




1. 摘要
本模型主要功能如下:
(1) 对肺炎图片,利用二维小波变换提取小波域特征;面对多个图像采用PCA即主成分分析法降维。
(2) 构建并训练随机森林模型,通过剪枝、控制树深度等操作降低模型大小并提升精度。
(3) 用十字交叉验证,计算平均正确率。
本文代码采用:MATLAB语言;运行平台:MATLAB2018b
数据集采用 单通道 黑白CT图片,图片后缀为 jpeg(图片内容,图片后缀都可修改,需要定制或添加功能 +q 3388456247)
2. 代码思路
2.1 数据准备阶段
- 定义训练(train)、验证(val)和测试(test)文件夹路径,每个文件夹包含两个子文件夹(NORMAL和PNEUMONIA)。
- 读取文件:使用
dir函数读取每个文件夹中的图像文件。 - 初始化特征向量集:为每个文件夹中的图像准备一个特征向量集。
% 设置文件夹路径
% 设置存放训练数据的文件夹路径
train_folder = 'F:\xxx\train';
% 设置存放验证数据的文件夹路径
val_folder = 'F:\xxx\val';
% 设置存放测试数据的文件夹路径
test_folder = 'F:\xxx\test';
% 读取训练文件夹中所有的JPEG文件
% 构建NORMAL类别训练数据的完整路径
train_normal_folder = fullfile(train_folder, 'NORMAL');
% 构建PNEUMONIA类别训练数据的完整路径
train_pneumonia_folder = fullfile(train_folder, 'PNEUMONIA');
% 读取NORMAL类别训练文件夹下所有的JPEG文件
train_normal_files = dir(fullfile(train_normal_folder, '*.jpeg'));
% 读取PNEUMONIA类别训练文件夹下所有的JPEG文件
train_pneumonia_files = dir(fullfile(train_pneumonia_folder, '*.jpeg'));
% 计算NORMAL类别训练数据的图片数量
num_train_normal_images = length(train_normal_files);
% 计算PNEUMONIA类别训练数据的图片数量
num_train_pneumonia_images = length(train_pneumonia_files);
2.2 训练数据处理
- 对于训练文件夹中的每张图像:
- 读取图像文件。
