







目录
1 多元线性回归的模型形式
在之前我们研究过的线性回归中,我们只有一个单一特征量----房屋面积x,我们希望用这个特征量来预测房价y ,假设函数是

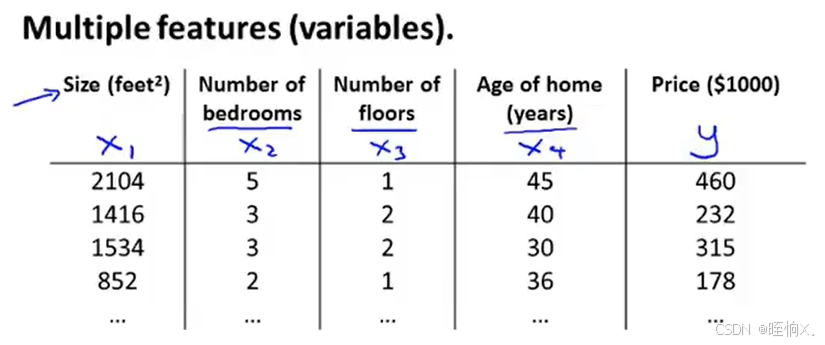
但是现在,我们不仅有房屋面积作为预测房价的一个特征,我们还知道房间数、楼层数以及房子的年代等等,这给了我们更多的信息用来预测房价,我们用变量x1,x2,x3,x4来表示这四个特征,y表示预测的房价。
现在先引入一些概念:
n -------- 特征量的数目,在这个例子中,n=4
----- 第i个训练样本的输入特征值,例如
表示第二个训练样本的特征向量,也就是
,这四个数字对应了用来预测房价的四个特征,
表示一个向量。
------ 第i个训练样本中第j个特征量的值,例如
表示第2个训练样本中的第3个特征量的值,所以
现在我们有了多个特征,让我们来看看模型是什么样子的?
以前,我们是这样定义模型的:,其中x是一个单一特征。现在,我们增加了几个特征,模型是:
。举个具体的例子:在我们设置的参数中,我们可能有
。
我们思考一下,可以怎么解释模型的参数。如果模型试图预测房价,单位为千美元,可以解释为一栋房子的基础价格是8万美元;
表示每增加一平方英尺,价格增加100美元;
表示每增加一间浴室,价格增加4000美元;
,每增加一层楼层,价格增加1万美元;
表示房龄每增加一年,价格减少2000美元。
具有n个特征的模型定义为:
把参数w写成一个向量形式:;特征x也写成向量形式:
,因此模型可以简写成
这种具有多个输入特征的线性回归模型称为多元线性回归,这与只有一个特征的单变量回归形成鲜明对比。
2 向量化
当你实现学习算法时,使用向量化不仅使你的代码更简洁,还会使运行效率大大提高。
让我们看一个向量化具体含义的例子,n=3:
假设参数向量;参数b=4;特征向量
。
在Python中,可以这样使用数组定义变量w,b,x:
w=np.array([1.0,2.5,-3.3])
b=4
x=np.array([10,20,30])
在Python中, 数组的索引计数从0开始,你可以使用w[0]访问向量w的第一个值、w[1]访问第二个值、w[2]访问第三个值;相同的,访问x的各个特征值,也可以使用x[0]、x[1]、x[2]
如果没有向量化,计算模型的预测:,在代码中,是这样的:
f=w[0]*x[0]+w[1]*x[1]+w[2]*x[2]+b
你可以这样写你的代码,但如果此时,而是
