







今天从第四节:结果开始介绍。
目录
四、结果
我们通过修改Faster R-CNN中公开可用的Python代码来实现StuffNet,该代码使用Caffe库[16]。我们所有的实验都使用70K训练迭代。学习率从1e-3开始,在50K次迭代后下降10倍。我们使用0.9的动量和0.0005的权重衰减,这是标准做法。我们从ImageNet上训练的公共VGG 16层模型初始化Faster R-CNN。DeepLab特定的卷积层使用其公共“init”模型进行初始化,该模型由VGG-16修改而来。RPN和最终的完全连接层使用Xavier[11]初始化随机初始化。在本节中,我们将评估各种StuffNet变体在各种数据集上的目标检测性能。对于我们所有的实验,我们使用更快的R-CNN作为共同基线。
4.1 多任务学习和多特征分类的影响
StuffNet依靠1)多任务学习和2)多特征分类来提高目标检测性能。为了分析多任务学习和多特征分类的影响,我们在Pascal VOC 2010训练分裂上训练了三个StuffNet变体,并给出了对val分裂的评估结果,见表1。多任务学习(StuffNet-multitask)将性能提高0.5% mAP,而它与多特征分类(StuffNet-10)的结合将性能提高1.5% mAP。添加目标分割功能(StuffNet-30)提供了额外的0.5% mAP。

4.2 不同尺寸目标的影响
认知心理学和计算机视觉的研究表明,识别周围环境对识别视觉不良(即模糊、部分遮挡或尺寸较小)的物体最有帮助。为了分析多任务学习和多特征分类对视觉贫困物体检测性能的影响,我们评估了Faster R-CNN、StuffNet-10和StuffNet-30,考虑了三种不同大小的物体。与MSCOCO[22]数据集一样,对象的大小被定义为小(面积< 32x32平方)。像素),中(32x32 <面积< 96x96平方;像素)和大(面积> 96x96平方。像素)。当对每种尺寸的对象进行基准测试时,其他尺寸的真实值标签被标记为“忽略”,同时使用[4]中给出的度量来评估每种尺寸。表2显示,相对于更快的R-CNN, StuffNet对小对象的mAP增幅最大(mAP增幅为5.1个百分点)。这表明多任务学习和多特征分类提高了目标检测性能,特别是对于通常视觉贫乏且需要额外上下文信息来识别的小尺寸目标。

4.3 不含stuff标签的数据集评估
StuffNet的一个吸引人的特点是,一旦分割分支被训练,它就可以用来在任何没有东西标签的数据集上训练StuffNet。这是使用3.3.2节中描述的特性约束机制完成的。在本节中,我们使用该方法在Pascal VOC 2007[5]和Pascal VOC 2012[7]训练分割上训练StuffNet-30,并在各自的测试分割上对它们进行测试。表3所示的结果显示,与Faster R-CNN相比,StuffNet-30提供了显著的改进。我们还将StuffNet-30的性能与最近使用上下文信息和不同特征进行目标检测的两个基线进行了比较:来自[9]和segDeepM[41]的多区域和分割感知CNN (MR-CNN和S-CNN)。MR-CNN & SCNN结合了来自不同上下文区域的特征,以及来自单独训练的网络的特征,以分割正在检测的相同对象。[9]还开发了一种迭代目标重新定位策略,作为后处理步骤应用。由于目标重新定位超出了本文的范围,我们将StuffNet与[9]的结果进行比较,而[9]没有进行目标重新定位。segDeepM使用从区域提议周围的扩展区域中汇集的特征来多样化输入到区域分类器的特征,并从为ImageNet图像识别挑战训练的AlexNet [20] CNN中提取。
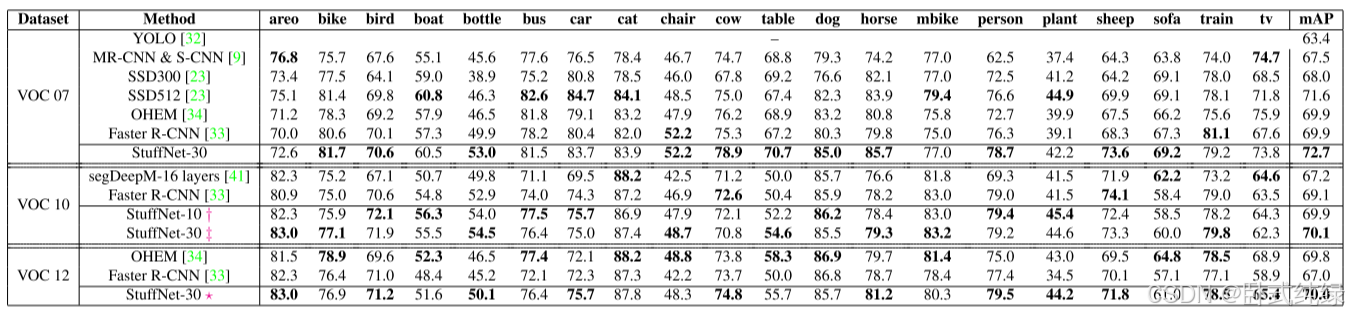
如表3所示,与Faster R-CNN相比,StuffNet-30的VOC 2007和VOC 2012的性能分别提高了2.8个百分点和3.0个百分点,两者都没有材料标签。相比之下,[9]和[41]的可比模型比Faster R-CNN的性能差约2% mAP。这表明,多任务学习和从VOC 2010中学习到的输出分割的约束特征作为目标检测任务的有效正则化器。图4显示了一些来自Pascal VOC 2010测试的StuffNet-30检测图像的例子,并与Faster R-CNN进行了比较。图5显示了使用Pascal VOC 2010训练训练的模型对MS COCO数据集的图像进行检测(Faster R-CNN和StuffNet-30)和分割(StuffNet-30)的结果。请注意,在检测小物体方面,StuffNet-30比Faster R-CNN更好。


4.4 语义分割评估
表4显示了StuffNet-10和单独训练的DeepLab网络在分割10个素材类的任务上的性能。StuffNet的性能比单独训练的DeepLab低0.2个百分点。我们假设,在训练StuffNet时,对Faster R-CNN和DeepLab成本函数进行适当的加权和将提高语义分割性能。这是因为这两种损失都是通过对总和做出贡献的数据点数量(用于Faster R-CNN的mini-batch中的区域建议数量和用于DeepLab的图像中的像素数量)进行归一化的。这种归一化以非常低的因子衡量单个像素错误语义分割输出的损失。可以使用交叉验证来仔细搜索Faster R-CNN和DeepLab损失函数的相对权重。
表4的最后一行显示了在Pascal VOC 2012(一个没有材料标签的数据集)上使用特征约束方法训练的StuffNet-30的性能。此评估的真实值标签是使用经过Pascal VOC 2010训练的StuffNet-30生成的。高性能证明了特征约束方法的有效性。图4显示了使用正常训练和使用特征约束的StuffNet模型进行目标和材料语义分割的一些示例。

五、结论
我们提出了StuffNet算法,它使用多任务学习和多特征分类来改进目标检测,特别是对小目标。StuffNet允许材料和目标语义分割密切影响目标检测过程。通过使用简单的特征约束过程,可以将StuffNet的适用性扩展到缺乏材料或目标分割标签的数据集。
本文为未来的研究开辟了一些途径:1)在目前的体系结构中,RPN不能从多特征输入中获益。我们推测,允许这样做将提高定位性能,特别是对于小对象。2)使用更深层次的表示(例如ResNet[13])也应该进一步提高性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









