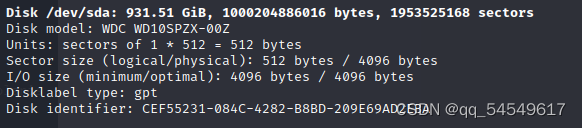
- linux无法查看 识别硬盘
lsblk
#查看 ->发现没有看到那块硬盘
ls /sys/class/scsi_host/ -l
# 查看当前系统有多少个host目录
#有多少个host就往多少个host目录里面文件scan追加"- - -"
vi disk_cat.sh
#!/bin/bash
scsisum=`ls -l /sys/class/scsi_host/host*|wc -l`
for ((i=0;i<${scsisum};i++))
do
echo "- - -" > /sys/class/scsi_host/host${i}/scan
done
#创建分区
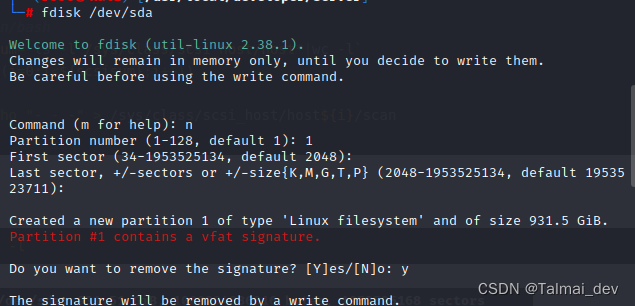
fdisk -l
fdisk /dev/sda
#n表示new,p表示主分区,1是分区号,指定开始扇区,回车使用默认,即扇区开始位置,指定结束分区,同样回车使用默认,即扇区结束位置,w保存
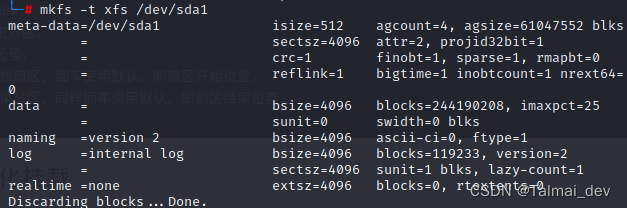
# 格式化挂载
```shell
mkfs -t xfs /dev/sda1
#刚才选择了 分区号1 变成了 sda1
# 格式化分区,指定格式为xfs
mount /dev/sda1 /data
#选择路径挂载
linux—006忘记密码怎么办
- 当你拿到物理机的时候 你实际上已经拿到了最高权限
- 因为你可以进入系统编辑模式去修改root密码
所以今天学完之后 你有没有考虑去偷公司服务器 扛着服务器一边跑路一边改密码 - centos7
未没进去前秒接e取消前摇
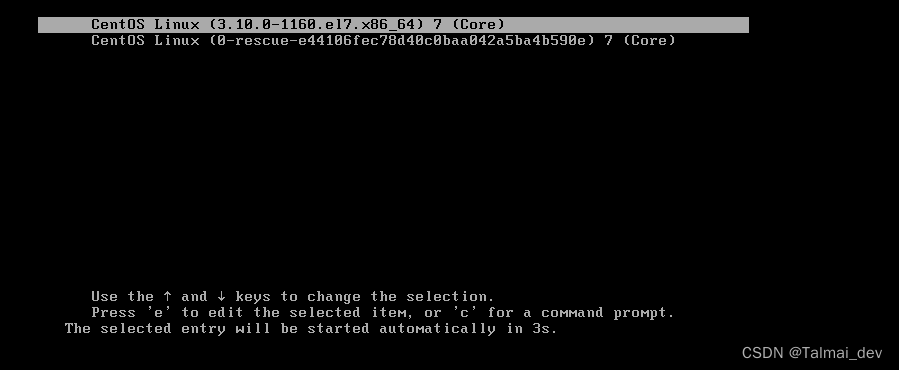 方向键控制向下滑
方向键控制向下滑
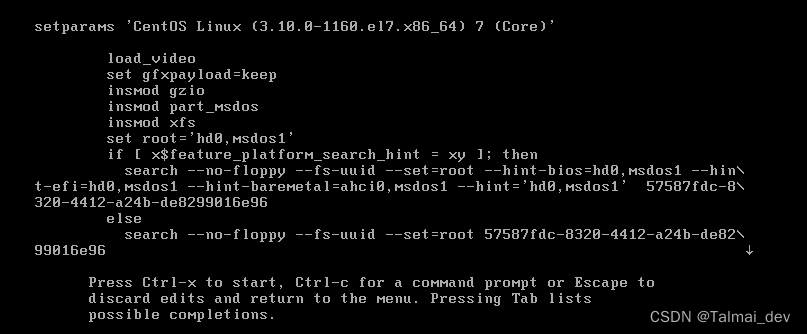
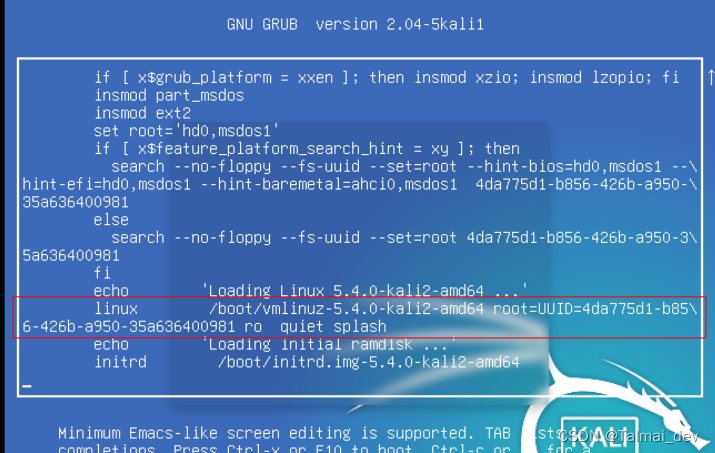
将ro改成 rw init=/sysroot/bin/sh
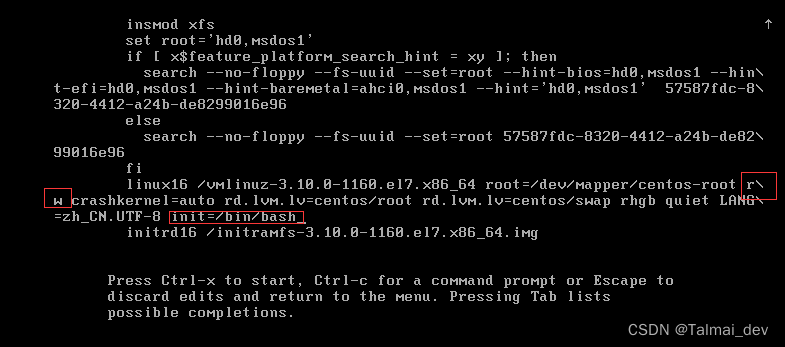
ctrl+x centos7之后没有十年前那么多bug以及需要挂载的问题了 直接输入passwd修改密码就好
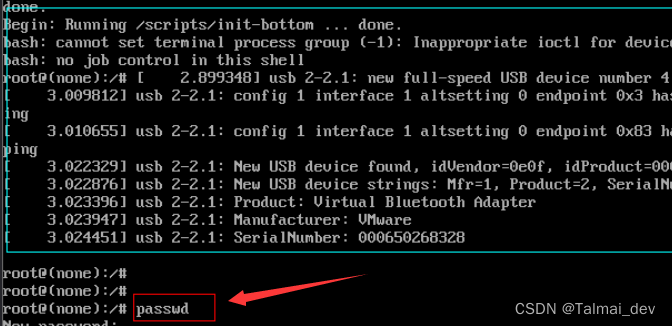
passwd
如果是中文安装这边会乱码的
- kali
- 同理 也是在刚刚出现系统的时候点e进入编辑模式
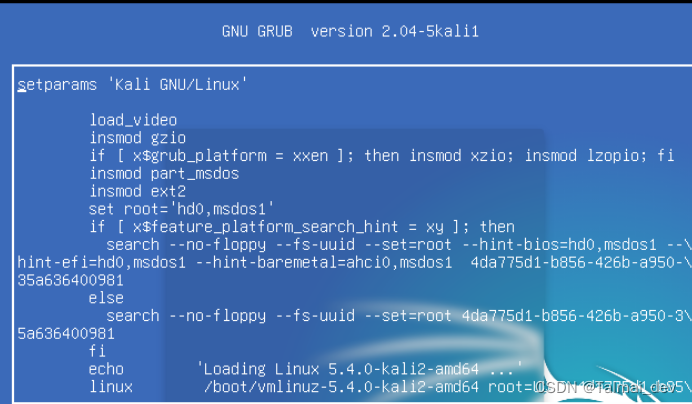
下滑到这一行
- 同理 也是在刚刚出现系统的时候点e进入编辑模式
- 这边也是把ro改成rw,删掉quiet splash,在后面加上init=/bin/bash ,ctrl+x退出当前界面,到下图的界面
—007kali/debain 包管理
- apt
高级包装工具(Advanced Packaging Tools,简称APT)是Debian及其衍生发行版(如Ubuntu)的软件包管理器。APT可以自动下载,配置,安装二进制或者源代码格式的软件包。
- 安装卸载
# 搜索查看
sudo apt-cache search
#搜索软件
sudo apt-cache show
#查看包的相关信息、大小、版本等
sudo apt-cache stats
#显示当前系统所有使用的Debain数据源的统计信息
sudo apt-cache depends
#查找软件包的依赖关系
# 安装
sudo apt-get install
#普通安装
sudo apt-get -f install
# 修复安装
sudo apt-get -reinstall install
#重新安装
#更新
sudo apt-get update
# 刷新软件源
sudo apt-get list --uygradable
# 查看可更新软件
sudo apt-get upgrade
#更新所有包
sudo apt-get dist-upgrade
#连带内核一起更新
sudo apt autoremove
#更新完成之后清除不需要的旧组件
#卸载软件
sudo apt-get remove
#移除式卸载,只是删掉数据和可执行文件
sudo apt-get --purge remove
#清除式卸载,完全卸载同时清除配置文件
sudo apt-get autoremove --purge
#删除包及其依赖的软件包+配置文件等 ==最彻底的方法
- dpkg----大多非内置包处理工具
- 安装卸载
# 安装
sudo dpkg -i package-name.deb
# 卸载
sudo dpkg -r
#移除一个已安装的包。
sudo dpkg --remove
#删掉数据和可执行文件
dpkg -P
#完全清除一个已安装的包。和 remove 不同的是,remove 只是删掉数据和可执行文件,purge 另外还删除所有的配制文件 ==最彻底的方法
- dpkg参数
| 说明 | 命令 | 示例 |
|---|---|---|
| 安装软件 | dpkg -i <.deb file name> | dpkg -i avg71flm_r28-1_i386.deb |
| 安装一个目录下面所有的软件包 | dpkg -R | dpkg -R /usr/local/src |
| 释放软件包,但是不进行配置 | dpkg –unpack package_file 如果和-R一起使用,参数可以是一个目录 | dpkg –unpack avg71flm_r28-1_i386.deb |
| 重新配置和释放软件包 | dpkg –configure package_file 如果和-a一起使用,将配置所有没有配置的软件包 | dpkg –configure avg71flm_r28-1_i386.deb |
| 删除软件包(保留其配置信息) | dpkg -r dpkg -r avg71flm | |
| 替代软件包的信息 | dpkg –update-avail | |
| 合并软件包信息 | dpkg –merge-avail | |
| 从软件包里面读取软件的信息 | dpkg -A package_file | |
| 删除一个包(包括配置信息) dpkg -P | ||
| 丢失所有的Uninstall的软件包信息 | dpkg –forget-old-unavail | |
| 删除软件包的Avaliable信息 | dpkg –clear-avail | |
| 查找只有部分安装的软件包信息 | dpkg -C | |
| 比较同一个包的不同版本之间的差别 | dpkg –compare-versions ver1 op ver2 | |
| 显示帮助信息 | dpkg –help | |
| 显示dpkg的Licence | dpkg –licence (or) dpkg –license | |