- 若图像是彩色的,则转换为灰度图像。
- 提取灰度共生矩阵(GLCM)特征,并计算GLCM的统计特征(对比度、相关性、能量、一致性),将这些特征保存到训练特征向量集中。
(ps:验证、测试数据思路相同。不再重复介绍,粘贴代码)
% 遍历训练文件夹中NORMAL类别的每个图像
for i = 1:num_tran_normal_images
% 拼接图像文件名和路径
filename = fullfile(train_normal_folder, train_normal_files(i).name);
% 读取图像文件
img = imread(filename);
% 判断图像是否为彩色图像(如果图像的第三个维度大小为3,则为彩色图像)
if size(img, 3) == 3
% 如果图像是彩色的,将其转换为灰度图像
img = rgb2gray(img);
end
% 提取灰度共生矩阵(GLCM)特征
% 使用[0 1]的偏移量,并且要求矩阵是对称的
glcm_features = graycomatrix(img, 'Offset', [0 1], 'Symmetric', true);
% 从GLCM特征中提取统计属性:对比度(Contrast)、相关性(Correlation)、能量(Energy)和同质性(Homogeneity)
stats = graycprops(glcm_features, {'Contrast', 'Correlation', 'Energy', 'Homogeneity'});
% 将提取的特征保存到feature_vectors矩阵的当前行中
% 假设feature_vectors_train已经是一个足够大的矩阵,用于存储所有特征向量
feature_vectors_train(i:) = [stats.Contrast, stats.Correlation, stats.Energy, statsHomogeeity];
end
2.3 使用主成分分析(PCA)进行降维
- 将所有数据集的特征向量合并为一个大的特征矩阵。
- 对特征矩阵进行主成分分析(PCA),将特征向量降维为指定数量的主成分。
- 将降维后的特征向量分割回训练、验证和测试集的特征向量。
% 使用主成分分析(PCA)进行特征降维
% num_components 变量定义了希望保留的主成分数量,这里假设我们想要保留两个主成分进行可视化和训练
% coeff 是主成分系数矩阵,每列代表一个主成分
% score 是降维后的特征向量矩阵,每行代表一个样本在主成分空间中的坐标
