







很早之前就开始学习卷积的相关知识,但一直忘记整理成笔记的形式了。最近正好也一直在学习深度学习的相关内容,一边整理一遍回顾学习的内容。
我参考的书籍是这本,对于想要学习深度学习相关内容的朋友可以从这本书开始,内容比较基础且通俗易懂,很好理解。

目录
一、 神经网络
神经网络即深度学习,因其结构类似于人体大脑中神经元的结构而得名。
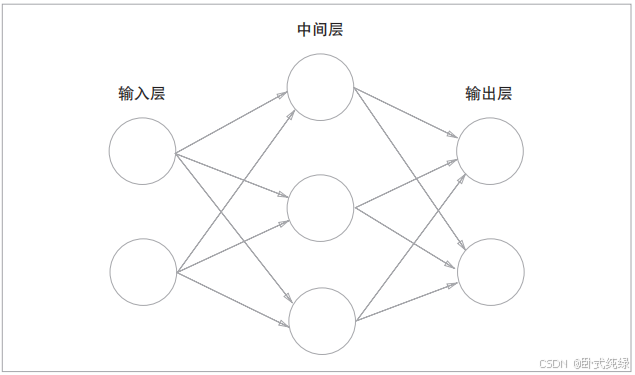
图2中的神经网络一共有三层神经元,输入层、中间层和输出层。中间层也被成为“隐藏层”,因为中间层的神经元一般是肉眼看不见的。其中只有输入层和中间层两层具有计算时所需的权重,故该网络可以称为2层网络(有时也会因为该网络有三层而称其为3层网络)。实质上具有计算权重的层数等于所有层数-1计算而来。
(一)感知机
在学习神经网络之前,我们可以先来了解一下感知机,感知机是作为神经网络的起源的算法,感知机的构造也是学习通向神经网络和深度学习的重要思想。
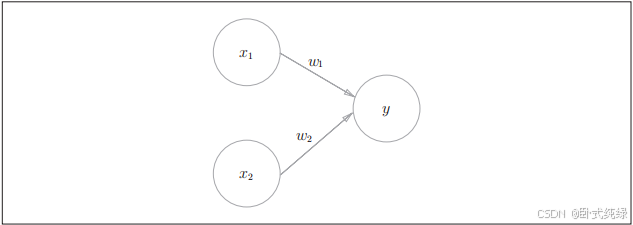
如图3,感知机也如同神经元一般,输入的神经元有两个,分别是x1和x2,其权重分别为w1,w2,输出神经元仅有一个,是y。感知机的输出只有1和0两种信号,在输入的值达到一定之后才会输出1,否则输出0.我们将这个值成为“阈值”(用符号表示)。用公式表示输出为:
(1)
权重类似于电流中的电阻,电阻越低,电流就越大。在感知机中权重越大,通过的信号就越大。
(二)感知机与神经网络
神经网络类似于感知机的构造,也是具有输入层、中间层和输出层。这里我们引入一个新的函数(激活函数)来简化公式(1):
(2)
这里b代表的是偏置,用于控制神经元被激活的容易程度,w1和w2表示各个输入信号的权重的参数,用于控制各个信号的重要性。
而此时的h(x)函数可以表示为如下形式:
(3)
此时,输入的信号总和就会被函数h(x)转换,转换后的值就是输出层y的值。显然,(1)式和(2)(3)实现的效果功能相同。
(三)激活函数
1、阶跃函数
(2)中出现的h(x)函数的功能是转换输入信号的总和,这样的函数就被称为激活函数(activation function)。激活函数的作用就是决定如何来激活输入信号的总和。
(3)中的激活函数以一定的阈值为界限(该式以0为边界),一旦输入超过阈值,就会切换输出。这样的函数称为“阶跃函数”。也就是说在感知机中使用的激活函数是阶跃函数,下面我们来认识一些其他的激活函数。
阶跃函数的代码实现也比较简单:
def step_function(x):
if x>0:
return 1
else:
return 0这样的实现简单也易于理解,但参数x只允许接受实数(浮点数),不能接受Numpy数组类型的数据,例如np。array[1.0,2.0],为了便于操作,我们修改函数实现为支持Numpy数组的形式:
def step_function(x):
y = x>0
return y.astype(np.int)
由于使用了Numpy的技巧,有点难于理解,下面对每一行进行解释:
y = x > 0 x是一个数组,例如输入x为[1.0,-1.0,0],x > 0会将数组x中的每一个数值与0进行比较,若大于则返回True,否则返回False,故x > 0返回一个布尔(boolean)类型的数组[True,False,False]并赋值给y
return y.astype(np.int) 我们不希望输出是布尔类型的值而是一个数字,则使用astype(np.int)对y数组进行转换,该表达式将y数组中的值转换为int(整型)类型,其中True转换为1,False转换为0.故最终输出的y是[1,0,0]。
下面我们使用以下代码绘制阶跃函数的图像:
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
y = x > 0
return y.astype(np.int)
x = np.arange(-5.0,5.0,0.1)
y = step_function(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1) #指定y轴的范围从-0.1到1.1
plt.show() 生成的图像如下所示:
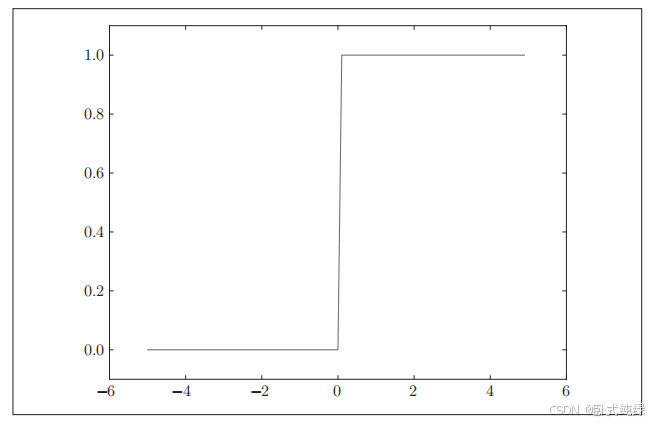
如图所示,阶跃函数以0为界限,输出从0切换到1,值呈阶梯式变化,所以称为阶跃函数。
2、sigmoid函数
神经网络中最常用的激活函数就是sigmoid函数(sigmoid function),其表达式如下:
(4)
其中表示
,e为纳皮尔常数:2.7182……。虽然函数形式看着比较复杂但其实也就是一个转换器,将输入数值转换为输出。比如输入1.0,2.0就可以得到这样的结果:h(1.0)=0.731……,h(2.0)=0.880……神经网络采用sigmoid函数作为激活函数进行信号转换,这也是神经网络和感知机的主要区别。其他方面如神经元多层连接构造、信号传递方法基本上一致。
sigmoid函数的代码实现也比较简单:
