







 文章介绍了多种解决LeetCode中寻找两个链表第一个公共节点问题的算法,包括暴力法、调整链表长度、使用哈希、栈以及双指针等方法,分析了它们的时间复杂度和空间复杂度,强调了优化思路和链表长度在解题中的关键作用。
文章介绍了多种解决LeetCode中寻找两个链表第一个公共节点问题的算法,包括暴力法、调整链表长度、使用哈希、栈以及双指针等方法,分析了它们的时间复杂度和空间复杂度,强调了优化思路和链表长度在解题中的关键作用。
题目 输入两个链表,找出它们的第一个公共节点。
地址https://leetcode.cn/problems/liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof/
分析
1. 使用暴力法,将每一个链表节点和另一个链表比较,找到相同的节点位置,返回,但是很显然,时间复杂度比较高。
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode currA = headA;
while (currA != null) {
ListNode currB = headB;
while (currB != null) {
if (currA == currB) {
return currA;
}
currB = currB.next;
}
currA = currA.next;
}
return null;
}
运行截图

时间复杂度:O(mn),两个链表遍历的长度相乘
空间复杂度:O(1),使用了两个节点
可以看出时间复杂度还是很高的
2. 又想到了考虑的是既然要找到公共节点,两个链表是有长短的,只要找出短的链表,计算长度,然后再遍历长的链表,当两个链表一样长的时候,比较值就可以了,但是可想而知,会使用一堆while循环。
public static ListNode getIntersectionNode2(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
// 先获取相应链表的长度
ListNode currentA = headA;
ListNode currentB = headB;
int lengthA = 0;
int lengthB = 0;
while (currentA != null) {
currentA = currentA.next;
lengthA++;
}
while (currentB != null) {
currentB = currentB.next;
lengthB++;
}
int minLength = lengthA > lengthB ? lengthB : lengthA;
int count = 0;
// 链表A比较短
if (minLength == lengthA) {
while (lengthB - count > lengthA) {
headB = headB.next;
count++;
}
while (headA != headB) {
headB = headB.next;
headA = headA.next;
}
return headA;
}
if (minLength == lengthB) {
while (lengthA - count > lengthB) {
headA = headA.next;
count++;
}
while (headA != headB) {
headB = headB.next;
headA = headA.next;
}
return headB;
}
return null;
}
运行截图

时间复杂度:首先各自遍历链表长度,为O(m+n), 然后调整长链表的长度和短链表一致,时间复杂度是O(max(m,n)),最后再执行遍历找到公共节点,O(min(m,n)),总的来说O(m+n+max(m,n)+min(m,n)),也不知道算的对不对,但是就是很复杂。
空间复杂度:O(1)两个节点;
总结:虽然一开始感觉时间耗费高,但是测试下来,发现时间耗费这么低。
3. 既然考虑公共节点,那么也就是说可以看作是在集合或者数据里面判断是否两个相同的数,最直接的是考虑hash,只需要将一个链表的节点放入map,然后依次和另一个链表的节点比较就行
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Set<ListNode> set = new HashSet<>();
while (headA != null) {
set.add(headA);
headA = headA.next;
}
while (headB != null) {
if (set.contains(headB)) {
return headB;
} else {
headB = headB.next;
}
}
return null;
}
运行截图