或更大时,此时你的代码效率是低下的,计算效率也是低下的。
还有另一种方式:你可以使用求和运算将w和x乘积全部相加,最后加上b ,也就是
在代码中的表示是这样的:
f=0
for j in range(n):
f=f+w[j]*x[j]
f=f+b
以上两种效率都不高,现在我们来看看如何使用向量化来实现这一点:
对于 ,可以通过点积w和x来计算这两个向量的值,最后再加上b。在代码中是这样的:
f=np.dot(w,x)+b
向量化后的好处是:(1)代码简洁。 (2)运行速度更快。
向量化之所以快得多,是因为点积函数利用我们计算机中的并行硬件,加速机器学习任务。
现在,让我们更深入地了解向量化在我们的计算机背后是如何工作的:
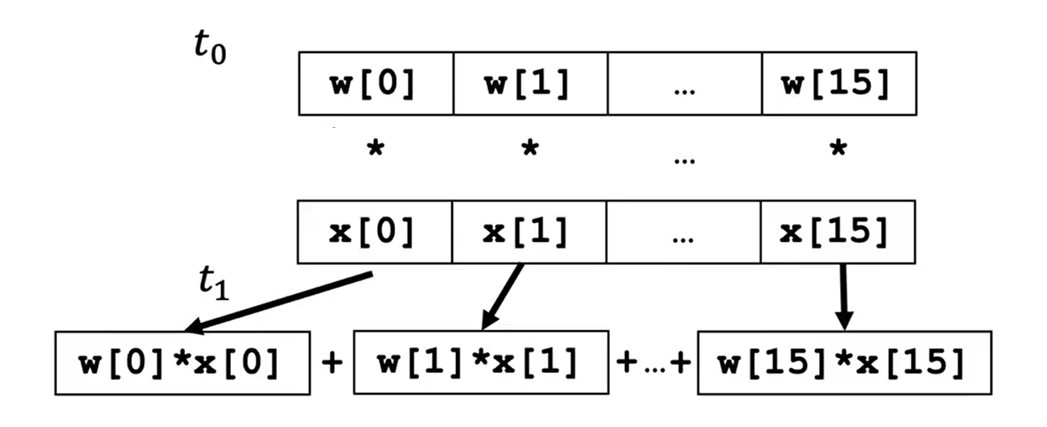
像这样的for循环在没有向量化的情况下运行时:
for j in range(16):
f=f+w[j]*x[j]
在个时间点:计算f=f+ w[0]*x[0]
在个时间点:计算f=f+ w[1]*x[1]
...
在个时间点:计算f=f+ w[15]*x[15]
程序一步步地计算这些运算,一个接一个地运行。
相比之下,Numpy中的np.dot(w,x)这个函数功能是通过计算机硬件中的矢量化实现的。计算机可以获得向量w和x的所有值,并在单一步骤中,同时并行地将每一对w和x相乘;然后,计算机会获取这些计算结果,并使用专门的硬件将它们全部相加。这意味着带有向量化的代码比没有带向量化的代码执行时间更短。
在大型数据集中运行算法或训练大模型时,我们通常使用向量化加快运算速度。这就是为什么向量化的实现,使学习算法得以高效运行的原因。
现在我们来看一个更新梯度下降的具体例子:假如你有一个问题,参数w=(w1,w2...w16),你要为这些参数计算导数项。参数w和导数d的值已经存储在数组np.array中。
w=np.array([0.5,1.3,...3.4])
d=np.array([0.3,0.2,...0.4])
计算公式
如果不使用向量化,你可能会这么做:
...
代码是:
for j in range(16):
w[j]=w[j]-0.1*d[j]
如果使用向量化,就是取向量w中的16个值,并行减去向量d中的16值的0.1倍,然后将这些计算结果同时放回w:
在代码中:
w=w-0.1*d
3 多元梯度下降法
函数f:
参数w视为一个向量: ,参数b仍然是一个数字
代价函数:
梯度下降:重复更新和
......
