







1.文章介绍

-
论文出处:PVLDB 2022(数据库领域三大顶会之一)
-
【摘要】:对多变量时间序列进行聚类是现实世界中涉及多个信号和传感器的许多应用中的一项关键任务。现有系统旨在最大限度地提高有效性、效率和可扩展性,但却无法保证结果的可解释性。这阻碍了它们在需要人类理解算法行为的关键真实场景中的应用。本文介绍了用于多变量时间序列(MTS)聚类的端到端机器学习系统 Time2Feat。该系统依赖于从时间序列中提取的信号间和信号内可解释特征。然后,采用降维技术选择保留大部分信息的特征子集,从而提高结果的可解释性。此外,领域专家可以通过提供少量具有目标群集的 MTS,对这一过程进行半监督。这一过程进一步提高了准确性和可解释性,缩小了聚类过程中使用的特征数量。我们通过在 18 个基准时间序列数据集上的实验,证明了 Time2Feat 的有效性、可解释性、效率和鲁棒性,并将它们与最先进的 MTS 聚类方法进行了比较。
2.问题背景
- 目前时间序列聚类的研究主要集中在单变量时间序列,而多元时间序列的研究还处在早期阶段,多元时间序列一般使用降维技术后再使用单元时间序列聚类算法
3.拟解决的问题
-
使用降维技术对多元时间序列进行处理然后再聚类,会丢失原始维度,从而导致产生的类簇可解释性差。本文对序列的信号内特征和信号间特征进行选择,提取有用的特征,降低计算复杂度。同时基于统计角度可以描述多元时间序列的特征,以实现聚类的可解释性。
-
分析 MTS 数据集需要应用能够处理高维度数据的可扩展技术
-
提供可解释的聚类技术
-
在数据分析的聚类过程中如何把人置于循环中,即将无监督过程扩展为半监督
4.主要贡献
-
提出了一个可解释且高效的多变量时间序列端到端的聚类系统Time2Feat
-
可扩展性高,模型允许领域专家提供少量且可控的标签作为过程的输入,以提高聚类的准确性并控制提取的特征集的大小
-
相较于FeatTS,Time2Feat研究的是多元时间序列聚类,后者利用变量内的特征和变量间的特征,从多个角度对时间序列进行聚类
5.提出的方法
-
模型框架:
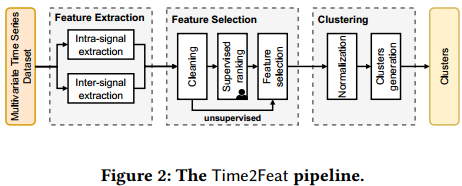
-
定义:
-
多元时间序列:多元时间序列 M = ( u 1 , u 2 , . . . , u S ) M=(u_1,u_2,...,u_S) M=(u1,u2,...,uS)是一组单变量时间序列(信号),其中S是信号的数量, u j = ( t 1 j , t 2 j , . . . , t N j ) u_j=(t_{1j},t_{2j},...,t_{Nj}) uj=(t1j,t2j,...,tNj)是长度为N的时间序列,更一般地,可以把多元时间序列表示为矩阵 R N × S \mathbb{R}^{N\times S} RN×S