def sigmoid(x):
return 1/(1+np.exp(-x))实现并不困难,但需要注意的是这里参数x为Numpy数组时,结果也能被正确计算。这是因为Numpy的广播功能(这里不作详细解释)。
同样我们使用以下代码绘制sigmoid函数的图像:
x = np.arange(-5.0,5.0,0.1)
y = sigmoid(x) #这里直接调用就不重复定义函数
plt.plot(x,y)
plt.ylim(-0.1,1.1)
plt.show()绘制的结果如下:
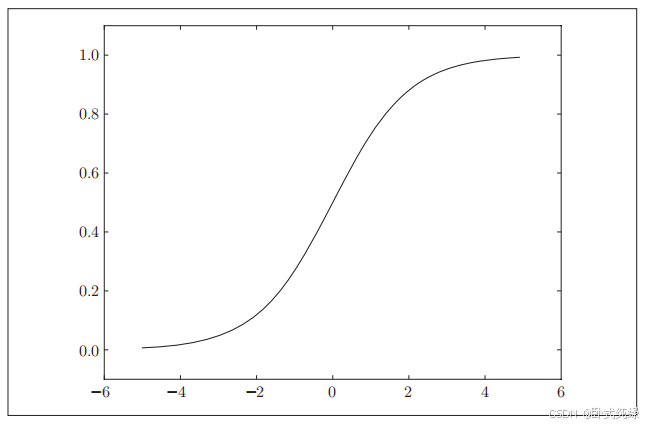
阶跃函数和sigmoid函数的比较:
一、相同点:
1、图像形状相似,输入小,输出接近0(为0),输入大,输出接近1(为1);
2、不管输入信号大或小,输出信号的值都介于0-1之间;
3、都是非线性的函数,即都不是一条直线。阶跃函数是折线,sigmoid函数是一条光滑的曲线。
二、不同点:
1、平滑性不同。sigmoid是平滑的,输出随输入发生持续性变化,而阶跃函数则在0出发生急剧性变化;
2、输出值不同,阶跃函只能输出0和1两种信号,而sigmoid函数可以输出0.731、0.880……等实数值(与平滑性相关)。
3、ReLU函数
接下来我们来学习一个新的激活函数RuLU函数(RectifIed Linear Unit),其表达式如下:
(5)
ReLU函数的实现也比较简单:
def RuLU(x):
return np.maximum(0,x)maxmum函数将会比较0和输入的x值的大小,然后输出较大的那个。接着我们也可以使用与上面类似的代码实现图像可视化(这里不给出代码,大家可以自己试着写出)。RuLU函数的图像如下所示:
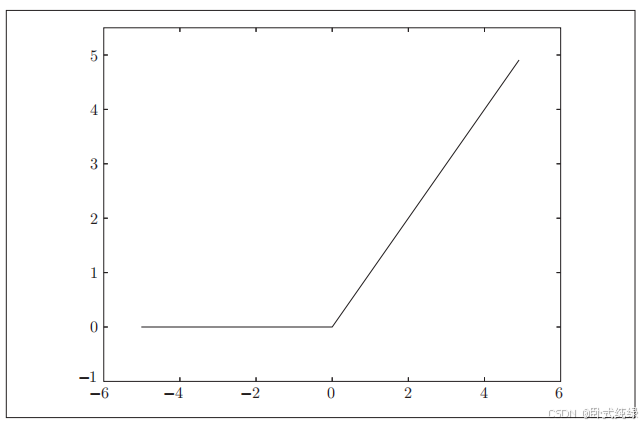
可以看到ReLU函数的图像也符合阶跃函数和sigmoid函数的共同点。
4、恒等函数
恒等函数顾名思义就是与输入相等,其表达式和代码实现如下:
(6)
def identity_function(x):
return x其图像为一条直线,与数学中学到的一次函数y=x的图像一致。
5、softmax函数
机器学习的问题可以分为分类问题和回归问题。分类问题考虑的是数据属于哪一个类别,比如图像中的水果属于苹果还是香蕉。回归问题考虑的是根据某个输入预测一个(连续的)数值,比如根据房子的占地面积和使用年限等预测房子的价格。