每次都像这样更新参数,直到找到局部最优点,使得模型收敛。
在线性回归中,除了使用梯度下降算法更新参数外,还可以使用正规方程。
2.1 特征缩放
假设你有一个机器学习问题,这个问题有多个特征,如果你能确保不同特征的取值在相近的范围内,那么梯度下降法就能更快的收敛。
以房价为例,假设我们使用两个特征和
。
。
是房屋面积大小,取值在300-2000平方英尺之间;
是房间数,取值在0-5之间。
现在让我们以一个面积为2000平方英尺,5间卧室,价格为500k美元的房子为例。对于这个训练示例,你认为参数的合理值是多少。让我们看几组参数:
假设,
,
,在这种情况下,以千美元为单位的估计价格
,因此这不是一组好的参数选择。
假设,
,
,
,这组模型参数恰好和房屋的真实价格相同。
基于以上参数选择的例子,我想说的是:当一个特征的可能取值范围很大时(比如房子面积的取值最高可达2000平方英尺),一个好的模型更有可能学会选择一个相对较小的参数值,比如0.1;同样地,当特征的可能值较小时(比如卧室的数量),那么它的参数的合理值将相对较大,比如50
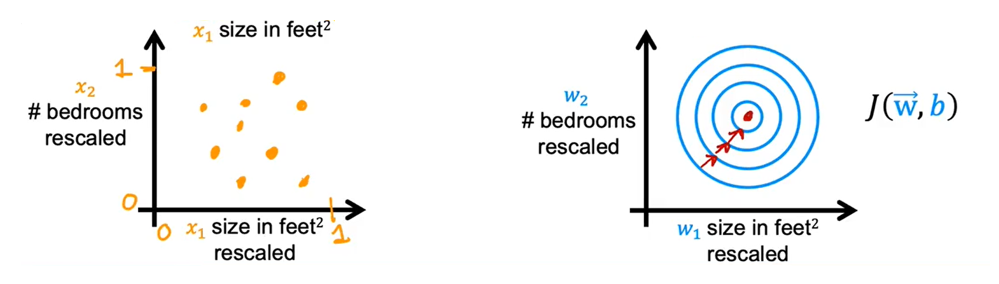