% ~ 表示我们在这里不关注其他输出参数(例如latent, tsquared, mu)
% explained 是一个向量,包含了每个主成分的方差解释比例
num_components = 2;
[coeff, score, ~, ~, explained] = pca(all_feature_vectors);
% 注释解释:
% 1. 我们首先定义要保留的主成分数量 num_components 为 2。
% 2. 使用 MATLAB 的 pca 函数对特征向量矩阵 all_feature_vectors 进行主成分分析。
% 3. pca 函数的输出参数包括 coeff(主成分系数矩阵)、score(降维后的特征向量矩阵)、latent(每个主成分的方差)、tsquared(Hotelling's T-squared 统计量)和 mu(数据均值)。
% 4. 在这里,我们只关心 coeff 和 score,因此使用 ~ 来忽略 latent、tsquared 和 mu。
% 5. explained 向量包含了每个主成分的方差解释比例,它可以帮助我们了解每个主成分对数据方差的贡献程度。
2.4 构建随机森林模型
- 使用随机森林算法训练模型,将训练集的特征向量和相应的标签(NORMAL或PNEUMONIA)传入
TreeBagger函数中。
% 使用PCA降维后的特征向量训练随机森林模型
% num_trees 变量定义了随机森林中树的数量,这里假设使用100棵树
% rf_model 是训练得到的随机森林模型
% score(1:num_train_images, 1:num_components) 是经过PCA降维后的特征向量矩阵,
% 其中num_train_images是训练样本的总数,num_components是PCA降维后的特征数量
% [zeros(num_train_normal_images, 1); ones(num_train_pneumonia_images, 1)] 是目标标签向量,
% 其中NORMAL类别的标签为0,PNEUMONIA类别的标签为1
num_trees = 100;
rf_model = TreeBagger(num_trees, score(1:num_train_images, 1:num_components), ...
[zeros(num_train_normal_images, 1); ones(num_train_pneumonia_images, 1)], ...
