







-
论文标题:Boosting Self-Supervision for Single-View Scene Completion via Knowledge Distillation
-
论文地址:https://ieeexplore.ieee.org/document/10657421
-
GitHub 主页:https://github.com/keonhee-han/KDBTS
-
来源:2024年发表于CVPR
背景知识
- 场景重建:从图像中推断场景的几何结构是计算机视觉中的一个长期问题。传统方法依赖于多张图像和关键点匹配,而深度学习方法则通过单目深度估计(MDE)从单张图像预测深度图。
- 场景补全:与仅关注可见部分的深度图不同,场景补全旨在推断场景的完整几何结构,包括被遮挡的区域。
- 神经辐射场(NeRF):近年来,NeRF通过预测密度场和视图依赖的颜色,允许通过图像渲染进行新视图合成,但原始NeRF无法泛化到不同场景,且几何结构不准确。
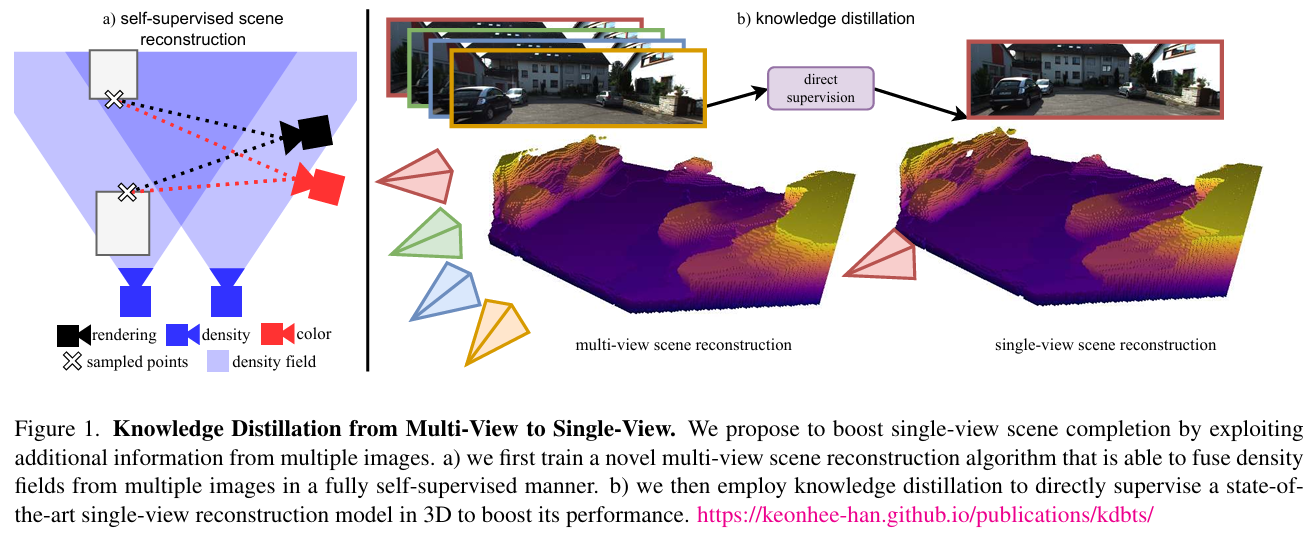
图1展示了从多视图到单视图的知识蒸馏过程,具体包括两个主要步骤:
-
多视图场景重建(MVBTS):首先训练一个新颖的多视图场景重建算法,能够以完全自监督的方式融合来自多个图像的密度场。这一步通过利用多张图像的信息,提高了场景重建的准确性。
-