| 显示dpkg的版本号 | dpkg –version | |
| 建立一个deb文件 | dpkg -b direc×y [filename] | |
| 显示一个Deb文件的目录 | dpkg -c filename | |
| 显示一个Deb的说明 | dpkg -I filename [control-file] | |
| 搜索Deb包 | dpkg -l package-name-pattern dpkg -I vim | |
| 显示所有已经安装的Deb包,同时显示版本号以及简短说明 | dpkg -l | |
| 报告指定包的状态信息 | dpkg -s package-name dpkg -s ssh | |
| 显示一个包安装到系统里面的文件目录信息 | dpkg -L package-Name | dpkg -L apache2 |
| 搜索指定包里面的文件(模糊查询) | dpkg -S filename-search-pattern | |
| 显示包的具体信息 | dpkg -p package-name | dpkg -p cacti |
update-initramfs的用途和功能
update-initramfs 是在 Linux 系统中用于更新 initramfs 归档文件的一个命令。initramfs(初始内存文件系统)是一个临时的根文件系统,它在系统启动过程中加载到内存中。它包含了启动时直到可以挂载真正的根文件系统所必需的驱动程序和工具。这个机制允许内核在实际的根文件系统可用之前,访问硬件设备,如磁盘控制器和网络接口。
update-initramfs 的主要用途和功能包括:
更新 initramfs:当安装、更新或删除涉及系统启动过程的软件包时(如内核、驱动程序或启动过程中必需的工具),需要更新 initramfs 以反映这些更改。
生成新的 initramfs 归档文件:通过该命令可以为新安装的内核生成一个新的 initramfs 文件。
备份:在生成新的 initramfs 之前,通常会自动备份旧的 initramfs 文件,以防更新过程中出现问题。
[固件文件]https://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git/tree/i915
—008 ssh安全使用
- 配置文件 ssh -v -->bug for line
- /etc/ssh/ssh_config
- 重要参数
- Compression yes # 是否可以使用压缩指令?
# Host * # Host指令是ssh_config中最重要的指令,只有ssh连接的目标主机名能匹配此处给定模式时,才允许连接
# 下面一系列配置项直到出现下一个Host指令才对此次连接生效
# ForwardAgent no #设置连接是否经过验证代理(如果存在)转发给远程计算机
# ForwardX11 no #设置X11连接是否被自动重定向到安全的通道和显示集(DISPLAY set)
# RhostsRSAAuthentication no #设置是否使用基于rhosts的安全验证。
# RSAAuthentication yes #设置是否使用用RSA算法的基于rhosts的安全验证。
# PasswordAuthentication yes # 是否启用基于密码的身份认证机制
# HostbasedAuthentication no # 是否启用基于主机的身份认证机制
# GSSAPIAuthentication no # 是否启用基于GSSAPI的身份认证机制
# GSSAPIDelegateCredentials no
# GSSAPIKeyExchange no
# GSSAPITrustDNS no
# BatchMode no # 如果设置为"yes",将禁止passphrase/password询问。比较适用于在那些不需要询问提供密
# 码的脚本或批处理任务任务中。默认为"no"。
# CheckHostIP yes
# AddressFamily any
# ConnectTimeout 0
# StrictHostKeyChecking ask # 设置为"yes",ssh将从不自动添加host key到~/.ssh/known_hosts文件,且拒绝连接那些未知的主机(即未保存host key的主机或host key已改变的主机)。
# 它将强制用户手动添加host key到~/.ssh/known_hosts中。
# 设置为ask将询问是否保存到~/.ssh/known_hosts文件。
# 设置为no将自动添加到~/.ssh/known_hosts文件。
# IdentityFile ~/.ssh/identity # ssh v1版使用的私钥文件
# IdentityFile ~/.ssh/id_rsa # ssh v2使用的rsa算法的私钥文件
# IdentityFile ~/.ssh/id_dsa # ssh v2使用的dsa算法的私钥文件
# Port 22 # 当命令行中不指定端口时,默认连接的远程主机上的端口
# Protocol 2,1
# Cipher 3des # 指定ssh v1版本中加密会话时使用的加密协议
# Ciphers aes128-ctr,aes192-ctr,aes256-ctr,arcfour256,arcfour128,aes128-cbc,3des-cbc # 指定ssh v1版本中加密会话时使用的加密协议
# MACs hmac-md5,hmac-sha1,umac-64@openssh.com,hmac-ripemd160
# EscapeChar ~
# Tunnel no
# TunnelDevice any:any
# PermitLocalCommand no # 功能等价于~/.ssh/rc,表示是否允许ssh连接成功后在本地执行LocalCommand指令指定的命令。
# LocalCommand # 指定连接成功后要在本地执行的命令列表,当PermitLocalCommand设置为no时将自动忽略该配置
# %d表本地用户家目录,%h表示远程主机名,%l表示本地主机名,%n表示命令行上提供的主机名,
# p%表示远程ssh端口,r%表示远程用户名,u%表示本地用户名。
# VisualHostKey no # 是否开启主机验证阶段时host key的图形化指纹
Host *
GSSAPIAuthentication yes
- 配置文件
- /etc/ssh/sshd_config
- 重要参数
- UseDNS no
-UseDNS 选项打开状态下,当客户端试图登录SSH服务器时,服务器端先根据客户端的IP地址进行DNS PTR反向查询出客户端的主机名,然后根据查询出的客户端主机名进行DNS正向A记录查询,验证与其原始IP地址是否一致,这是防止客户端欺骗的一种措施 - AddressFamily inet