'Method', 'classification'); % 明确指定分类任务
% 注释解释:
% 1. 我们首先定义随机森林中树的数量 num_trees 为 100。
% 2. 使用 MATLAB 的 TreeBagger 函数训练随机森林模型。
% 3. TreeBagger 的第一个输入参数是树的数量 num_trees。
% 4. 第二个输入参数是经过PCA降维后的特征向量矩阵,其中我们取前 num_train_images 个样本(假设这些是训练样本)和前 num_components 个特征。
% 5. 第三个输入参数是目标标签向量,其中NORMAL类别的标签为0,PNEUMONIA类别的标签为1。我们使用MATLAB的数组连接功能(分号;)将两个类别的标签向量合并成一个向量。
% 6. 最后,我们明确指定 'Method' 参数为 'classification',以确保我们训练的是一个分类模型。
2.5 十折交叉验证
- 将训练集分成十个子集,每次使用九个子集进行训练,一个子集进行验证,计算模型在所有验证集上的平均准确率。
% 设置交叉验证的折数
num_folds = 10;
% 使用 K 折交叉验证对训练集进行划分
cv = cvpartition(num_train_images, 'KFold', num_folds);
% 初始化一个向量用于存储每次验证的准确率
accuracies = zeros(num_folds, 1);
% 对每一折进行循环
for fold = 1:num_folds
% 获取当前折的训练集和验证集索引
train_idx = training(cv, fold);
val_idx = test(cv, fold);
% 从降维后的特征向量矩阵中提取当前折的训练集和验证集特征
train_features = reduced_train_features(train_idx, :);
val_features = reduced_train_features(val_idx, :);
% 从训练标签向量中提取当前折的训练集标签
train_labels = y_train(train_idx);
% 从训练标签向量中提取当前折的验证集标签
val_labels = y_train(val_idx);
% 使用随机森林在训练集上进行训练
rf_model = TreeBagger(num_trees, train_features, train_labels);
% 在验证集上进行预测
y_pred = predict(rf_model, val_features);