我们来看看特征的散点图:其中横轴表示房子面积,纵轴表示房间数
,如果你在此绘制训练数据,你会发现水平轴的数值比垂直轴的要大很多。我们再看看代价函数在等高线图中呈现的样子:水平轴的范围要比垂直轴的窄很多,所以轮廓是椭圆形。这是因为对
非常小的改变,可能会对预测价格产生非常大的影响,从而对代价函数产生非常大的影响,因为
往往会乘一个非常大的数;相比之下,需要
发生更大的变化才能显著改变预测结果,对
的小幅度调整几乎不会对代价函数产生太大影响。
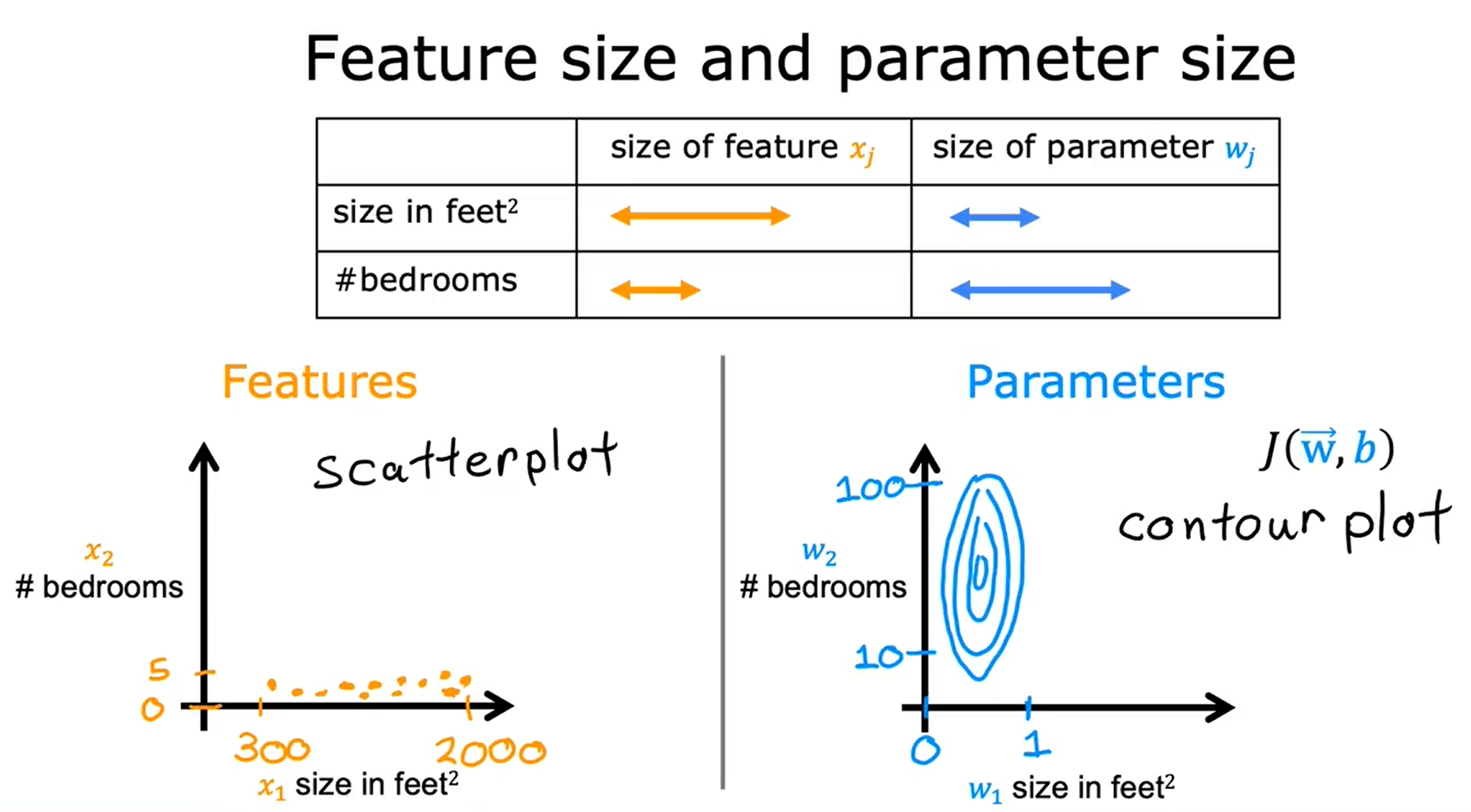
在这种情况下,由于等高线又高又瘦,梯度下降可能会来回反弹很长时间,最终才找到通往全局最小值的路径。
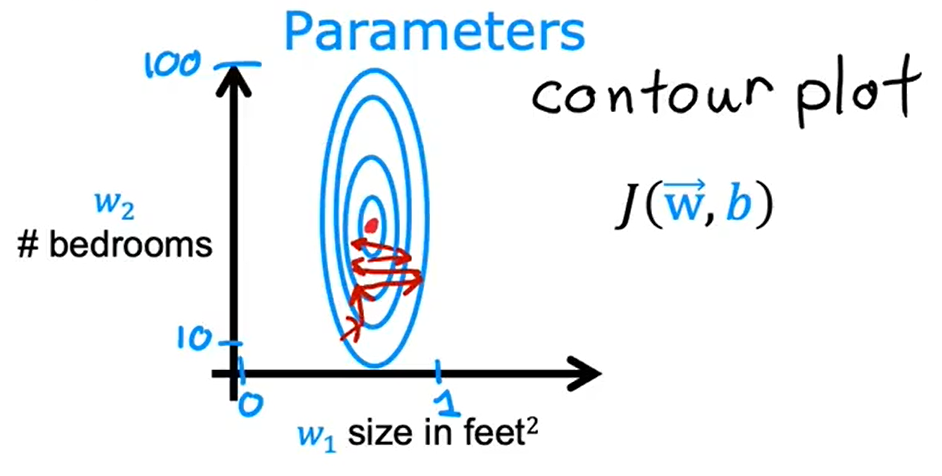
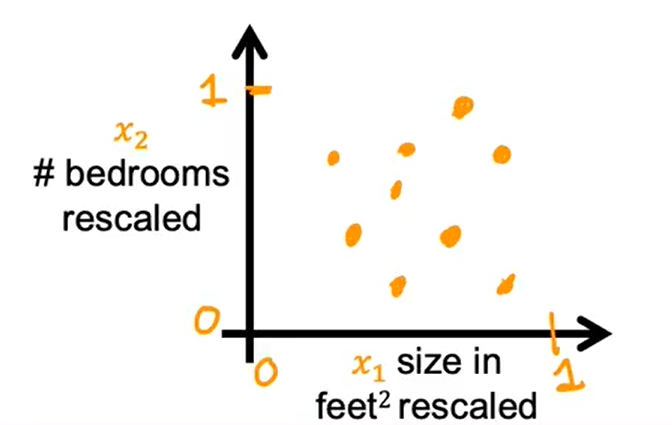
在这样的情况下,一种有效的方法就是进行特征缩放,使得特征的范围在0-1之间,让数据看起来分布均匀。代价函数的等高线图看起来更圆。梯度下将可以找到一条更直接的路径到达全局最小值。
那么我们该如何实现特征缩放?
