







 本文介绍了Selenium库中的find_element方法,用于在网页中定位元素。通过导入selenium.webdriver.common.by模块,利用By.ID、By.XPATH和By.CSS_SELECTOR等定位方式找到特定元素,例如在百度搜索中输入关键词并点击搜索。示例代码展示了如何打开百度,输入搜索词并执行搜索,最后关闭浏览器。此外,还提及了time.sleep()函数用于延长浏览器的运行时间。
本文介绍了Selenium库中的find_element方法,用于在网页中定位元素。通过导入selenium.webdriver.common.by模块,利用By.ID、By.XPATH和By.CSS_SELECTOR等定位方式找到特定元素,例如在百度搜索中输入关键词并点击搜索。示例代码展示了如何打开百度,输入搜索词并执行搜索,最后关闭浏览器。此外,还提及了time.sleep()函数用于延长浏览器的运行时间。

find_element属于定位元素的一种方法,包含了常用的定位方法。
在使用find——element 时 一定要导入相关的包,不然会报错
from selenium import webdriver
# 一定要导入这个包
from selenium.webdriver.common.by import By
源码如下
def find_element(self, by=By.ID, value=None) -> WebElement:
"""
Find an element given a By strategy and locator.
:Usage:
::
element = driver.find_element(By.ID, 'foo')
:rtype: WebElement
"""
if isinstance(by, RelativeBy):
elements = self.find_elements(by=by, value=value)
if not elements:
raise NoSuchElementException(f"Cannot locate relative element with: {by.root}")
return elements[0]
if by == By.ID:
by = By.CSS_SELECTOR
value = '[id="%s"]' % value
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = ".%s" % value
elif by == By.NAME:
by = By.CSS_SELECTOR
value = '[name="%s"]' % value
return self.execute(Command.FIND_ELEMENT, {
'using': by,
'value': value})['value']
定位
以百度页面为例:
选中搜索框,右键点击检查

本篇一切方法都是基于此。
代码
1.选择要使用的浏览器和搜索网站,以Chrome浏览器和百度为例
driver = webdriver.Chrome()
driver.get("http://www.baidu.com/")
2.以 id 为例
从上面的图可以看到,id 为 “kw”
#搜索框 id 为 kw,向搜索框发送“脱口秀大会进行搜索”
driver.find_element(By.ID, 'kw').send_keys('脱口秀大会')
#百度一下的 id 为 su,然后点击进行搜索
driver.find_element(By.ID, 'su').click()
#关闭浏览器
driver.close()
然后运行浏览器就可以进行搜索了 ,使用完一定要使用driver.close()进行关闭
如果想要界面待得时间长一点,还可以导入包
#包
import time
#8秒后关闭浏览器
time.sleep(8)
driver.close()
3.除了id外,下面这些都可以用来进行查找,用来查找的一定要是唯一的,如果不唯一就会报错,浏览器也会停止在网页首页,不进行查找,id具有唯一性。
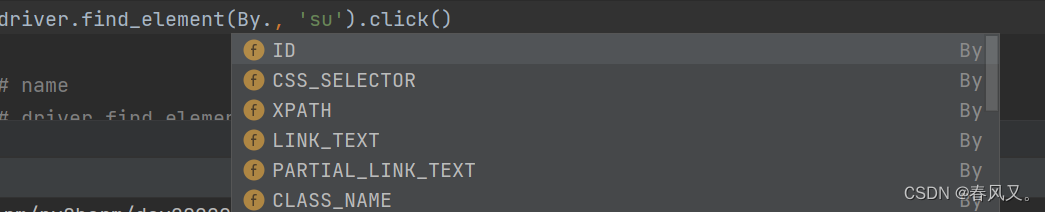
4.用XPATH 和 CSS_SELECTOR查找的本质都是 id查找,所以也是唯一的。
在上面查找的基础上,点击所要查找的id行,右键复制里
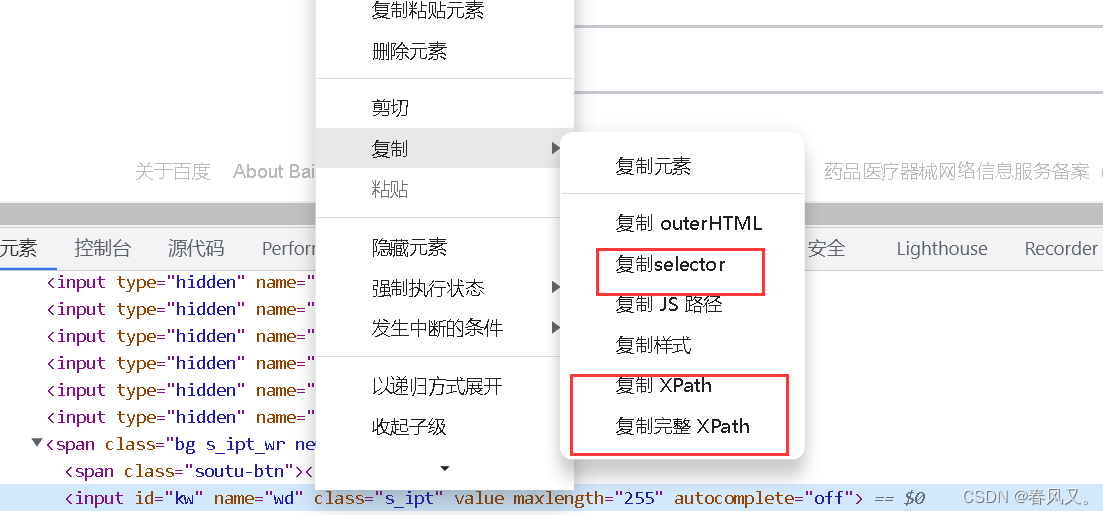
使用同上
# driver.find_element(By.XPATH,'//*[@id="kw"]').send_keys("创造101")
# driver.find_element(By.XPATH, '//*[@id="su"]').click()
driver.find_element(By.CSS_SELECTOR, '#kw').send_keys("qq")
driver.find_element(By.CSS_SELECTOR, '#su').click()

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