神经网络在分类问题和回归问题中要根据情况改变输出层的激活函数,一般情况下回归问题使用恒等函数,二元分类(即物体类别只有两项时)使用sigmoid函数,而在多元分类时(即物体类别大于2时)使用softmax函数。
softmax函数的表达式如下:
(7)
因为softmax函数适用于多元分类问题,故该输出层共有n个输出……
,每一个y代表的是该类别的可能性,例如判断一张水果图像的类别时,输出有三项,y1=0、y2=0和y3=1,分别代表苹果、梨子和香蕉,因为y3=1,故最终输出的类别为香蕉。式(7)中exp(x)代表
的指数函数(e是纳皮尔常数2.7182……)。分子是输入信号ak的指数函数,分母是所有输入信号的指数函数的和。显然,输出层的各个神经元都受到所有输入信号的影响。
其代码实现也不算难:
def softmax(a):
exp_a = np.exp(a) #此处a是一个数组,代表a1……ak个数据
sum_exp_a = np.sum(exp_a0)
y = exp_a / sum_exp_a
return y上述代码虽然正确的描述了式(7),却仍存在一定小问题,那就是计算机存储的溢出问题。softmax函数要进行指数的计算,而指数函数值增长非常迅速,比如就超过了20000,而
是一个有四十多个0的大数,
的结果则是一个表示无穷大的inf,这些值进行除法运算则结果会出现“不确定”的情况。计算机在处理数时,数值必须在4字节或8字节的有限数据宽度内,这也就意味着计算机内可表示的数值范围是有限的。
接下来我们将softmax函数的实现进行以下改进:
(8)
我们通过在分子分母上都乘以C这个任意常数,再将常数移动到指数函数中,最后用C’代替logC,我们发现在进行指数函数运算时,加上(或减去)某个常数并不改变运算的结果。这里的C’可以使用任何值,为了防止溢出,我们一般会使用输入信号中的最大值。于是修改后的代码实现:
def softmax(x):
C = np.max(a)
exp_a = np.exp(a-C) #溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y通过式(7)我们得知softmax函数的输出是0.0到1.0之间的实数,并且输出值的总和一定是1。这是一个非常重要的性质,有了这个性质我们也可以将softmax函数的输出解释为“概率”。
需要注意的是,即使使用了softmax函数,各个元素之间的大小关系并没有改变,因为指数函数是单调递增的函数。
softmax函数的图像大家也可以自己尝试绘制。
(四)损失函数