知识蒸馏(KDBTS):然后利用知识蒸馏技术,将多视图场景重建的结果直接监督到单视图场景补全模型中,从而提升其性能。这一步通过将多视图模型的预测结果作为伪监督,训练单视图模型,使其能够在只有单张图像的情况下进行更准确的场景补全。
图1通过示意图的形式,直观地展示了如何通过多视图信息来提升单视图场景补全的性能,强调了知识蒸馏在这一过程中的关键作用。
研究方法
- 多视图场景重建(MVBTS):作者提出了一种新的多视图场景重建算法,能够从多张图像中融合密度场,且仅使用图像数据进行完全自监督训练。
- 知识蒸馏(KDBTS):利用MVBTS的场景重建结果,通过知识蒸馏直接监督单视图场景补全模型,提升其性能。
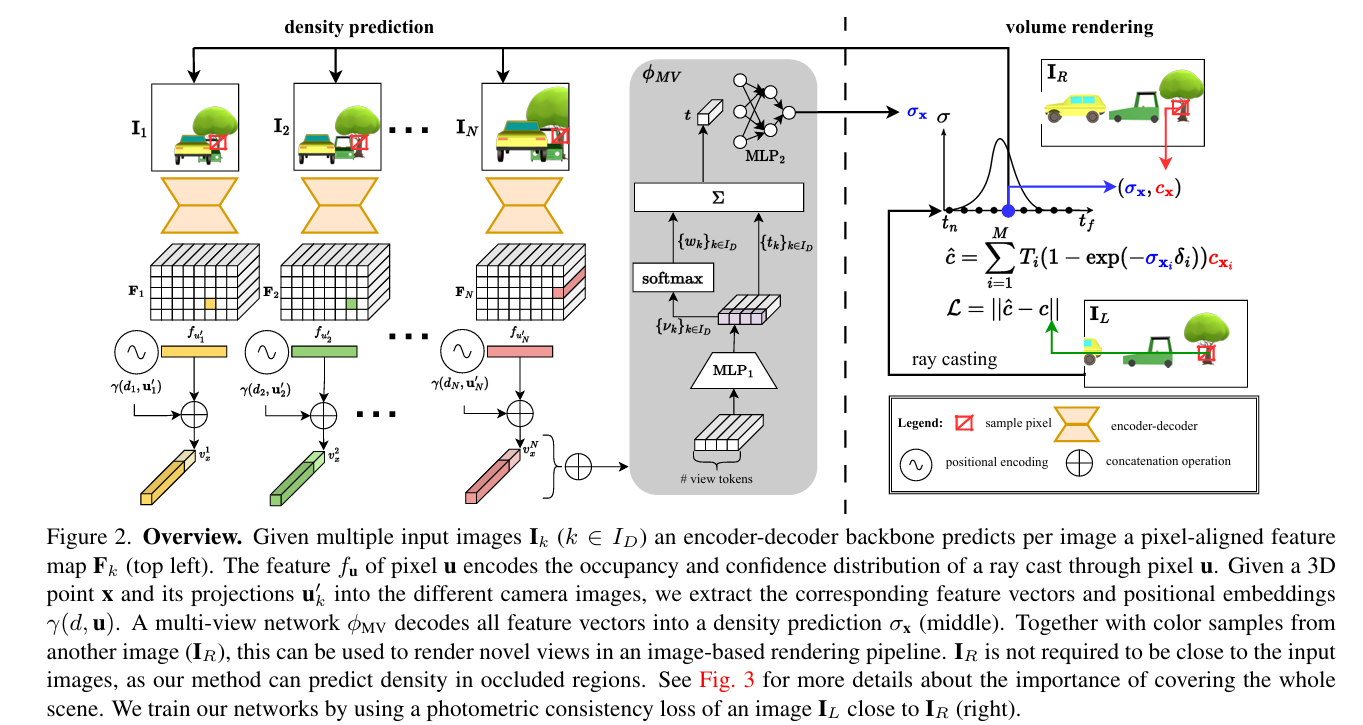
MVBTS的具体方法
- 编码器-解码器架构:对于每张输入图像,使用编码器-解码器架构预测像素对齐的特征图。
- 多视图聚合:对于一个3D点,将其投影到所有输入图像中,提取对应的特征向量,并通过一个小的多层感知机(MLP)解码密度预测。
- 置信度加权:使用softmax层将置信度值转换为权重,进行加权求和,得到聚合的特征向量,再通过第二个MLP解码得到密度估计。
训练方法
- 体积渲染:使用可微的体积渲染管道重建图像,利用光度一致性损失训练网络。
- 颜色采样:从其他图像中采样颜色,而不是直接预测颜色。
- 损失函数:结合L1损失和SSIM损失,以及边缘感知平滑度损失。
KDBTS的具体方法