- SyslogFacility AUTHPRIV
- PermitRootLogin yes
- PasswordAuthentication yes
/etc/ssh/sshd_config
#配置文件概要
[root@localhost ~]# cat /etc/ssh/sshd_config
#Port 22 # 服务端SSH端口,可以指定多条表示监听在多个端口上
#ListenAddress 0.0.0.0 # 监听的IP地址。0.0.0.0表示监听所有IP,指定IP只监听指定的IP
Protocol 2 # 使用SSH 2版本, 如果要同时支持两者,就必须要使用 2,1 这个分隔了
#####################################
# 私钥保存位置 #
#####################################
# HostKey for protocol version 1
#HostKey /etc/ssh/ssh_host_key # SSH 1保存位置/etc/ssh/ssh_host_key
# HostKeys for protocol version 2
#HostKey /etc/ssh/ssh_host_rsa_key # SSH 2保存RSA位置/etc/ssh/ssh_host_rsa _key
#HostKey /etc/ssh/ssh_host_dsa_key # SSH 2保存DSA位置/etc/ssh/ssh_host_dsa _key
###################################
# 杂项配置 #
###################################
#PidFile /var/run/sshd.pid # 服务程序sshd的PID的文件路径
#ServerKeyBits 1024 # 服务器生成的密钥长度
#SyslogFacility AUTH # 使用哪个syslog设施记录ssh日志。日志路径默认为/var/log/secure
#LogLevel INFO # 记录SSH的日志级别为INFO
#LoginGraceTime 2m # 身份验证阶段的超时时间,若在此超时期间内未完成身份验证将自动断开
###################################
# 以下项影响认证速度 #
###################################
#UseDNS yes # 指定是否将客户端主机名解析为IP,以检查此主机名是否与其IP地址真实对应。默认yes。
# 由此可知该项影响的是主机验证阶段。建议在未配置DNS解析时,将其设置为no,否则主机验证阶段会很慢
###################################
# 以下是和安全有关的配置 #
###################################
#PermitRootLogin yes # 是否允许root用户登录
#MaxSessions 10 # 最大客户端连接数量
#GSSAPIAuthentication no # 是否开启GSSAPI身份认证机制,默认为yes
#PubkeyAuthentication yes # 是否开启基于公钥认证机制
#AuthorizedKeysFile .ssh/authorized_keys # 基于公钥认证机制时,来自客户端的公钥的存放位置
PasswordAuthentication yes # 是否使用密码验证,如果使用密钥对验证可以关了它
#PermitEmptyPasswords no # 是否允许空密码,如果上面的那项是yes,这里最好设置no
StrictModes yes # 当使用者的 host key 改变之后,Server 就不接受联机,可以抵挡部分的木马程序!
#RSAAuthentication yes # 是否使用纯的 RSA 认证!?仅针对 version 1 !
###################################
# 以下可以自行添加到配置文件 #
###################################
DenyGroups hellogroup testgroup # 表示hellogroup和testgroup组中的成员不允许使用sshd服务,即拒绝这些用户连接
DenyUsers hello test # 表示用户hello和test不能使用sshd服务,即拒绝这些用户连接
###################################
# 以下一项和远程端口转发有关 #
###################################
#GatewayPorts no # 设置为yes表示sshd允许被远程主机所设置的本地转发端口绑定在非环回地址上
# 默认值为no,表示远程主机设置的本地转发端口只能绑定在环回地址上
linux–009(centos srream9 )搭建基础网络服务dnsmasq,LAMP,DVWA
- dnsmasq
# 安装 dnsmasq 软件包
sudo dnf install -y dnsmasq
# 主配置文件
sudo vim /etc/dnsmasq.conf
#设置监听接口
interface=eth0
#设置上游 DNS 服务器
server=8.8.8.8
server=8.8.4.4
# 配置本地域名解析: 查看虚拟机网络配置或者本地ip信息 内网环境
address=/example.local/192.168.0.1
# 配置DHCP
dhcp-range=192.168.0.100,192.168.0.200,12h
dhcp-option=option:router,192.168.0.1
# 启动并启用 dnsmasq 服务
sudo systemctl start dnsmasq
sudo systemctl enable dnsmasq
# 配置防火墙以允许 DNS 和 DHCP 通信:
sudo firewall-cmd --permanent --add-service=dns
sudo firewall-cmd --permanent --add-service=dhcp
sudo firewall-cmd --reload
# 验证 dnsmasq 配置:
dig @localhost example.local
- 编辑/etc/hosts文件并添加DNS记录
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# add records
10.0.0.30 dlp.srv.world dlp
10.0.0.31 www.srv.world www
#启动并使dnsmasq在启动时运行
systemctl enable --now dnsmasq
#配置防火墙以允许DNS服务