损失函数是用来表示神经网络性能的“恶劣程度”的指标,即当前神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
1、均方误差
可以作为损失函数的函数有很多,最有名的就是均方误差(mean squared error)。表达式如下:
(9)
这里yk是神经网络的输出,tk是监督数据,k表示数据的维度。代码实现如下:
def mean_squared_error(y,t):
return 0.5 * np.sum(y - t)**22、交叉熵误差
交叉熵误差(cross entropy error)也经常被用作损失函数,表达式如下:
(10)
这里log表示以e为底数的自然对数(),yk是神经网络的输出,tk是正确解标签且只有正确标签的索引为1,其他均为0(这被称为one-hot表示)。因此式(10)实际上只计算正确标签的输出的自然对数。自然对数的图像如下所示:
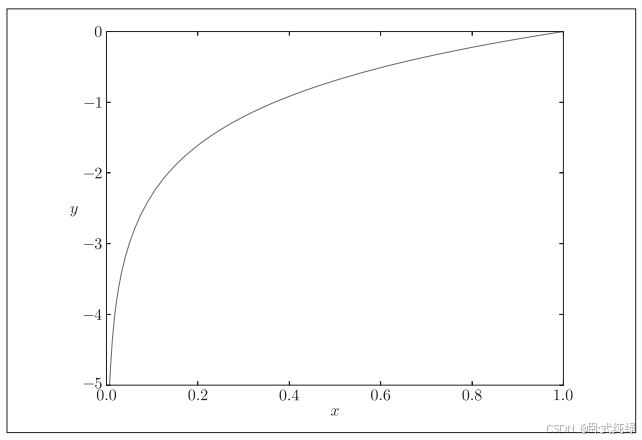
代码实现如下:
def cross_entropy_error(y,t):
delta = 1e - 7
return -np.sum(t * np.log(y + delta))这里参数y和t是Numpy数组,函数内部在计算np.log时,加上了一个微小值delta是因为在出现np.log(0)时,结果就会变成负无限大的-inf,这样就会导致计算出错。添加delta可以防止这种情况发生从而形成一个保护性对策。
二、卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)常被用于图像识别、语音识别等场合。基于深度学习的图像识别方法几乎都以CNN为基础。
卷积神经网络和神经网络的结构类似,都是通过乐高积木一样通过组装层来构建。只不过CNN中出现了新的层:卷积层(Convolution层)和池化层(Pooling层)。神经网络中相邻层之间的所有神经元都有连接成为全连接(fully-connected)。
(一)网络结构
我们可以看到一个使用Affine层的5层全连接神经网络如图所示:
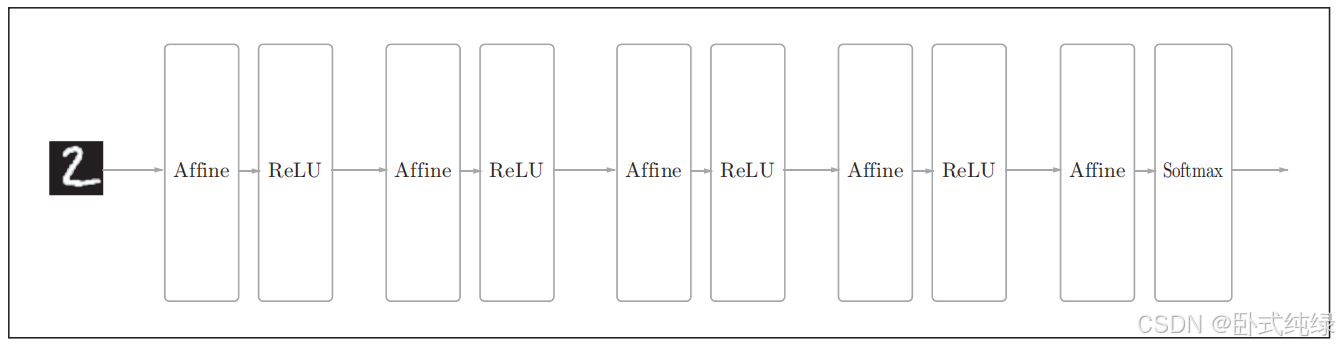
那么接下来再看一个CNN的网络结构:
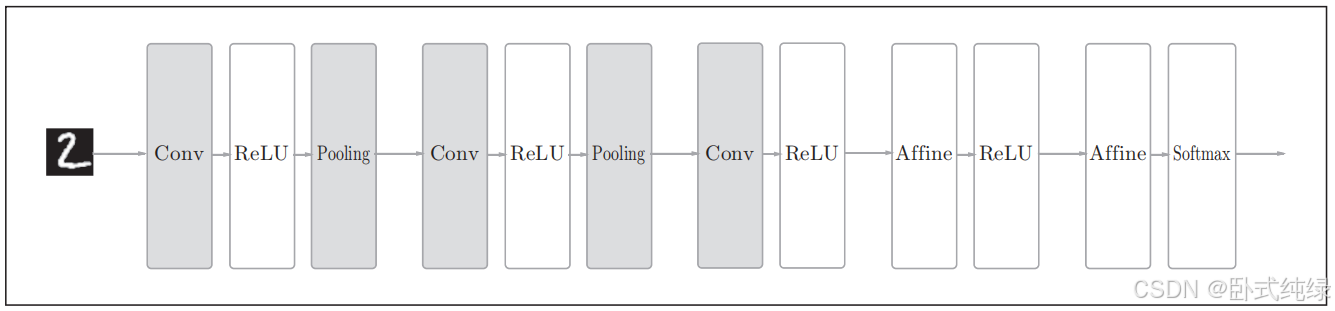
如图所示,CNN中新增了Convolution层和Pooling层(图中灰色的方块),CNN层的连接顺序是“Convolution - ReLU - (Pooling)”,Pooling层有时会被省略。靠近输出层的层中使用了Affine-ReLU组合,输出层使用了Affine-Softmax组合,这都是CNN中比较常见的结构。
