







1.介绍
numpy库是python对矩阵操作的库,接下来每天我会发表一篇对numpy的介绍,直到完结。
2.ndarray类型
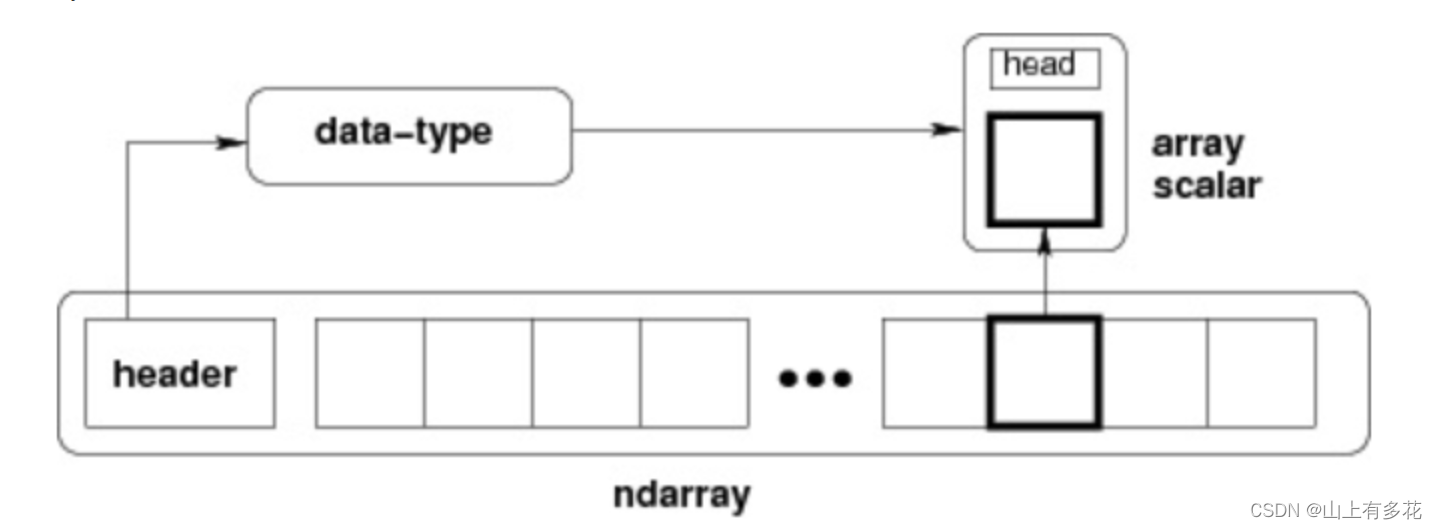
numpy 最重要的类型是N 维数组对象 ndarray。而ndarray内含有什么呢?
(1)一个指向数据的指针。
(2)数据类型(dtype)。
(3)一个表示数组形状(shape)的元组。
(4)一个跨度元组(stride)
内部结构如下图所示:
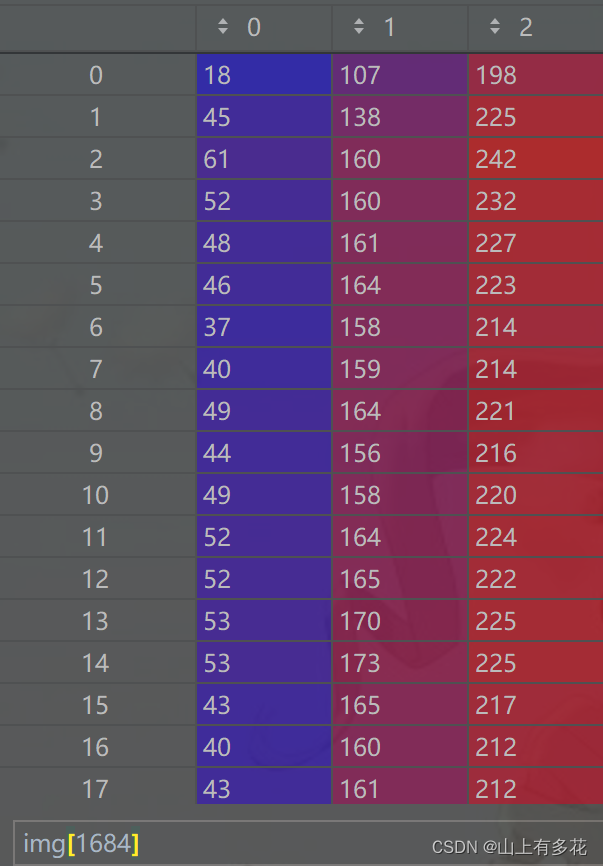
为了更好的说明,这儿举个小例子,如下图所示,这个img变量表示一张图片,大小为(1685,1007,3)。

我们这个时候有三种访问数据的方式(其实是指针的运用)
#1.最外层访问 (相当于单指针,访问结果为1007*3个数据)
img[0] ~ img[1684]
#2.次外层范问 (相当于二重指针,范问结果为3个数据)
img[0][0] ~ img[0][1006]
img[1684][0] ~ img[1684][1006]
#最外层访问 (相当于三重指针,范问结果为单个像素)
img[0][0][0]
img[1684][1006][2]下图为使用pycharm 查看数据的图

3.数据类型(dtype)
numpy数据类型比较多,其中为了区别bool、int、float、complex这些python内置类型,numpy中特意在后面加入_来区分,总结为下面的表格。
| 名称 | 描述 |
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型 |
| intp | 用于索引的整数类型 |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8/uint16/uint32/uint32 | 无符号整数 |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数 |
| float32 | 单精度浮点数 |
| float64 | 双精度浮点数 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
| datatime54 | 时间类型 |
4.区分dtype、astype、shape、ndim、size
(1)dtype :ndarray对象的内置函数,可以获得数据类型
(2)astype: 转化数据类型
(3)shape:获得各维度的尺度
(4)ndim: 获得数组的维度,结果是1个整形
(5)size : 获得数组元素的个数
上例子
a=np.array([[1.2,2.41,1.2,1.3],[4.2,5.1,6.4,2.3],[23,11,1.1,2.4]]) #创建矩阵,后面写
print('ndim={}\nshape={}\ndtype={}'.format(a.ndim,a.shape,a.dtype))
b=a.astype(np.int32) #转为int型,会截断数据
print(b)
"""
结果如下:
ndim=2
shape=(3, 4)
dtype=float64
[[ 1 2 1 1]
[ 4 5 6 2]
[23 11 1 2]]
"""
ps:今天先写这些,觉得写的还不错的给个赞呗.
错误是难免的,如果有错误的地方,请联系我。


















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