的范围是
,一种方法是
,即除以范围的最大值,
的范围将缩放至
;同样地,由于
的范围是
,每个
除以范围的最大值,
,
的范围将缩放至
。如果你将缩放后的数据绘制在表上,它看起来可能是这样的:
除了除以范围的最大值以外,我们还可以进行均值归一化:重新调整原始特征,使数据围绕零中心化。
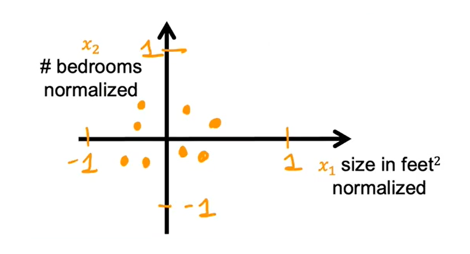
要计算的均值归一化,首先找到训练集
的平均值
,
,
还有一种常见的特征缩放方法----Z-score归一化。你需要计算每个特征的标准差。你需要先计算均值和标准差
,
,
2.2 学习率
梯度下降算法就是找到参数w和b,并且希望他能够最小化代价函数。在梯度下降算法运行时,绘出代价函数
的图。这里的x轴表示梯度下降算法的迭代次数,随着梯度下降算法的运行,可能会得到这样一条曲线,这条曲线显示的是:在运行梯度下降算法迭代后,得到的w和b值所对应的代价函数J的值。如果梯度下降算法正常工作的话,每一步迭代之后,
的值都应该下降。通过这条曲线,可以帮助判断梯度下降算法是否已经收敛。
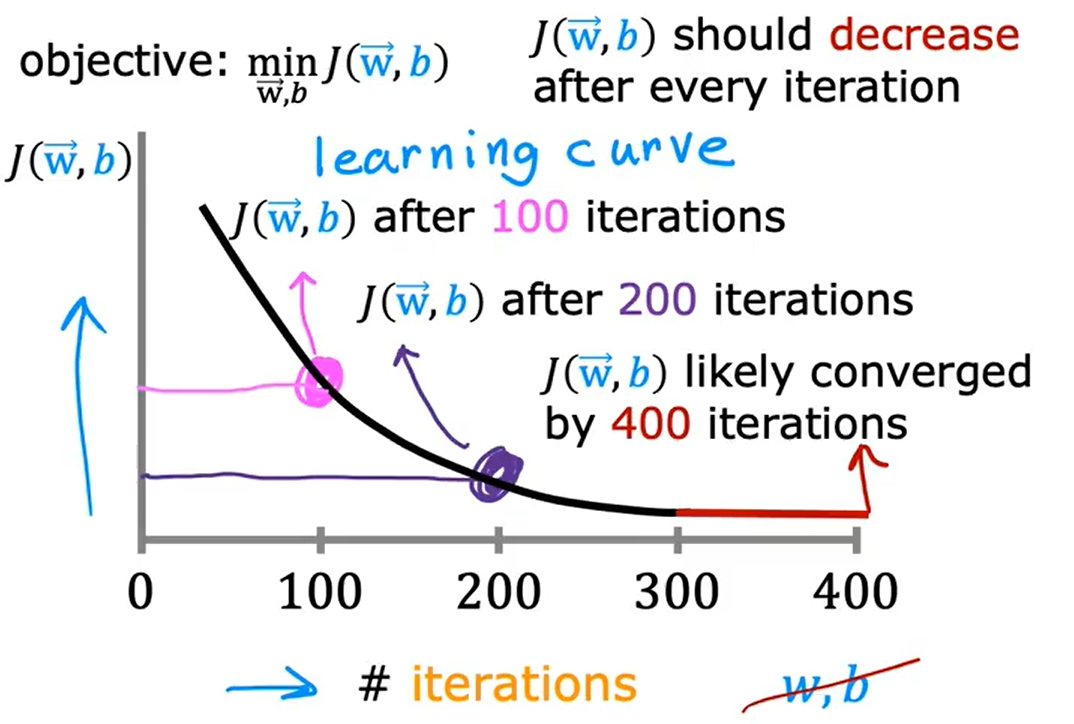
对于每一个特定问题,梯度下降算法所需要的迭代次数可能会相差很大。对于这个问题,梯度下降算法可能只需要30步迭代就可以达到收敛;换个问题,也许梯度下降算法需要3000步迭代;对于另一个问题,可能有需要三百万步迭代。我们很难提前判断梯度下降算法需要多少步才能收敛,我们通常要画出代价函数随迭代步数增加的变化曲线,通过曲线来判断梯度下降算法是否已经收敛。