(二)卷积层
1、全连接层的问题
全连接的神经网络采用了全连接层(Affine层),而这种层会“忽视”数据的形状。输入数据为图像时,图像通常是高、长、通道方向3维的形状。但是在全连接层输入时,需要将3维的数据拉平成为1维的数据(类似于多维数组变为一维数组) 。三维的图像信息包含重要的空间信息,如空间上邻近的像素为相似的值、RBG的各个通道之间分别有密切的关联性、相距较远的像素之间没有什么关联等。这些都是全连接层得不到的信息,而卷积层很好的保留了这些信息,保持原始输入数据形状不变并以同样的形式输出至下一层。CNN中有时将卷积层的输入输出数据成为特征图(feature map)。其中输入数据成为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。
2、卷积运算
卷积层进行的运算处理就是卷积运算,卷积运算相当于图像处理中的“滤波器运算”。
首先我们来看一个卷积运算的例子:
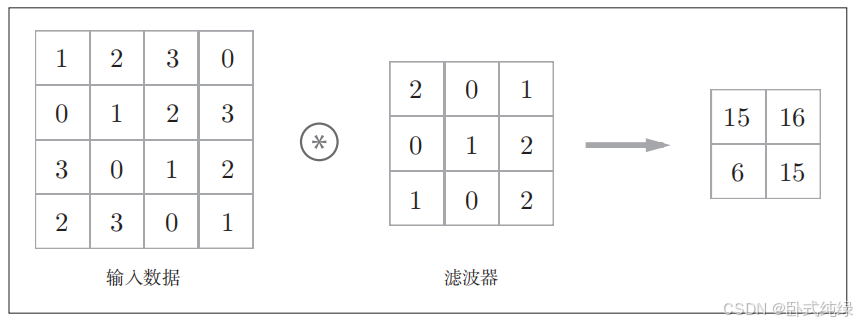
如图输入数据是(4,4)大小的,滤波器是(3,3)大小,“*”符号表示卷积运算。有的文献中也会用“卷积核/核”表示“滤波器”。下面来解释一下这个例子中都进行了怎样的运算。
对于输入数据,卷积运算以一定的间隔滑动滤波器的窗口并应用,这里的窗口指下图中灰色的3×3部分。将各个位置上滤波器的元素和输入的对应元素相乘在进行求和得到输出的对应位置(这个运算有时也被称为乘积累加运算),将这个过程在所有位置进行一遍,就可以得到卷积运算的输出。
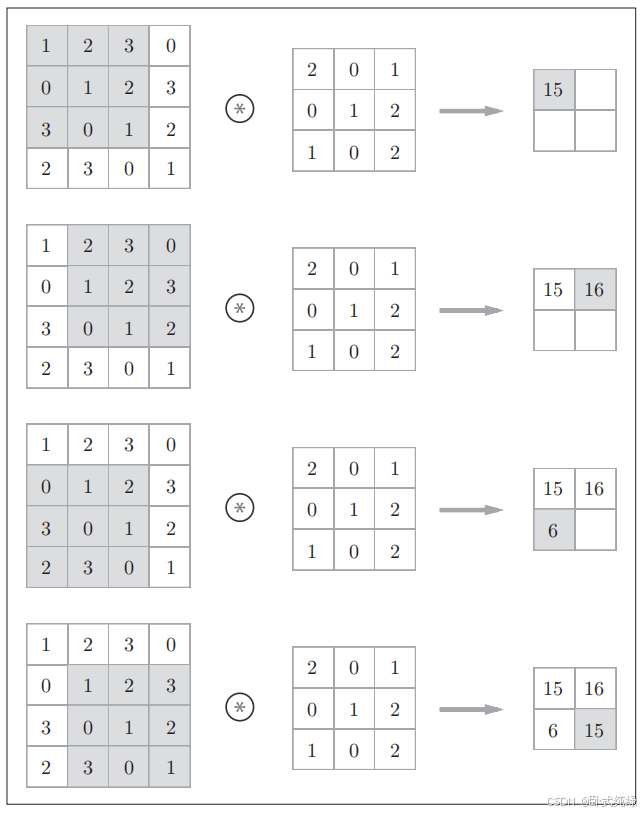
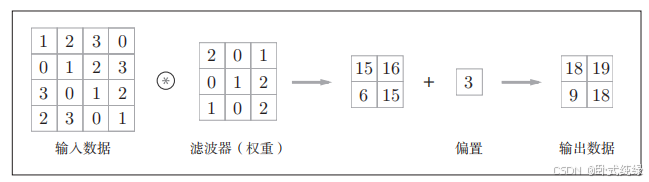
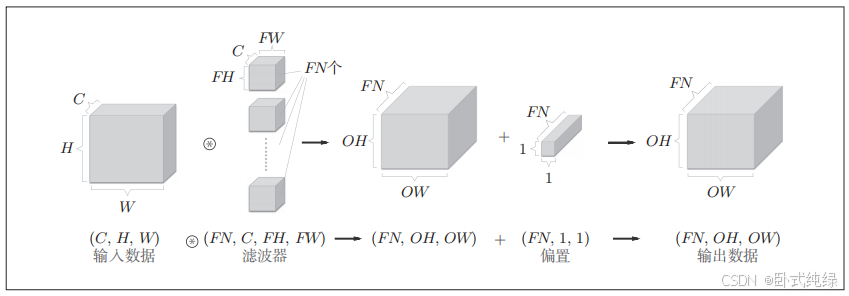
下图展示了偏置的作用,偏置通常只有1个(1×1),相对于应用了滤波器的4个数据,这个值会被加到应用了滤波器的所有元素上(滤波器类似于神经网络中的权重w,偏置类似于神经网络中的偏置b)。
3、填充
我们可以看到输入数据在经过卷积运算后形状会缩小(如图2.4中,3x3的输入特征图经过一次卷积运算之后变成了2x2的输出特征图),为了保证输出特征图的形状大小不发生改变,有时会在进行卷积层处理之前,向输入数据的周围填入固定的数据(比如0),这就叫做填充,下图展示了填充的例子:
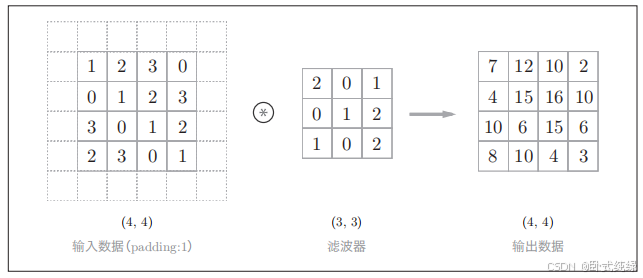
我们像原始数据周围填充了一圈0(图中用虚线表示填充,且省略了填充的内容“0”)。通过填充,使大小为(4,4)的输入数据变成了(6,6)的形状,这样再应用(3,3)的滤波器后生成的输出数据还是(4,4)的大小,这样就实现了形状不变的功能。填充的值可以更改为任意值,之后我们会学习输出特征图大小计算公式,各位可以根据自己的需要的输出大小来更改填充值。
4、步幅
应用滤波器的位置间隔成为步幅(stride)。之前我们看到的例子步幅都是1,如果将步幅更改为2,则应用滤波器的窗口间隔变为两个元素,如图所示:
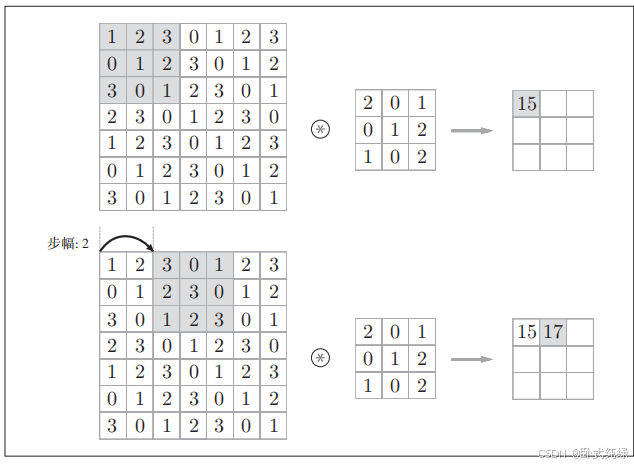
如图所示,每进行一次乘积累加运算之后滑动窗口向右滑动两格,输入大小为(7,7)的数据以步幅2应用滤波器之后输出大小变为(3,3)。故而我们得知,增大步幅,输出大小会变小,增大填充后,输出大小会变大。下面我们来看输出特征图的大小形状该如何计算:
假设输入大小为(H,W),滤波器大小为(FH,FW),输出大小为(OH,OW),填充为P,步幅为S。则输出大小的计算公式为:
(10)
(11)
5、3维数据的卷积运算
之前卷积运算的例子都是以长、高方向的2维数据,但是实际的图像是除了长、高方向还有通道方向的3维数据。接下来我们看看加上通道方向的3维数据进行卷积运算的例子。
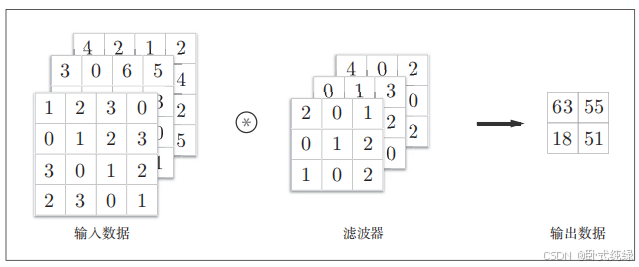
其计算过程如图2.9所示:
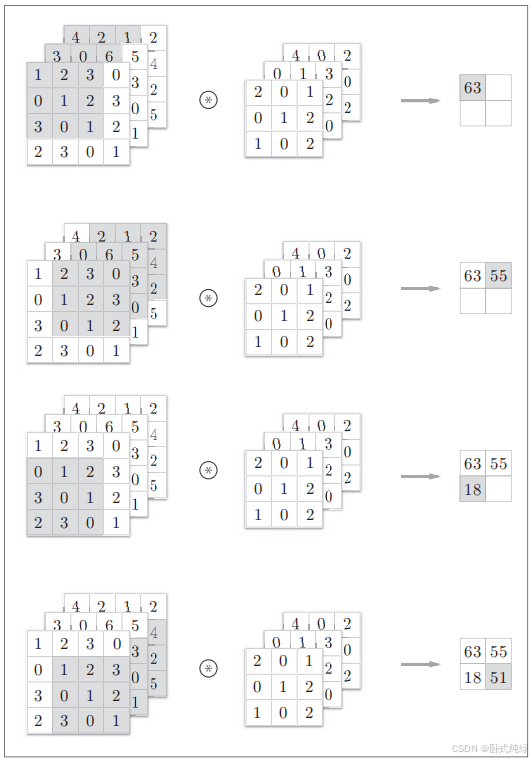
其实3维卷积运算与2维卷积运算过程类似,只是在纵深方向(通道方向)上特征图增加,按照通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。
在3维数据的卷积运算中,输入数据和滤波器的通道数要设置为相同的值,滤波器的大小可以设定为任意值,但每个通道的滤波器大小要完全相同。
6、结合方块思考
现在将数据和滤波器结合长方体的方块进行考虑,3维数据的卷积运算就很容易理解了。如图2.10所示,将3维数据表示为多维数组时,书写顺序为(channel,height,width)。比如通道数为C,高度为H,长度为W的数据形状可以写成(C,H,W),滤波器也要按照同样的顺序书写,比如通道数为C,滤波器高度为FH(Filter Height)、长度为FW(Filter Width)时,可以写成(C,FH,FW)。