其中信号被描述为列向量。 -
多元时间序列数据集:一个多元时间序列数据集D是一组V个多元时间序列 D = ( M 1 , M 2 , . . . , M V ) D=(M_1,M_2,...,M_V) D=(M1,M2,...,MV),一个数据集表示为张量 R V × N × S \mathbb{R}^{V\times N \times S} RV×N×S
-
信号内特征集:给定一个由S信号组成的多元时间序列M, M = ( u 1 , u 2 , . . . , u S ) M=(u_1,u_2,...,u_S) M=(u1,u2,...,uS)和一组用于信号内特征提取的函数 F = ( f 1 , f 2 , . . . , f F ) \mathcal{F}=(f_1,f_2,...,f_F) F=(f1,f2,...,fF),a信号内特征集是将函数应用于信号所产生的值集
F i n t r a = ( e 11 , . . . , e 1 F , . . . , e S 1 , . . . , e S F ) F_{intra}=(e_{11},...,e_{1F},...,e_{S1},...,e_{SF}) Fintra=(e11,...,e1F,...,eS1,...,eSF),其中 e i j = f i ( u i ) e_{ij}=f_i(u_i) eij=fi(ui) -
信号间特征集:给定一个由S信号组成的多元时间序列M, M = ( u 1 , u 2 , . . . , u S ) M=(u_1,u_2,...,u_S) M=(u1,u2,...,uS)和一组用于信号内特征提取的函数 F ′ = ( f 1 ′ , f 2 ′ , . . . , f F ′ ) \mathcal{F^{'}}=(f_1^{'},f_2^{'},...,f_F^{'}) F′=(f1′,f2′,...,fF′),一组信号间特征是将函数应用于信号对所产生的一组值。 F i n t e r = ( e ( 1 , 2 ) 1 , . . . , e ( 1 , S ) F ′ , . . . , e ( S − 1 , S ) F ′ ) F_{inter}=(e_{(1,2)1},...,e_{(1,S)F^{'}},...,e_{(S-1,S)F^{'}}) Finter=(e(1,2)1,...,e(1,S)F′,...,e(S−1,S)F′),其中 e ( i , j ) k = f K ′ ( u i , u j ) e_{(i,j)k}=f_K^{'}(u_i,u_j) e(i,j)k=fK′(ui,uj)
5.1特征抽取
-
伪代码:

-
信号内特征提取:利用tsfresh库计算700多个特征,其中每一个特征都从特定分析方法(分布分析、统计分析)提供的角度对信号描述进行编码
-
