






 本文介绍了如何在Python中使用pandas处理DataFrame,包括检测列和行的异常值,利用describe方法获取统计信息,以及进行排列、随机采样和将分类变量转换为哑变量以适应机器学习模型。
本文介绍了如何在Python中使用pandas处理DataFrame,包括检测列和行的异常值,利用describe方法获取统计信息,以及进行排列、随机采样和将分类变量转换为哑变量以适应机器学习模型。
检测和过滤异常值
案例:在一个含有正态分布数据的DataFrame中分别找出某列、某行绝对值大小超过3的值
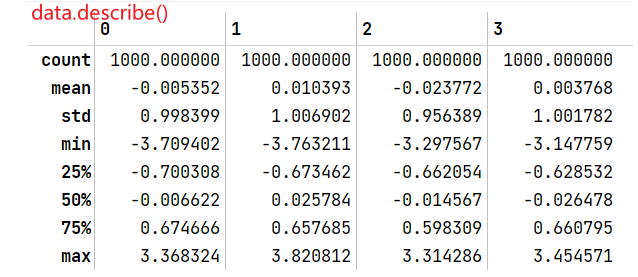
DataFrame的describe()方法生成正态分布的一些统计量,例如:
| 统计量 | 解释 |
|---|---|
| count | 数据的总数 |
| mean | 数据的平均值 |
| std | 数据的标准差,表示数据的离散程度 |
| min | 数据的最小值 |
| 25% | 数据的第25百分位数。也称为第一四分位数,表示数据中25%的观测值小于该值 |
| 50% | 数据的中位数。也称为第二四分位数,表示数据中50%的观测值小于该值 |
| 75% | 数据的第75百分位数。也称为第三四分位数,表示数据中75%的观测值小于该值 |
| max | 数据的最大值 |
注:以上均只统计非缺失值,缺失值不计入统计量
data = pd.DataFrame(np.random.randn(1000,4))#生成一个形状为(1000,4)的正态分布
data.describe()#用describe描述这个正态分布的一些统计量
-
找出某列中绝对值大小超过3的值
col = data[2]#找的是索引为2的列,即第三列 col[np.abs(col) > 3]#找出所有绝对值大于3 的值

-
找出所有包含 绝对值大于3的值 的行
data[(np.abs(data) > 3).any(1)]
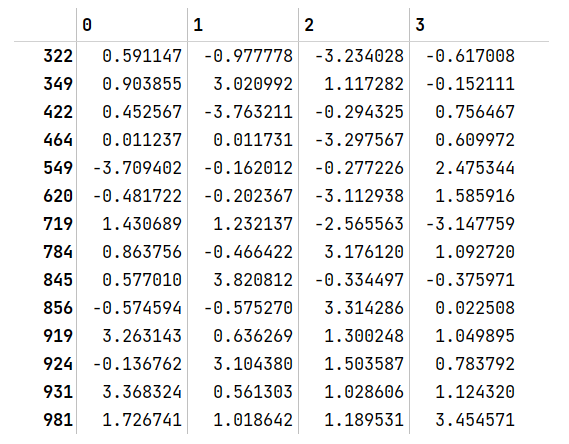
注释:
①np.abs(data) > 3会返回一个与原data大小相同并且全是布尔值的DataFrame,将每个数据都进行判断是否大于3,满足的则将该数据对应位置设置为true,否则为false
②.any()会判断一个布尔值序列中是否存在至少一个大于3的值,存在返回true,否则返回false。
.any(1)表示沿着行的方向进行判断,每行视为一个序列。由于①中已经将所有值变为布尔值,因此
若这行存在一个true则返回true
③data[(np.abs(data) > 3).any(1)]索引true的行
-
进一步操作
np.sign(data)可以根据数据的正负生成1,-1.head()用来展示前五行
排列和随机采样
numpy.random.permutation(5)可以生成含有0-4的重排数字的数组,传入的5为数组的大小。
take函数使用sampler构造的随机数组以重排列Series或DataFrame
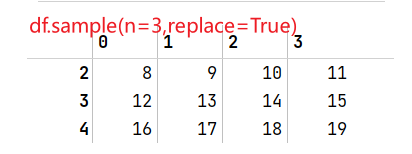
对Series或DataFrame使用.sample(n=3)方法可以随机抽取样本行而不修改原本数据,参数n=3表示随机抽取3行,参数replace=True表示允许样本重复选择(如果n的值大于原本行数则一定要replace=True,否则会报错)。
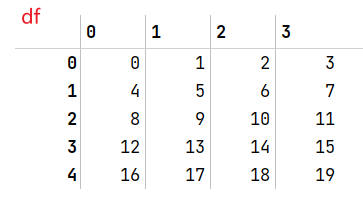
df = pd.DataFrame(np.arange( 5*4).reshape((5,4)))
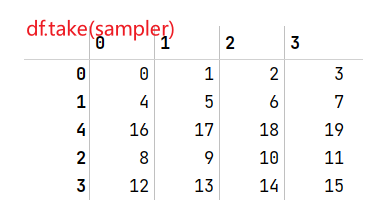
sampler = np.random.permutation(5)#permutation用来产生一个随机重排的数组
df.take(sampler)#按照生成的0,1,4,2,3的顺序重排了data
df.sample(n=3)#不按顺序随机取三行
df.sample(n=3,replace=True)#选取结果其实差不多