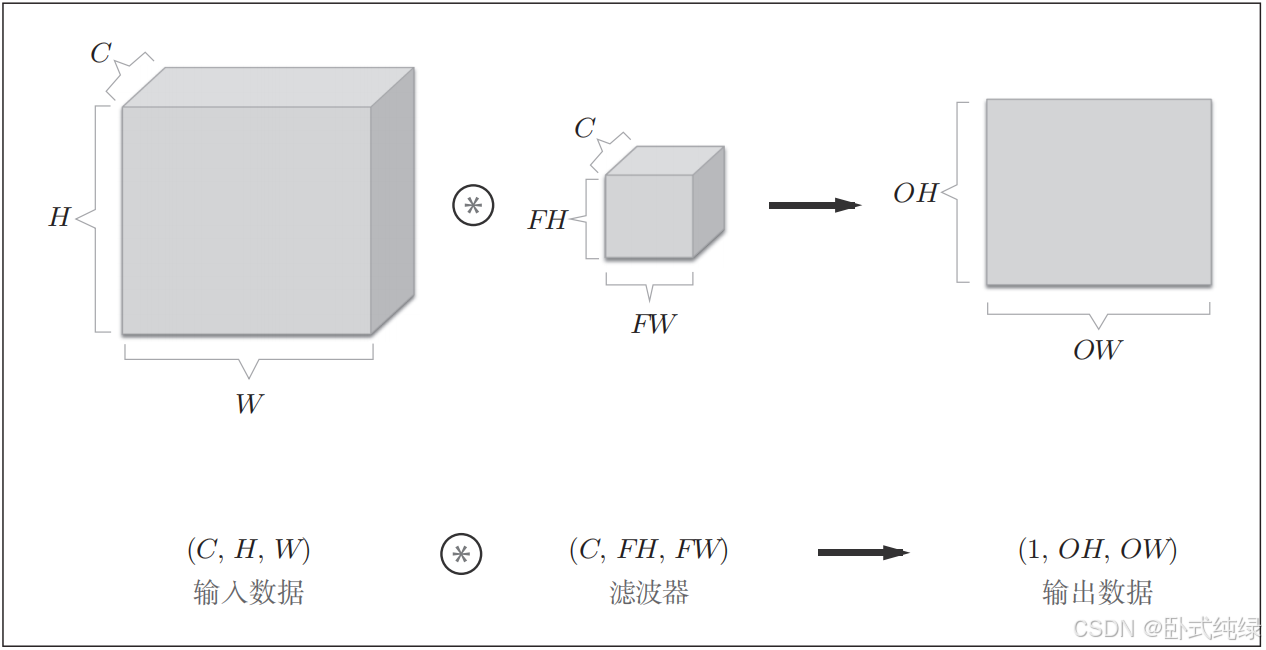
如图2.10所示,数据输出是1张特征图,也就是通道数为1的特征图。如果想要多张特征图即多个通道方向上也拥有卷积运算该如何操作呢?答案是使用多个滤波器(权重)。
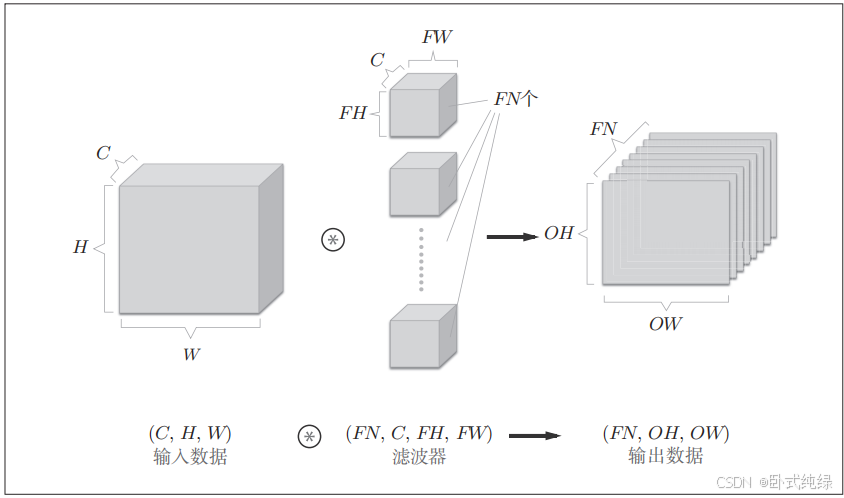
通过应用FN个滤波器,输出特征图也生成了FN个,如果将FN个特征图汇集在一起,就得到了形状为(FN ,OH,OW)的方块。将这个方块传输给下一层,这就是CNN的处理流。关于卷积运算的滤波器必须考虑滤波器的数量,作为4维数据,滤波器的权重数据要按照(output_chanel,inpiut_channel,height,width)的顺序书写。如图2.5所示,卷积运算中也存在偏置,如果对图2.11的例子追加偏置的加法运算处理,则结果如下图所示:
(三)池化层
1、池化
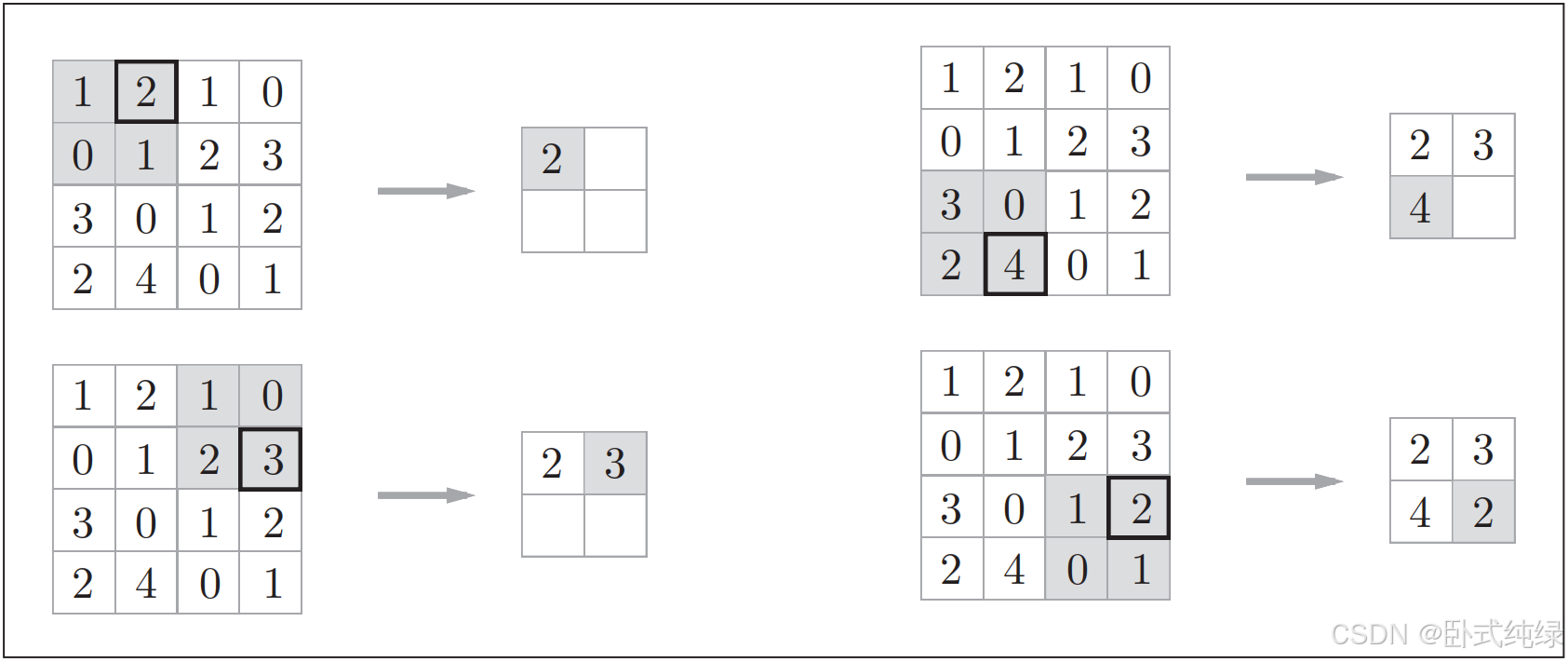
池化是缩小高、长方向上的空间运算,如图所示:
我文章中讲VoxelNet的部分有用到最大池化的部分,可以去看看:VoxelNet文献理解-优快云博客
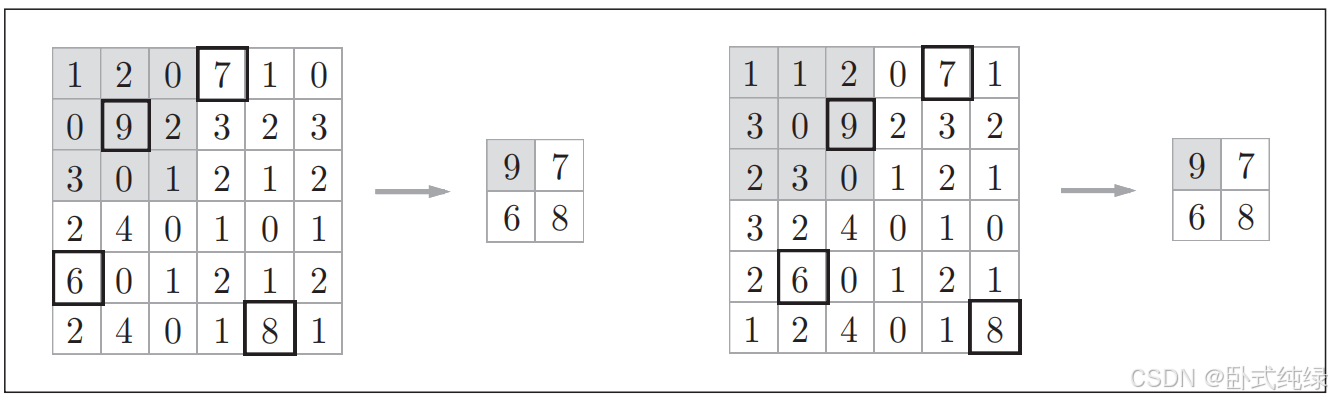
通过Max池化讲(4,4)大小的输入数据缩小成(2,2)的区域,步幅是2.“Max池化”是获取最大值的运算,“2×2”表示目标区域的大小。一般来说,池化的窗口大小会和步幅设置成相同的值。例如2×2的窗口步幅设置成2,3×3的窗口步幅设置成3……
除了MAx池化之外,还有Average池化等。Average池化是计算目标区域的平均值。图像识别领域中主要使用MAx池化。
2、池化层的特征
池化层有以下特征:
(1)没有要学习的参数:池化层和卷积层不一样,没有要学习的参数。池化只是从目标区域取得最大(或平均值),所以不存在要学习的参数。
(2)通道数不发生变化:经过池化运算,输入数据和输出数据的通道数不会发生变化。如下所示。池化是按照通道独立进行的。
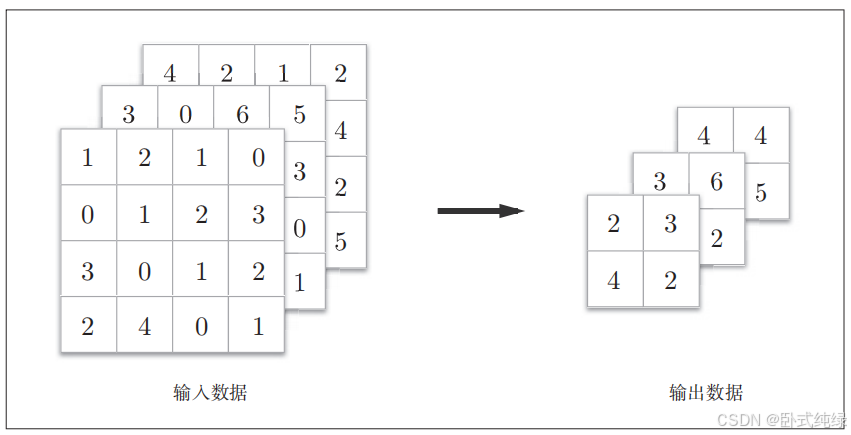
(3)对微小位置变化具有鲁棒性(健壮):输入数据发生微小偏差时,池化仍会返回相同的结果。如下图所示,池化会吸收输入数据的偏差(根据数据的不同,可能会返回不同的结果)。
基础知识内容就先介绍到,后面的代码实现部分之后再进行详解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