信号间特征提取:通常都使用神经网络提取特征,但是这样会获得无法解释的描述。这里采用8个指标(相关性、欧式距离等)测量信号对之间的相关性的度量
5.1特征选择
-
伪代码:

-
模型首先进行数据清洗,包括删除所有零方差特征和具有缺失值或无限值得特征。然后依靠方差分析 (ANOVA) 来计算与每个特征相关的 p 值并量化其重要性。然后,我们应用网格搜索分析来识别可最大化生成集群质量的特征子集。本文应用 PFA 技术来选择最有意义的特征。PFA 技术通过选择“在低维空间中特征最大可变性的意义上保留大部分信息的主要特征”,不仅保证了特征的简洁性,而且保证了特征的多样性。
5.3聚类
- 聚类操作包括一个归一化步骤,避免了由于大规模域范围而导致的特征支配。然后使用传统的聚类方法(如k-means、谱聚类、层次聚类)进行聚类
6.实验
6.1模型设置
-
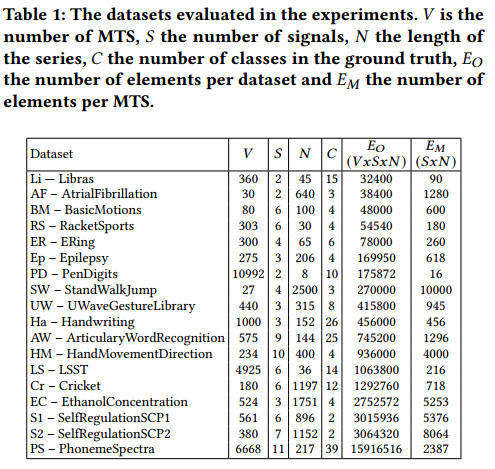
数据集:UEA 多元时间序列数据集中的 18 个数据集
-
baseline:
- Hierarchical
- KMeans
- Spectral
- CSPCA 和𝑀𝐶2𝑃𝐶𝐴 :引入了一种基于 PCA 的机制来在聚类之前降低数据维度
- DETSEC通过自动编码器为序列创建嵌入
- IT-TSC通过将多路径神经网络与变量关联图相结合来确定每个集群的信号重要性
- DTW
- 实验设置:所有实验都进行了十次,并报告了平均结果加上标准差
6.2实验结果
-
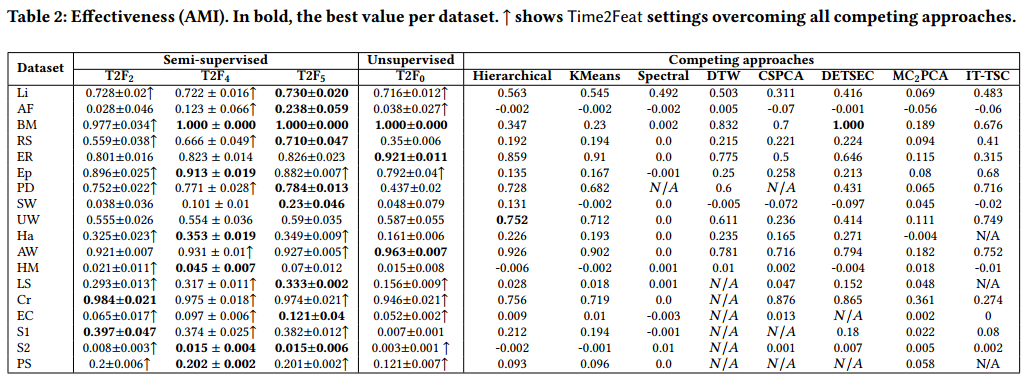
实验对比结果:
-
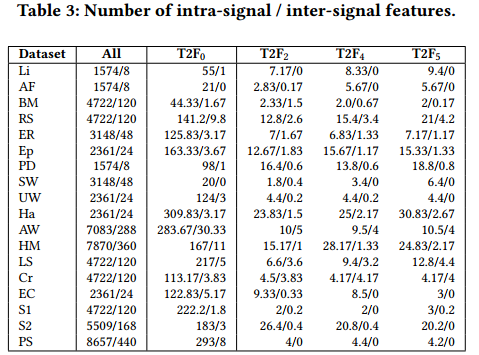
特征提取结果:
监督的增加并不总是对应于特征的减少。文中将此解释为一种“过度拟合”,它通过添加特征来强制获得更好的准确性结果。然而,可以观察到在所有半监督设置中保留的少量特征(它们可以由人类管理)。最后,实验表明了信号间特征的重要性。尽管数量很少,但提取的信号间特征在几乎所有 Time2Feat 设置中都得到了保留,从而显示了它们在聚类过程中的重要性。
-
运行时间对比:
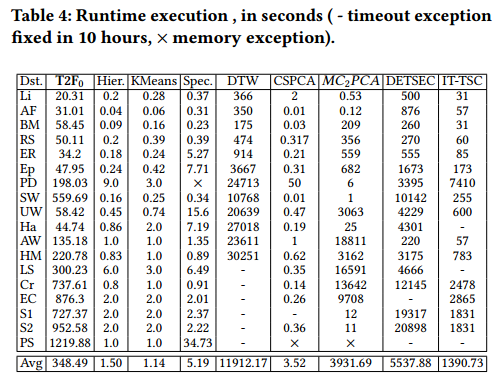
-
不同聚类方法对比:
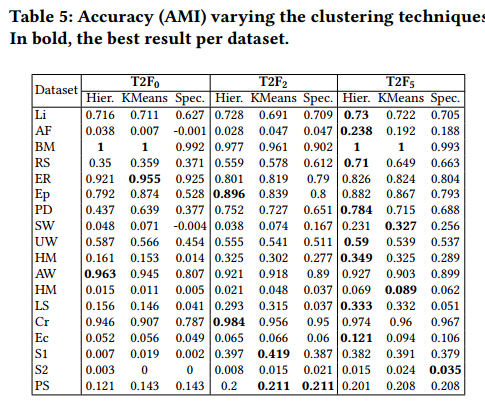
-
特征选择的重要性:图 4a 显示了模型的准确性 (AMI)、图 4b 显示了模型的可解释性(特征数量)以及图 4c 显示了模型的效率在管道中选择和不选择特征时的变化。
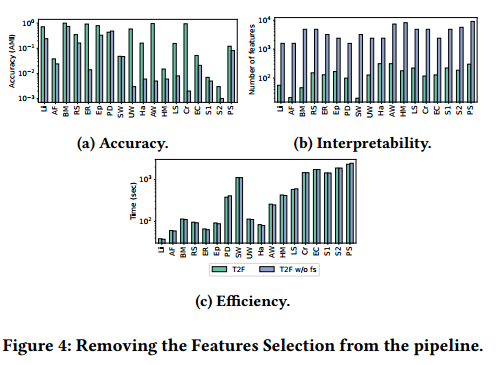
-
原始聚类方法和特征提取后的方法对比:
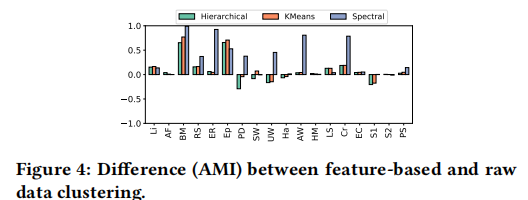
7.结论
-