计算指标/哑变量
在数据分析和机器学习中,有时候需要将分类变量转变为数值形式以便在模型中使用。dummy :模型,假人
哑变量也可以叫作虚拟变量,是一种二进制变量,用于表示原始分类变量的不同取值。
-
get_dummies()函数说明例如,假设有一个表示颜色的分类变量,可能的取值是"Red"、“Blue"和"Green”。通过使用
get_dummies()函数,可以将这个分类变量转换成三个虚拟变量:一个用于表示"Red"、一个用于表示"Blue"、一个用于表示"Green"。每个虚拟变量在原始数据中对应的取值处为1,其他位置为0。
参数说明:
| 参数 | 解释 |
|---|---|
| data | 要进行转换的Series或DataFrame |
| columns | 进行转换的列名。如不指定,默认对所有分类变量进行转换 |
| prefix | 哑变量列名的前缀 |
| prefix_sep | 前缀与哑变量名称之间的分隔符 |
| dummy_na | 是否为缺失值创建哑变量列 |
| drop_first | 是否删除第一个哑变量列以避免多重共线性问题 |
| dtype | 指定哑变量的数据类型 |
-
简单使用示例
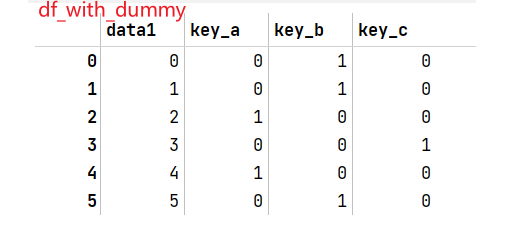
get_dummies为key中每个不同的值都创建一列,加上第一列索引共四列。参数
prefix可以给DataFrame的列标签加上一个前缀,方便和其他数据合并。使用
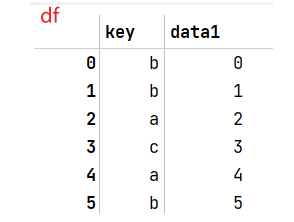
.join()方法将原data1和dummies合并df = pd.DataFrame({'key':['b','b','a','c','a','b'], 'data1':range(6)}) pd.get_dummies(df(['key']))#为'key'列创建哑变量,'key'中一共三个不同值(a,b,c) dummies = pd.get_dummies(df['key'],prefix='key')#每个列标签前面都会加上'key_' df_with_dummy = df[['data1']].join(dummies) df_with_dummy



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