时间复杂度:第一次循环添加headA节点,O(m),第二次遍历headB,O(n),总体O(m+n)
空间复杂度: 使用set来存储节点,O(m)
总结:需要多加注意下尤其是涉及到是否包含相同的节点,数的时候就考虑使用哈希
4. 使用栈,特点是先进后出,本质上还是将两个链表节点比较,只是由于是逆序,所以,如果有共同节点,最后一个相同的节点之后的其他节点就不相同了,不需要像之前从头开始循环遍历比较。
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Stack<ListNode> stackA = new Stack<ListNode>();
Stack<ListNode> stackB = new Stack<ListNode>();
while (headA != null) {
stackA.add(headA);
headA = headA.next;
}
while (headB != null) {
stackB.add(headB);
headB = headB.next;
}
ListNode preNode = null;
while (stackA.size() > 0 && stackB.size() >0) {
if (stackA.peek() == stackB.peek()) {
preNode = stackA.pop();
stackB.pop();
} else {
break;
}
}
return preNode;
}
运行截图
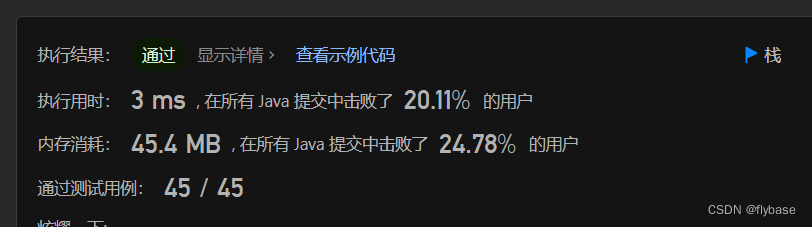
时间复杂度:第一个链表添加至栈,O(m),第二个链表添加至栈,O(n),最坏情况下O(min(m,n)),就是两个链表的长度谁短,总的O(m+n+min(m,n))
空间复杂度:O(m+n)
5. 拼接字符串,感觉很熟悉但是又很陌生的方法,分别将两个链表合并起来,合并的两个链表就是一样长的,然后比较节点,那么那个相同的节点就是结果。

public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// 需要考虑不为空的情况
if (headA == null || headB == null) {
return null;
}
ListNode p1 = headA;
ListNode p2 = headB;
while (p1 != p2) {
// 不为null的时候继续遍历
p1 = p1.next;
p2 = p2.next;
if (p1 != p2) {
// 链表1结束,转为链表2
if (p1 == null) {
p1 = headB;
}
if (p2 == null) {
p2 = headA;
}
}
}
return p1;
}
运行截图
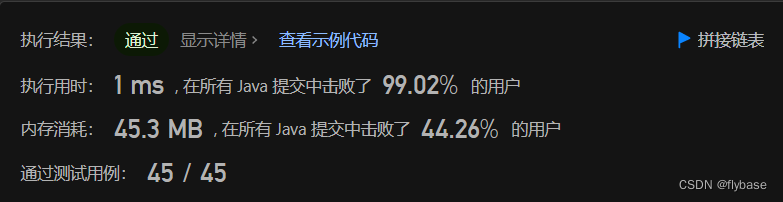
时间复杂度:最坏O(m+n)没有节点
空间复杂度:O(1)
总结:里面的两个if是没有关系的,不能使用else。假设链表1大于链表2的长度,那么第一个拼接的链表,公共点就在拼接的链表2上面,第二个拼接的链表,公共点就在链表1上面。核心思路还是将链表长度归一。
6. 差和双指针,假如公共子节点一定存在第一轮遍历,假设La长度为L1,Lb长度为L2.则|L2-L1|就是两个的差值。第二轮遍历,长的先走|L2-L1|,然后两个链表同时向前走,结点一样的时候就是公共结点了。这个方法仔细思考一下,和我第二个思路基本上一致,只不过对于部分进行了优化,比如之前的取最短的链表的长度,这个需要做两次判断,因为不知道哪个链表短,采取的方式也不一样,所以这里可以做一些优化。
ListNode p1 = headA;
ListNode p2 = headB;
int lengthA = 0;
int lengthB = 0;
while (p1 != null) {
lengthA++;
p1 = p1.next;
}
while (p2 != null) {
lengthB++;
p2 = p2.next;
}
p1 = headA;
p2 = headB;
// 判断长度
int sub = lengthA > lengthB ? lengthA - lengthB : lengthB - lengthA;
if (lengthA>lengthB){
int a =0;
while (a < sub){
p1 = p1.next;
a++;
}
}
if (lengthB>lengthA){
int b =0;
while (b<sub){
p2 = p2.next;
b++;
}
}
while (p1!=p2){
p1 =p1.next;
p2=p2.next;
}
return p1;
}
运行截图

时间复杂度:两个链表遍历长度O(m+n),判断sub谁小O(sub),同步找到公共节点O(min(m,n)),总的O(m+n+min(m,n)+sub);
空间复杂度:O(1)
总结: 相比于之前的代码这个还节省了内存。
总结
其中有3个方法都是围绕着链表的长度来的,很明显,这道题目核心就是链表长度。


















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