firewall-cmd --add-service=dns
firewall-cmd --runtime-to-permanent
- LAMP
# download
## apache
dnf -y install httpd httpd-devel
## 安装mariadb数据库及其扩展包。
dnf -y install mariadb mariadb-server
## 安装php数据库及其扩展包:
dnf -y install php php-mysqlnd php-gd libjpeg* php-ldap php-odbc php-pear php-xml php-mbstring php-bcmath php-mhash
# 防火墙/port
# apache
sudo firewall-cmd --add-service=http --permanent
#为 MariaDB 开放端口(默认是 3306):
sudo firewall-cmd --permanent --zone=public --add-port=3306/tcp
#重新加载防火墙配置以使更改生效:
sudo firewall-cmd --reload
- 验证apache
vi /var/www/html/info.php
<?php
phpinfo();
?>
- mysql 设置mariadb管理员密码并验证密码
mysqladmin -u root password 123456
mysql -u root -p
- 配置DVWA
git clone https://github.com/digininja/DVWA.git
sudo mv DVWA /var/www/html/dvwa
sudo vi /var/www/html/dvwa/config/config.inc.php
$_DVWA[ 'db_user' ] = 'dvwa';
$_DVWA[ 'db_password' ] = 'p@ssw0rd';
$_DVWA[ 'db_database' ] = 'dvwa';
$_DVWA[ 'db_server' ] = 'localhost';
- 由于MariaDB不支持root用户登录,所以我们需要创建一个新的用户(例如dvwa)。并且,db_server需要改成localhost
mysql -u root -p
CREATE DATABASE dvwa;
CREATE USER 'dvwa'@'localhost' IDENTIFIED BY 'p@ssw0rd';
GRANT ALL PRIVILEGES ON dvwa.* TO 'dvwa'@'localhost';
FLUSH PRIVILEGES;
EXIT;
- 访问DVWA的安装页面,点击“创建数据库”按钮。然后,你应该能看到DVWA的登录页面。默认的用户名为admin,密码为password。注意,这是DVWA默认的,并未更改
linux内核
- 是系统核心负责管理系统的硬件资源,提供程序运行时所需的各种服务。内核是系统与硬件之间的桥梁
- linux-image软件包包含了Linux内核的二进制文件,可以直接被计算机硬件使用(更换内核)引导加载器(如GRUB)会加载linux-image中的内核二进制文件,启动操作系统
- linux-headers软件包包含了内核的头文件(linuxAPI)。可编译内核模块,比如说一个特定的驱动程序,头文件定义了函数、变量等的接口,使得外部代码能够正确地与内核代码进行交互。
—011自动批量配置n台全分布hadoop负载集群脚本可执行脚本
#!/bin/bash
# Define the software versions and installation directory
jdk_version="jdk-11.0.12"
mysql_version="mysql-8.0.26"
hadoop_version="hadoop-3.3.5"
hive_version="hive-3.1.2"
sqoop_version="sqoop-1.4.7"
zookeeper_version="zookeeper-3.7.0"
install_dir="/opt"
# Function to install JDK
install_jdk() {
wget https://example.com/$jdk_version.tar.gz
tar -xzvf $jdk_version.tar.gz
mv $jdk_version $install_dir
ln -s $install_dir/$jdk_version /usr/local/$jdk_version
}
# Function to install MySQL
install_mysql() {
wget https://example.com/$mysql_version.tar.gz
tar -xzvf $mysql_version.tar.gz
mv $mysql_version $install_dir
ln -s $install_dir/$mysql_version /usr/local/$mysql_version
}
# Function to install Hadoop
install_hadoop() {
wget https://example.com/$hadoop_version.tar.gz
tar -xzvf $hadoop_version.tar.gz
mv $hadoop_version $install_dir
ln -s $install_dir/$hadoop_version /usr/local/$hadoop_version
}
# Function to install Hive
install_hive() {
wget https://example.com/$hive_version.tar.gz
tar -xzvf $hive_version.tar.gz
mv $hive_version $install_dir
ln -s $install_dir/$hive_version /usr/local/$hive_version
}
# Function to install Sqoop
install_sqoop() {
wget https://example.com/$sqoop_version.tar.gz
tar -xzvf $sqoop_version.tar.gz
mv $sqoop_version $install_dir
ln -s $install_dir/$sqoop_version /usr/local/$sqoop_version
}
# Function to install Zookeeper
install_zookeeper() {
wget https://example.com/$zookeeper_version.tar.gz
tar -xzvf $zookeeper_version.tar.gz