另外也可以进行一些自动的收敛测试,也就是说让一种算法来告诉你梯度下降算法是否已经收敛。比如:代价函数一步迭代后的下降小于一个很小的值,这个测试就判断函数已经收敛。但通常选择一个合适的阈值
是很困难的。所以为了检查梯度下降算法是否已经收敛,还是更通过看上面这样的图比较好。
看这种曲线图还可以告诉你或提前警告你算法没有正常工作。
如果你看到代价函数随迭代步数的变化曲线是下图这样的,这就表明梯度下降算法没有正常工作。这意味着你应该使用较小的学习率
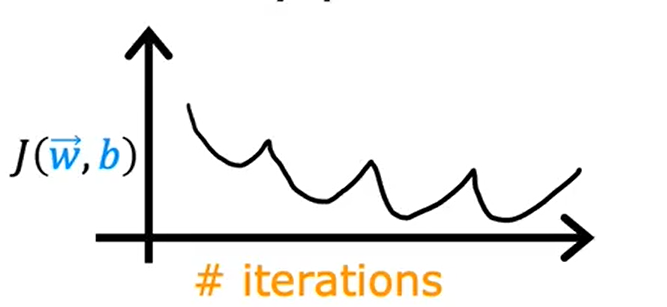
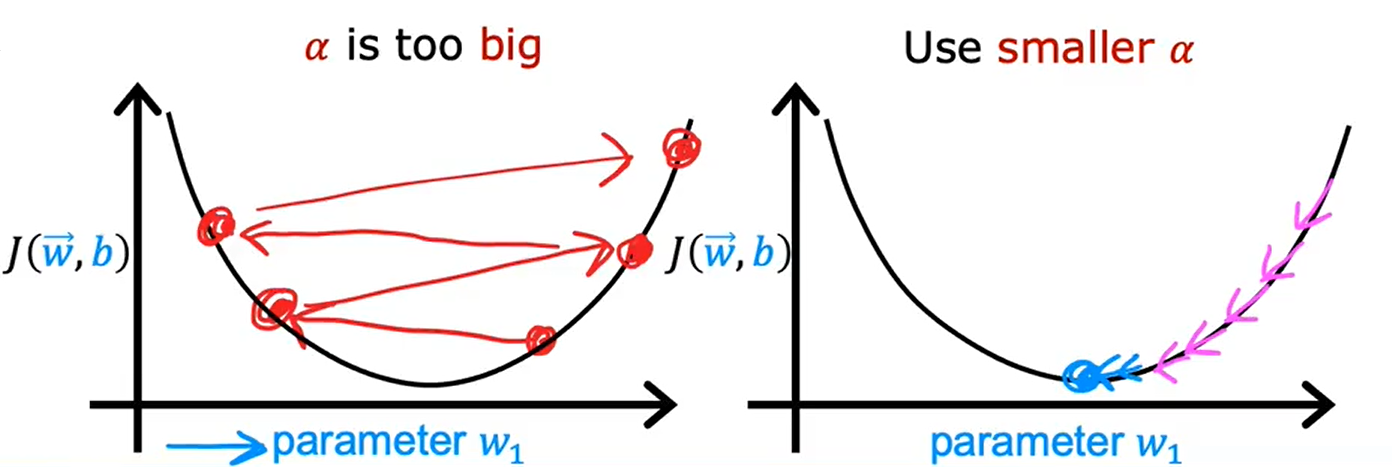
如果你看到代价函数随迭代步数的变化曲线是下图这样的,可能是由于学习率太大导致的,需要选择较小的学习率来解决。
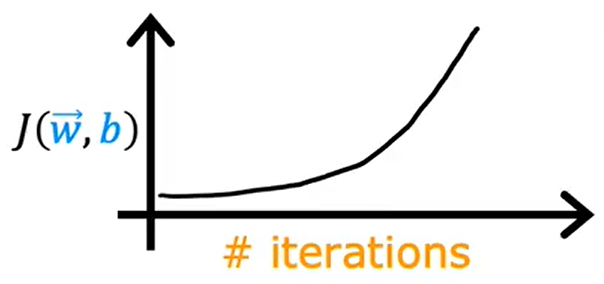
如果学习率太小的话,收敛速度慢;如果学习率太大,代价函数可能不会在每次迭代都下降,甚至可能不收敛。为了调试所有的情况,通常绘制代价函数随迭代步数变化的曲线。
一个正确实现梯度下降的调试技巧是:当使用足够小的学习率时,代价函数在每次迭代中都下降。如果梯度下降法不起作用,可以将学习率设成一个很小的值,看看是否会在每次迭代后,代价下降;如果将学习率设置成一个很小的值,代价函数的值在每次迭代后并不总是减少,反而有时会增加,这意味着代码中某处存在错误。
我们通常会尝试一系列的值,比如0.001 ,0.003, 0.01,0.03, 0.1,0.3,1 ,然后对于这些不同的
值绘制代价函数随迭代步数变化的曲线,选择使得代价函数
值快速下降的一个
值。
4 特征工程
特征的选择会对学习算法性能产生巨大影响。选择或输入正确的特征是使算法良好运行的关键步骤。我们来看看如何为学习算法选择或设计最合适的特征。