% 因为 TreeBagger 的 predict 方法对于分类任务返回的是类别标签字符串(例如 '0' 或 '1'),
% 所以我们需要将它们转换为数值型以便计算准确率
y_pred = str2double(y_pred);
% 计算并存储当前折的验证准确率
accuracy = sum(y_pred == val_labels) / numel(val_labels);
accuracies(fold) = accuracy;
end
% 计算所有折的平均准确率
mean_accuracy = mean(accuracies);
% 注释解释:
% 1. 使用 MATLAB 的 cvpartition 函数和 'KFold' 选项来创建交叉验证的索引。
% 2. 初始化一个列向量 accuracies 用于存储每次验证的准确率。
% 3. 对每一折进行循环,获取训练集和验证集的索引,并从降维后的特征向量矩阵和标签向量中提取对应的子集。
% 4. 使用 TreeBagger 函数在训练集上训练随机森林模型。
% 5. 使用 predict 函数在验证集上进行预测,并将预测结果从字符串转换为数值型。
% 6. 计算并存储当前折的验证准确率。
% 7. 计算所有折的平均准确率并存储在 mean_accuracy 变量中。
3. 结果展示
3.1 随机森林抉择图
ps:修改此行代码,可修改显示的抉择图数量。
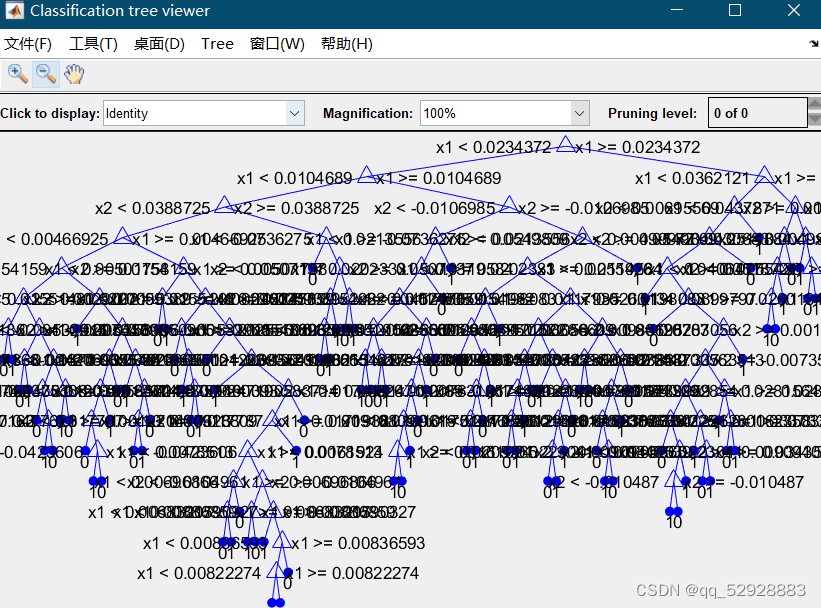
图3-1抉择图A
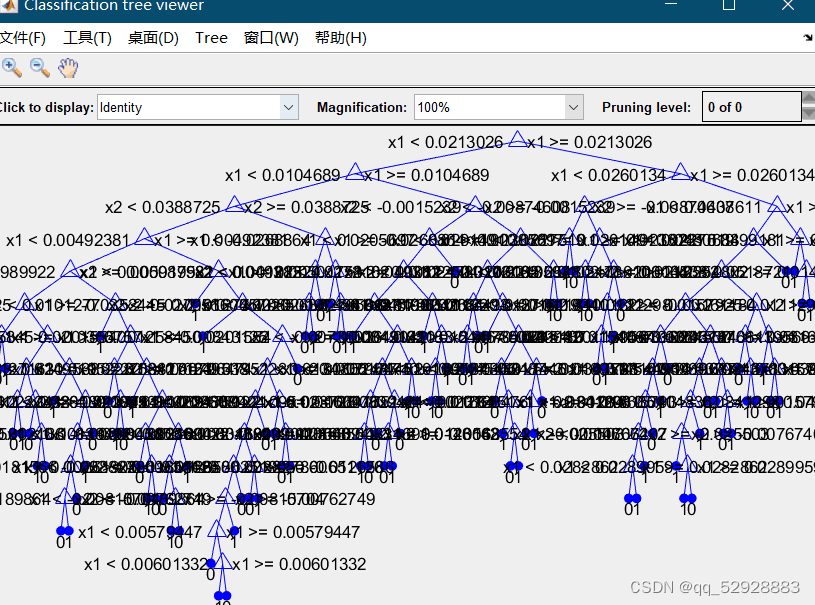
图3-2抉择图B
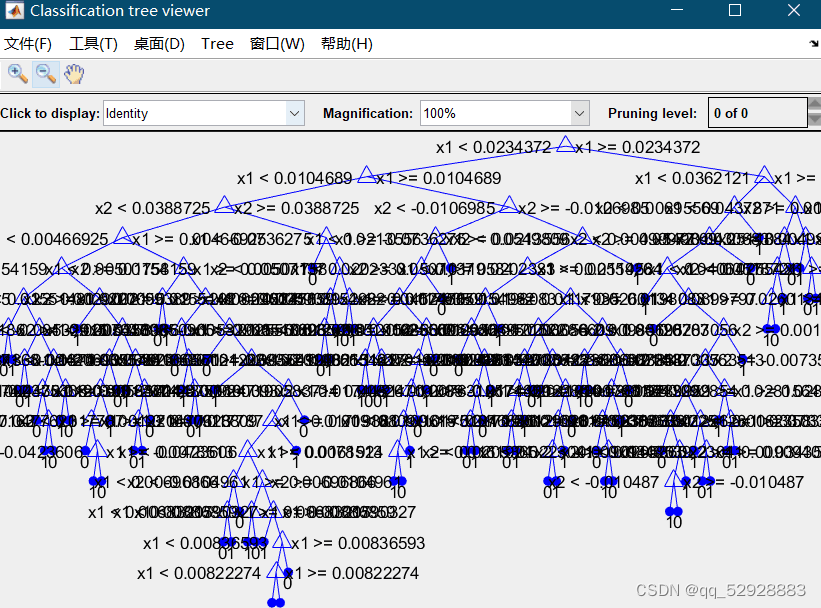
图3-3 抉择图C
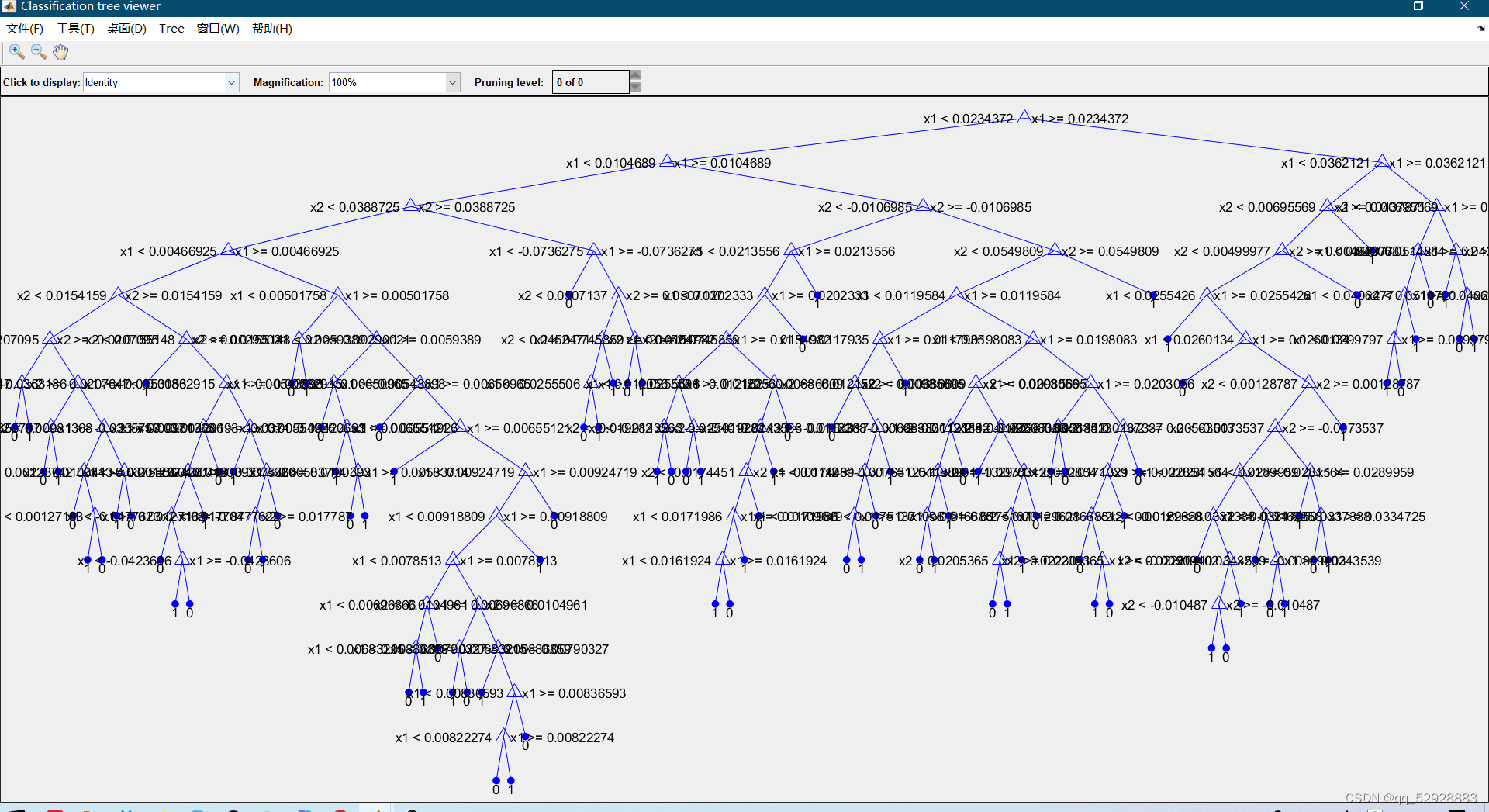
图3-4 抉择图细节
3.2 PCA
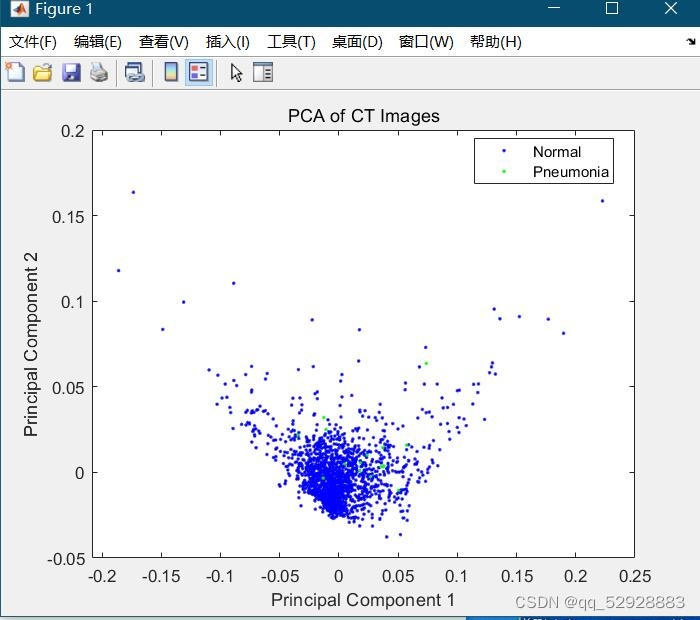
图3-5 PCA
3.3 十字交叉检测
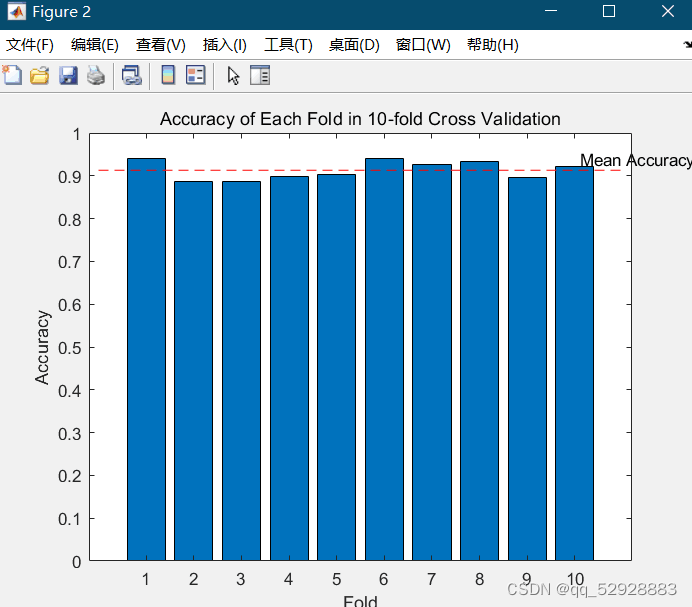
图3-6 十字交叉检测
3.4 全部图片
图3-7全部图片
3.5 控制台输出
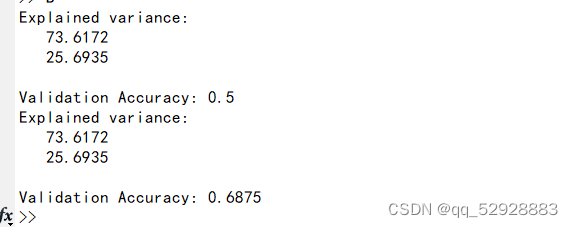
图3-8 控制台输出

















 2623
2623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