mv $zookeeper_version $install_dir
ln -s $install_dir/$zookeeper_version /usr/local/$zookeeper_version
}
# Call the installation functions
install_jdk
install_mysql
install_hadoop
install_hive
install_sqoop
install_zookeeper
# Configuration steps
cd /usr/local/$hadoop_version/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
cp core-site.xml.template core-site.xml
cp hdfs-site.xml.template hdfs-site.xml
cp yarn-site.xml.template yarn-site.xml
cd /usr/local/$hive_version/conf
cp hive-env.sh.template hive-env.sh
cp hive-site.xml.template hive-site.xml
cd /usr/local/$sqoop_version/conf
cp sqoop-env-template.sh sqoop-env.sh
cp sqoop.properties.template sqoop.properties
cd /usr/local/$zookeeper_version/conf
cp zoo_sample.cfg zoo.cfg
echo "
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
" > /usr/local/$hadoop_version/etc/hadoop/core-site.xml
echo "
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
" > /usr/local/$hadoop_version/etc/hadoop/hdfs-site.xml
echo "
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
" > /usr/local/$hadoop_version/etc/hadoop/mapred-site.xml
# 配置Hadoop yarn-site.xml
echo "
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
</configuration>
" > /usr/local/$hadoop_version/etc/hadoop/yarn-site.xml
# 配置Hive hive-site.xml
echo "
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
" > /usr/local/$hive_version/conf/hive-site.xml
# 配置Sqoop sqoop-env.sh
echo "
export HADOOP_COMMON_HOME=/usr/local/$hadoop_version
export HADOOP_MAPRED_HOME=/usr/local/$hadoop_version
export HIVE_HOME=/usr/local/$hive_version
export ZOOKEEPER_HOME=/usr/local/$zookeeper_version
" > /usr/local/$sqoop_version/conf/sqoop-env.sh
# 配置Zookeeper zoo.cfg
echo "
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
" > /usr/local/$zookeeper_version/conf/zoo.cfg
- 将以上脚本同时分发给n台服务器并运行
#!/bin/bash
# Define the script file and IP address file
script_file="install.sh"
ip_file="ip_addresses.txt"
# Read the IP addresses from the file and execute the script on each server
while IFS= read -r ip_address
do
echo "Running script on $ip_address"
scp $script_file $ip_address:~/ # Transfer the script file to the server
ssh $ip_address "bash ~/$(basename $script_file)" # Execute the script on the server
done < "$ip_file"
kali scp注意事项
- Kali Linux是一款基于Debian的Linux发行版,专门用于高级渗透测试和安全审核。在Kali Linux中,你可以使用SSH和SCP命令进行远程登录和文件传输操作。以下是常用的SSH和SCP命令演示以及遇到的常见报错和解决方法:
#使用SSH命令登录远程Linux服务器:
ssh -l <用户名> -p <端口号> <主机名或IP>
#例如,登录远程服务器的root用户,端口号为22:
ssh -l root -p 22 192.168.0.1
# SCP命令演示:
## 将本地文件拷贝到远程服务器:
scp -P <端口号> <本地文件路径> <用户名>@<计算机IP或名称>:<远程路径>
#例如,将本地的file.txt文件拷贝到远程服务器的/tmp目录下:
scp -P 22 file.txt username@192.168.0.1:/tmp
## 从远程服务器将文件拷回本地:
scp -P <端口号> <用户名>@<计算机IP或名称>:<文件名> <本地路径>
##从远程服务器将/tmp目录下的file.txt文件拷回本地的/home/user目录下:
scp -P 22 username@192.168.0.1:/tmp/file.txt /home/user
## 将本地目录拷贝到远程服务器:
scp -r -P <端口号> <本地目录路径> <用户名>@<计算机IP或名称>:<远程路径>
## 例如,将本地的dir目录拷贝到远程服务器的/tmp目录下:
scp -r -P 22 dir username@192.168.0.1:/tmp
##从远程服务器将目录拷回本地:
