







之前已经试过在yolov3和faster-rcnn上训练SeaShips数据集,本次在yolov8上进行训练。
yolov8的训练有两种方式,一种是在mmdetection框架下下载mmyolo运行,另一种是直接采用ultralytics。本文两种方法都会介绍。
目录
一、mmyolo
mmyolo支持yolo许多系列的算法:

1.1 创建环境
conda create -n mmyolo python=3.8 pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c pytorch -y
conda activate mmyolo
pip install openmim
mim install "mmengine>=0.6.0"
mim install "mmcv>=2.0.0rc4,<2.1.0"
mim install "mmdet>=3.0.0,<4.0.0"
git clone https://github.com/open-mmlab/mmyolo.git
cd mmyolo
# Install albumentations
pip install -r requirements/albu.txt
# Install MMYOLO
mim install -v -e .按照上述步骤安装好mmyolo并创建属于自己的虚拟环境。
创建环境出错的可以看看我的这篇文章:基于kitti数据集的3D目标检测算法的训练流程_kitti 3d目标检测-优快云博客
里面详细的讲解了环境的配置等操作。
mmyolo装好之后应该会有这样的文件夹:
1.2 数据集准备
我们的SeaShips数据集格式是这样的:
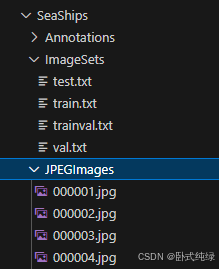
Annotations里面是所有图像的标注文件(.xml),ImageSets是测试、训练和验证数据集划分文件(txt),JPEGImages里是所有的图像文件。
我们需要将数据集转换成yolov8允许的格式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