我们重新审视预测房价的例子来看看特征工程:假设每栋房子有两个特征,是房屋所建地块的宽度,
是地块的深度。

根据这两个特征,
,你可能会构建 一个这样的模型,其中
,这个模型可能不错。你可能注意到房子的面积
,或许用面积会比单独用宽度和深度更能预测价格。这是你可能会定义一个新特征
,
表示地块的面积。因此可以定义一个新模型
,这个模型可能会比之前定义的模型更好。
刚才所做的创建新特征,就是特征工程的例子。特征工程:通过转换或组合问题的原始特征,根据直觉或已有的知识去设计新的特征,以便使学习算法更容易做出精确的预测。
特征工程不仅允许你拟合直线,还可以拟合非线性函数到你的数据上。
采用多元线性回归和特征方程提出一个新的算法,称为多项式回归,它可以拟合曲线或非线性函数。
假设你有一个住房数据集,看起来是这样的,其中特征x表示房子的面积,直线似乎不太适合拟合数据,你可以用曲线来拟合数据,这个模型可能是: ;但是随后你又考虑到二次函数会在某一个x点开始下落,而随着房子面积x的增加,房价是要上升的,这时你会选择三次函数
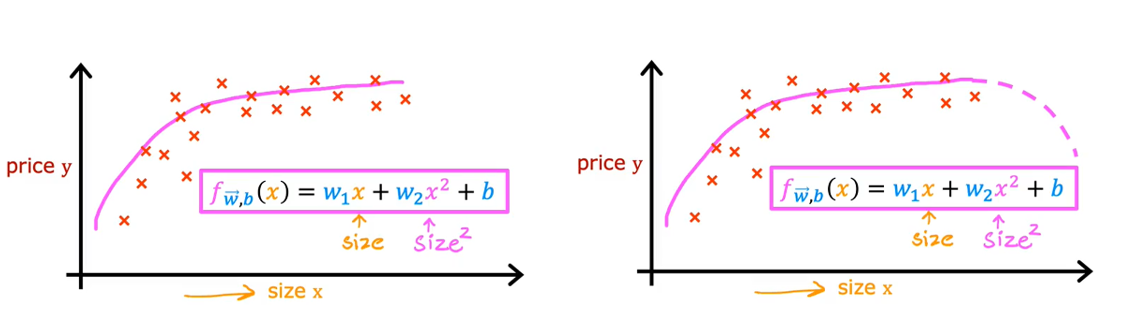
如果你创建的是多次方的函数模型,那么特征缩放就很重要了。如果房子的范围在1-1000平方英尺,那么范围就是一到一百万,
的范围就是一到十亿。它们之间的范围相差太多,要使用特征缩放把它们的特征值调整到合适的范围。
另一种方案:你可以使用,此时模型就是:
,这也是另一个可能对此数据集也有效的特征选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