scp -r -P <端口号> <用户名>@<计算机IP或名称>:<目录名> <本地路径>
## 例如,从远程服务器将/tmp目录拷回本地的/home/user目录下:
scp -r -P 22 username@192.168.0.1:/tmp /home/user
-
注意事项和避免报错:
- 若在执行SCP上传文件时报错提示对方没有安装openssh-clients软件包,可以尝试在远程服务器上安装openssh-clients软件包来解决该问题。
- 在使用SCP命令时,需要确保本地文件和目录的路径是正确的,并且远程服务器的用户名、IP地址、端口号和路径也是正确的。
- 在进行SSH和SCP操作时,需要确保远程服务器已经开启了SSH服务,并且相应的端口号没有被防火墙阻止。
- 可能还会遇到其他报错,例如权限问题、网络连接问题等。在遇到报错时,可以根据报错信息进行排查,查看相关日志文件来获取更多详细信息,然后针对具体问题进行解决。
012 linux core and windows Dump
https://gohalo.github.io/cn/blog/c-linux-core-introduce/
----- 查看配置,如果为0,则说明未开启
$ ulimit -c
----- 设置转储文件大小,单位是blocks(KB),unlimited表示不限
# ulimit -c unlimited
----- 设置转储文件大小为100KB
# ulimit -c 100
当设置为 unlimited 时,则表示不限制内核转储文件的大小,发生问题时所有的内存都将转储到文件中;对于大量消耗内存的程序可以限制转储文件的大小。
如果要持久化,可以修改 /etc/security/limits.conf 文件即可,参考如下示例。
#<domain> <type> <item> <value>
* soft core unlimited
默认生成的 core 文件保存在可执行文件所在目录下,文件名为 core;当然,也可以通过如下方式进行设置。
----- 添加PID后缀
# echo 1 > /proc/sys/kernel/core_uses_pid
----- 设置输出目录,格式为core-命令名-PID-时间戳
# echo "/tmp/core-%e-%p-%t" > /proc/sys/kernel/core_pattern
-
常见参数:
%t: 设置文件转储时的 unix 时间,从 1970.1.1 0:00:00 开始的秒数。
%e: 执行的命令名。
%p: 被转储进程的 PID 。
%u: 被转储进程的真实用户 ID ,也即 UID 。
%g: 被转储进程的真实组 ID ,也即 GID 。
%s: 引发转储的信号编号。
%h: 主机名,同 uname(2) 返回的 nodename 。
%c: 转储文件大小的上限,2.6.24 以后可以使用。 -
设置完 core_pattern 之后,core_user_pid 会无效,也可以通过 sysctl 进行设置。
# cat /etc/sysctl.conf
kernel.core_pattern = /var/%e-%p-%t.core
kernel.core_user_pid = 0
# sysctl -p
可以在程序执行期间发送 SIGSEGV(11) 信号,也即 Ctrl+\ 快捷键。
----- 使用Ctrl+\退出程序,产生core dump
$ sleep 100
^\Quit (core dumped)
----- 或者发送SIGSEGV(11)信号
kill -s SIGSEGV $$
kill -11
接着看一个简单的示例程序。
$ cat << EOF > create_core.c
int a (int *p)
{
int y = *p;
return y;
}
int main (void)
{
int *p = NULL;
*p = 0; // 访问0地址,发生Segmentation fault错误
return a§;
}
EOF
$ gcc -Wall -g create_core.c -o create_core
$ ./create_core
Segmentation fault (core dumped)
也可以通过 API 进行设置,不过此时编译之后,在运行时需要 root 权限。
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#define CORE_SIZE 1024 * 1024 * 500
int main(void)
{
struct rlimit rlmt;
if (getrlimit(RLIMIT_CORE, &rlmt) == -1)
return -1;
printf("Before set rlimit CORE dump current is:%d, max is:%d\n",
(int)rlmt.rlim_cur, (int)rlmt.rlim_max);
rlmt.rlim_cur = (rlim_t)CORE_SIZE;
rlmt.rlim_max = (rlim_t)CORE_SIZE;
if (setrlimit(RLIMIT_CORE, &rlmt) == -1)
return -1;
if (getrlimit(RLIMIT_CORE, &rlmt) == -1)
return -1;
printf("After set rlimit CORE dump current is:%d, max is:%d\n",
(int)rlmt.rlim_cur, (int)rlmt.rlim_max);
int *ptr = NULL; // 测试非法内存,产生core文件
*ptr = 10;
return 0;
}
在调试时可以通过 gdb program core-file 调试,当然编译时,需要加上调试信息 -g。
$ gdb core_demo core_demo.core.24816
…
Core was generated by ‘./core_demo’.
Program terminated with signal 11, Segmentation fault.
#0 0x080483cd in func (p=0x0) at core_demo.c:5
5 int y = *p;
(gdb) where # 或者backtrace
#0 0x080483cd in func (p=0x0) at core_demo.c:5
#1 0x080483ef in main () at core_demo.c:12
(gdb) info frame
Stack level 0, frame at 0xffd590a4:
eip = 0x80483cd in func (core_demo.c:5); saved eip 0x80483ef
called by frame at 0xffd590c0
source language c.