可解释性通常以两种方式实现 :1) 通过利用事后分析或 2) 通过设计本质上可解释的系统。 Time2Feat 属于第二类,基于可解释的特征。
-
聚类技术的可解释性通常被以下三种方式解决:(1)通过应用降维技术(例如,PCA)能够通过两个或三个维度可视化聚类; (2)通过识别质心或一组选定的点来表示集群; (3) 依靠可解释模型(通常是决策树)来学习如何对生成的集群进行分类。本文主要处理可解释的表示,它可以支持用户理解集群的内容。尽管相关文献中没有就可解释特征的含义以及可解释特征应满足哪些属性达成共识,但有几种方法表明简洁性是解释算法行为的关键属性之一
-
本文从有效性、可解释性、效率和稳健性的角度对 Time2Feat 进行了实证研究,并将其与几个真实世界和基准数据集上的现有聚类方法进行了比较。结果表明,可解释的特征和弱标记的 MTS 的组合导致所获得的聚类的质量和可解释性更好。
8.个人观点
-
本文提出的方法和FeatTS模型有相似之处,都是对特征进行处理,先提取特征再对特征进行选择,但是不同之处在于,FeatTS处理的是单元时间序列,而Time2Feat处理的是多元时间序列,故后者考虑了变量之间的特征关系,另外FeatTS使用社区检测算法,模型稍微复杂一点,但是两者最后都是使用传统聚类算法进行聚类
-
提供了几个MTS聚类的baseline,也对今后做可解释性的时间序列聚类算法提供了思路
9.附录
-
(RQ1) 由于这些特性,我们获得了效率。 5.1 节中的实验表明 Time2Feat 提供了比其竞争对手更准确的集群。 5.4.3 节中的消融测试进一步证实,基于特征的聚类技术比使用原始数据的技术产生更有效的结果。
-
(RQ2) 集群表示简洁。 5.2 节中的实验表明 Time2Feat 依赖于少量特征来生成簇,并显示了在簇生成过程中保留信号间特征的重要性。
-
(RQ3) 基于特征的聚类实现了准确性和性能之间的权衡。 Time2Feat 在大多数数据集中实现了最佳准确性以及良好的性能。该方法是最快的方法之一,可在几秒钟内执行,因此可有效地用于批量分析(第 5.3 节)。管道组件的研究时间分解表明,特征提取阶段是最昂贵的(第 5.3.2 节)。尽管如此,可以快速开发用于优化工作负载平衡的启发式方法,例如,关于可用处理器(第 5.3.3 节)的方法,以大大减少整体执行时间。
-
(RQ4) 管道是健壮的和可扩展的。该管道是高度模块化的,然后可根据实际环境的特殊性进行扩展。我们的稳健性分析显示了所有管道组件的重要性。特征选择(第 5.4.1 节)提高了准确性和可解释性。聚类技术的比较显示了管道的适应性,允许根据手头的用例在小型和大型数据集的准确结果之间取得平衡(第 5.4.2 节)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