- 知识蒸馏:通过L1损失将MVBTS的密度预测作为伪监督,训练单视图模型。
- 模型架构:KDBTS使用与MVBTS相同的编码器-解码器架构,但解码器稍小,以减少模型大小并加快推理速度。
实验
- 数据集:使用KITTI和KITTI-360数据集进行评估,这些数据集提供了时间戳的立体图像和地面真实姿态。
- 深度预测:在KITTI数据集上,与自监督深度预测方法和体积重建方法进行比较,KDBTS和MVBTS的性能与BTS相似。
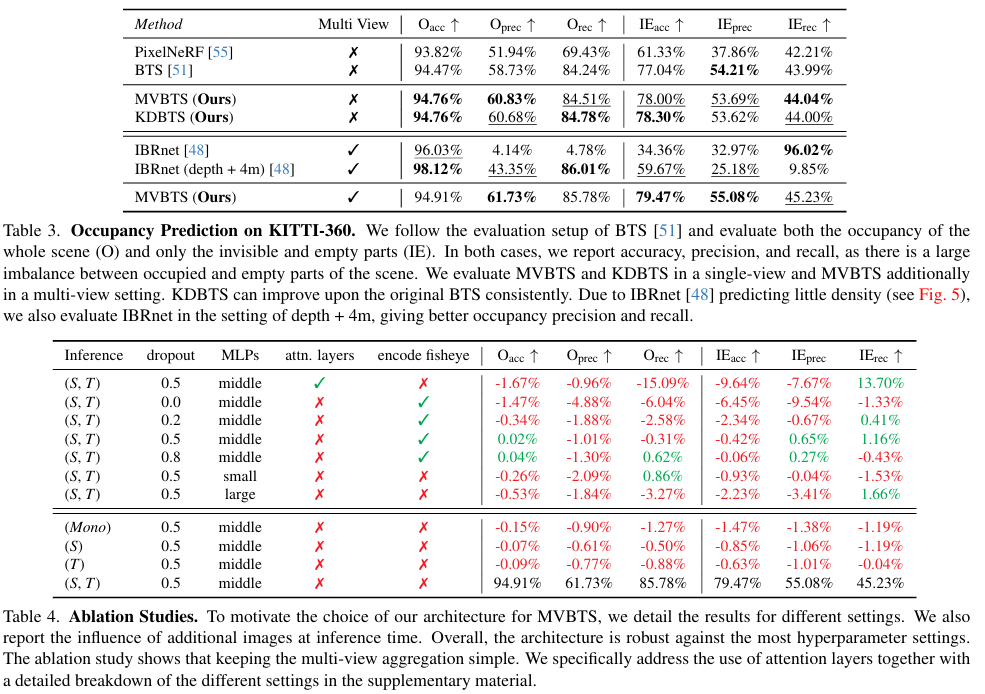
- 占用预测:在KITTI-360数据集上,与PixelNeRF、BTS和IBRnet进行比较,KDBTS和MVBTS在大多数指标上优于BTS,且KDBTS在单视图设置下表现最佳。
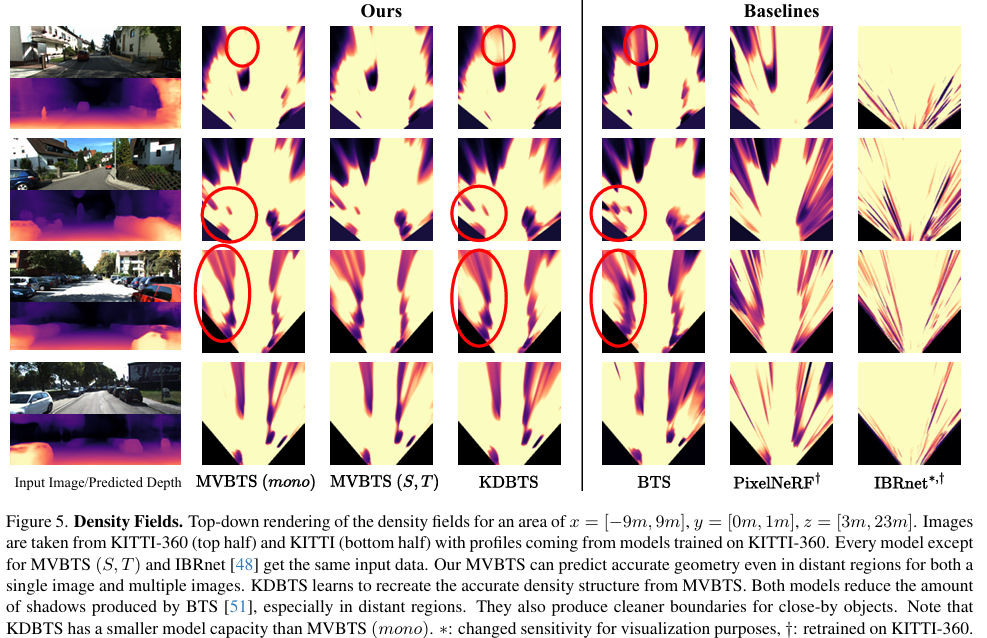
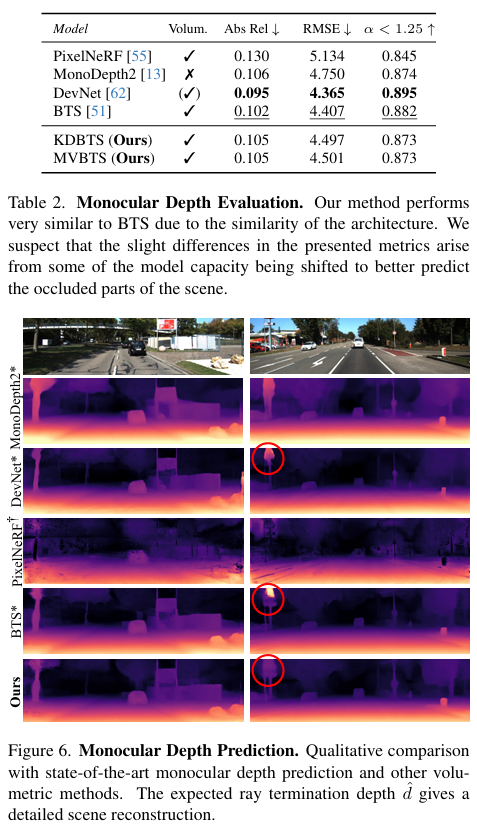
关键结论
- 性能提升:通过多视图信息的利用,KDBTS在单视图场景补全任务上达到了最先进的性能。
- 自监督训练:整个训练过程仅使用图像数据,无需额外的3D标注,使得方法可扩展到大量数据。
- 知识蒸馏的有效性:通过知识蒸馏,单视图模型能够从多视图模型中学习到更准确的场景几何结构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