Arglist at 0xffd5909c, args: p=0x0
Locals at 0xffd5909c, Previous frame’s sp is 0xffd590a4
Saved registers:
ebp at 0xffd5909c, eip at 0xffd590a0
从上面可以看出,可以还原 core_demo 执行时的场景,使用 where 或者 backtrace 查看当前程序调用函数栈帧,来定位 core dump 的文件行,还可以查看寄存器、变量等信息。
也可以通过如下方式查看。
$ gdb -c core_demo.core.24816 core_demo
$ gdb core_demo
(gdb) core core_demo.core
debuginfo #
一般线上生成的文件会删除 Debug、符号表信息,但是一旦有问题了,例如发生了 CoreDump ,那么就需要使用符号表了。
使用 file test 命令查看时,会显示改文件为 not stripped ,当通过 nm test 查看时会发现一堆的符号,或者通过 readelf -S test 查看。
为了能够使用 gdb 跟踪调试程序,需要在编译期使用 -g 选项;而对于系统库或是 Linux 内核,使用 gdb 调试或使用 systemtap 探测时,还需要安装相应的 debuginfo 包。
例如 glibc 及它的 debuginfo 包。
yum --enablerep=base-debuginfo install glibc-debuginfo
$ rpm -qa | grep glibc
glibc-2.17-157.el7_3.1.x86_64
glibc-debuginfo-2.17-157.el7_3.1.x86_64
接下来,我们看看 debuginfo 包中包含了那些信息,该包是如何制作的,而且 glibc 和 debuginfo 是如何关联起来的。
包含信息 #
首先看看 glibc-debuginfo 包中包含有什么内容。
$ rpm -ql glibc-debuginfo
/usr/lib/debug
/usr/lib/debug/.build-id
/usr/lib/debug/.build-id/00
/usr/lib/debug/.build-id/00/98d7f56d263e087a1abad592e81e3e79e26652
/usr/lib/debug/.build-id/00/98d7f56d263e087a1abad592e81e3e79e26652.debug
… …
/usr/lib/debug/lib64
/usr/lib/debug/lib64/ld-2.17.so.debug
/usr/lib/debug/lib64/ld-linux-x86-64.so.2.debug
/usr/lib/debug/lib64/libBrokenLocale-2.17.so.debug
/usr/lib/debug/lib64/libBrokenLocale.so.1.debug
… …
/usr/src/debug/glibc-2.17-c758a686
/usr/src/debug/glibc-2.17-c758a686/argp
/usr/src/debug/glibc-2.17-c758a686/argp/argp-ba.c
/usr/src/debug/glibc-2.17-c758a686/argp/argp-eexst.c
/usr/src/debug/glibc-2.17-c758a686/argp/argp-fmtstream.c
… …
可以看出 glibc-debuginfo 大致有三类文件:
存放在 /usr/lib/debug/ 下的 .build-id/nn/nnn...nnn.debug 文件,文件名是 hash key 。
存放在 /usr/lib/debug/ 下的其它 *.debug 文件,其文件名,是库文件名+.debug 后缀。
glibc 的源代码。
当使用 gdb 调试时,需要在机器码与源代码之间,建立起映射关系,这就需要三个信息:
机器码:可执行文件、动态链接库,例如上面的 /lib64/libc-2.18.so;
源代码:显然就是 glibc-debuginfo 中,包含的 *.c 和 *.h 等源文件;
映射关系:也就是保存在 *.debug 文件中的信息。
如何生成 #
通过 gcc -g 编译时,默认机器码与源代码的映射关系会与可执行程序、动态链接库合并在一起;但是这样就导致文件特别大,而对于普通用户来说是不需要的。
正是了为解决这个问题,在 Linux 上的各种程序和库,在生成 RPM 时,就已经把 debuginfo 单独的抽取出来,因此形成了独立的 debuginfo 包。
$ cat << EOF > foobar.c
#include <stdio.h>
int main(void)
{
printf(“Hello World!!!\n”);
return 0;
}
EOF
----- 其中参数-ggdb生成gdb格式调试信息
$ gcc -ggdb foobar.c -o foobar
----- 查看段信息,有一堆的.debug段
$ readelf -S foobar
----- 删除.debug段的信息,符号表和字符串还在,调试仍可以查看符号信息
$ strip --strip-debug foobar
----- 同时删除.symtab和.strtab,默认的操作
$ strip --strip-all foobar
----- 创建一个包含debuginfo的文件
$ objcopy --only-keep-debug foobar foobar.debug
----- 添加一个包含路径文件的.gnu_debuglink section,注意执行时文件必须存在
$ objcopy --add-gnu-debuglink=foobar.debug foobar
----- 或者一步到位
$ eu-strip foobar -f foobar.debug
----- 查看新添加的.gnu_debuglink section
$ objdump -s -j .gnu_debuglink test
----- 清除原执行文件中的调试信息,如下两个操作相同
$ objcopy --strip-debug foobar
$ strip --strip-debug foobar
----- 此时尝试加载调试符号时会报错
$ gdb foobar
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-94.el7
… …
Reading symbols from /tmp/foobar…(no debugging symbols found)…done.
(gdb)
----- 当然,现在可以指定gdb需要加载的debuginfo即可,如下两者相同
$ gdb foobar -s foobar.debug
$ gdb
(gdb) file foobar
(gdb) symbol-file foobar.debug
显然,gdb 现在无法找到调试信息了;我们需要告诉 gdb 如何正确地找到它对应的 debug 文件,也就是上述的 foobar.debug 文件。
对于 Linux 下的 ELF(Executable and Linkable Format) 格式文件,可以通过一个 .gnu_debuglink 段来保存信息,可通过 objcopy --add-gnu-debuglink 添加。
----- 添加一个包含路径文件的.gnu_debuglink section
$ objcopy --add-gnu-debuglink=foobar.debug foobar
----- 查看.gnu_debuglink section
$ objdump -s -j .gnu_debuglink foobar
foobar: file format elf64-x86-64
Contents of section .gnu_debuglink:
0000 666f6f62 61722e64 65627567 00000000 foobar.debug…
0010 ba8924f6
----- 现在可以直接调试了
$ gdb foobar
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-94.el7
… …
Reading symbols from /tmp/test/foobar…Reading symbols from /tmp/test/foobar.debug…done.
done.
(gdb)
上面的 objcopy 是把 foobar.debug 的文件名以及这个文件的 CRC 校验码,写到了.gnu_debuglink 这个 ELF 的头部值中,但是并没有告诉 foobar.debug 所在的路径。
搜索路径 #
在 Linux 中,在编译时会根据时间戳生成 build-id,并保存到 gnu.build-id section 中;可以通过如下命令查看 “gnu.build-id” section 信息。
$ readelf -n foobar
$ readelf -t foobar |grep build-id
$ readelf --wide --sections foobar |grep build
$ objdump -s -j .note.gnu.build-id foobar
而 gdb 默认会搜索指定目录 (show debug-file-directory) 下与 build-id 关联的 .debug 文件。默认 gdb 搜索的文件名为 NN/N…N.debug, 前两个 NN 就是 build-id 前两位,后面的 N…N 则是 build-id 的剩余部分,只是改了个文件名而已。
而 gdb 则是通过下面的顺序查找 foobar.debug 文件:
- /.build-id/nn/nnnn…nnnn.foobar.debug
- /foobar.debug
- /.debug/foobar.debug
- //foobar.debug
而 默认为 /usr/lib/debug/;可以通过 set/show debug-file-directory 命令来设置或查看这个值。
(gdb) show debug-file-directory
(gdb) set debug-file-directory PATH
假设 foobar 的 Build ID 为 3bda624ab466b7725faaf5cde424a5674a741c5d,可将 foobar.debug 文件移动到 /usr/lib/debug/.build-id/3b/da624ab466b7725faaf5cde424a5674a741c5d.debug 。
foobar.debug 默认会采用 DWARF 4 格式来保存调试信息,可以通过 readelf -w foobar.debug 来查看 DWARF 的内容;详见 DWARF Debugging Information Format Version 4 。
如下是放置到默认路径下的一个示例:
----- 查看二进制文件的BuildID,并添加默认目录下
$ readelf -n test | grep Build
Build ID: e380efb0fe7873bcc96506035e8640a365b29ef4
$ mkdir -p /usr/lib/debug/.build-id/e3
$ mv test.debug /usr/lib/debug/.build-id/e3/80efb0fe7873bcc96506035e8640a365b29ef4.debug
----- 查看当前debuginfo默认搜索目录,可通过set debug-file-directory path重新指定
(gdb) show debug-file-directory
The directory where separate debug symbols are searched for is “/usr/lib/debug”.
----- 会自动加载debuginfo文件
(gdb) file test
生成Marker探针 #
通过 gcc -g 命令,所有函数名都会自动的生成相应的 debuginfo,供 systemtap 进行探测, 其局限性在于,只能收集到函数调用的初始时刻、以及函数返回的结束时刻的上下文信息。
为了解决这个问题,又提出了一种新方法 Compiled-in instrumentation,可以把探针安插到指定的某行代码中,从而可以收集到那行代码执行时的上下文信息,这种探针被称为 Marker 探针。
编写 Marker 探针,示例如下:
#include <sys/sdt.h>
DTRACE_PROBE(provider, name)
DTRACE_PROBE4(provider, name, arg1, arg2, arg3, arg4)
写好 Marker 探针并成功编译后,可以使用下面的 systemtap 指令来查看 Marker 探针是否生效。
stap -L ‘process(“/path/to/foobar”).mark(“*”)’
详细可以参考 Adding User Space Probing to an Application (heapsort example) 。
其它 #
----- 查找core文件,以及文件类型
find $HOME -name “core*”
/home/oli/core.6440
file core
core: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV), SVR4-style
----- 查看是那个进程信息
strings core.6440 | head
可以在 core_pattern 中加入管道符,然后调用用户程序,例如将转储文件压缩。
echo “|/usr/local/sbin/core_helper %e %p %t” > /proc/sys/kernel/core_pattern
$ cat /usr/local/sbin/core_helper
#!/bin/sh
exec gzip - > /var/$1-$2-$3.core.gz
$ gunzip -c /var/xxx-xxx-xxx.core.gz > ~/xxx-xxx-xxx.core
可以将 ulimit -S -c unlimited > /dev/null 2>&1 使用户登陆时即可以设置转储功能。默认内核会转储共享内存,可以设置排除共享内存。
MySQL #
对于一般进程,要让进程崩溃时能生成 core file 用于调试,只需要设置 rlimit 的 core file size > 0 即可;比如,用在 ulimit -c unlimited 时启动程序。
对 MySQL 来说,由于 core file 中会包含表空间的数据,所以默认情况下为了安全,mysqld 捕获了 SEGV 等信号,崩溃时并不会生成 core file,需要在 my.cnf 或启动参数中加上 core-file 。
[mysqld]
core_file = ON
但是即使做到了以上两点,在 mysqld crash 时可能还是无法 core dump 。
如果程序通过 seteuid()/setegid() 系统调用,改变了进程的有效用户或组,则在默认情况下系统不会为这些进程生成 CoreDump 。简单来说,如果你当初是以用户 A 运行了某个程序,但在 ps 里看到的这个程序的用户却是 B 的话,那么这些进程就是调用了 seteuid 了。
对于 MySQL 来说,无论通过什么用户利用 mysqld_safe 启动,mysqld 的有效用户始终是 mysql 用户;为了能让 MySQL 生成 core dump,需要设置 /proc/sys/fs/suid_dumpable 文件的内容改为 1 。
之后,就可以用 kill -SEGV 让 mysqld 崩溃,测试一下能不能正常产生 core file 了。


















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









