




 本文详细介绍了如何通过Python从iTunes备份的微信数据中提取聊天记录,进行数据清洗,然后使用jieba分词,最终生成词云图。涉及的工具有微信数据提取器、PyCharm及多个Python库。步骤包括数据获取、文本合并与清洗、分词、词云生成。提供了完整的代码示例。
本文详细介绍了如何通过Python从iTunes备份的微信数据中提取聊天记录,进行数据清洗,然后使用jieba分词,最终生成词云图。涉及的工具有微信数据提取器、PyCharm及多个Python库。步骤包括数据获取、文本合并与清洗、分词、词云生成。提供了完整的代码示例。
获取微信所有聊天记录数据并通过Python制作词云图
前言
本文纯原创,仅供学习、交流使用。不具有任何商业用途,版权归作者所有,如有问题请及时联系我以作处理。作者仅为一名大二学生,能力有限,并且也是我在csdn上的第一篇文章,如果文章中有些问题还请指出,谢谢大家。如果对你有帮助,请记得好评噢。
作者:做个财务自由的CEO
项目效果图:

接下来就是大家期待的过程了,具体如下:
一、整个项目一共经历三个步骤:
(1)首先获取微信聊天数据将其生成txt文本。
(2)对获取的文本进行数据清洗和处理
(3)生成词云图
二、此项目所涉及的工具:(资源我放在了百度网盘学要的可自行下载)
(1)获取微信聊天记录的工具:iTunes和一个微信数据提取器(微信数据提取器链接:https://pan.baidu.com/s/1DAVLmJ5LJx2BIZMKsFRg3g
提取码:9999 itunes可自行百度下载)
在这里要说明一下:因为作者的手机是ios安卓并不适用,如需要安卓请自行百度找方法
(2)pycharm编译器。(pycharm比较只能和方便,所以作者在这里推荐大家用pycharm,如需要还请自行在官网下载!)
(3)pycharm需要导入的库有:
import wordcloud import random import os import jieba from matplotlib import pyplot from PIL import Image import numpy
三:实现步骤:
1、通过iTunes备份手机的所有数据
2、使用微信数据提取器自动生成txt文本 (此时结果为一个文件夹,文件夹名是你的微信名字,文件夹里边有每个微信好友聊天的记录,若干个txt文本)
3、对txt文本进行处理。首先我们生成的是若干个聊天对象的txt文本,因此我们需要将其内容合并为一个txt文本以便接下来的数据清洗操作。因为生成的txt文本的聊天对话的开始显示的是聊天对象的微信名字和聊天时间记录。所以我们需要将其删除,
文本合并和数据清洗代码如下;
(1) 文本合并:
#文件合并
# -*- coding:utf-8 -*-
# file: FileMerage.py
# os模块中包含很多操作文件和目录的函数
# 获取目标文件夹的路径
#meragefiledir = os.getcwd() + '\\MerageFiles' os.getcwd()获得当前工作目录,即当前 Python 脚本工作的目录路径。
meragefiledir = r'C:\Users\song'+'\''+'song\Desktop\生成词云图\klys' #拼接txt文件所在的文件夹路径;
# 获取当前文件夹中的文件名称列表
filenames = os.listdir(meragefiledir) #os.listdir(某路径) 列出某目录下所有的目录和文件。
#print(len(filenames))
#for i in range(0,len(filenames)):
#print(filenames[i])
# 打开当前目录下的result.txt文件,如果没有则创建
# 文件也可以是其他类型的格式,如result.js
result_data = open(r'C:\Users\song'+'\''+'song\Desktop\微信备份数据汇总文本.txt', 'w',encoding='utf-8')
# 向文件中写入字符
# file.write('python\n')
list1=[] #将过滤txt文本的存储列表中
#筛选出txt文本并合并
count=0 #记录txt文本数量
for txt in filenames:
if "txt" in txt:
count += 1
list1.append(txt)
#print(list)
#合并文本
for txt_filename in list1: # 先遍历文件名
# 遍历获取文件夹下的所有txt文本
txt_filepath = meragefiledir + '\\' + txt_filename
#print(txt_filepath)
#遍历获取的单个txt文本,读取行数并保存
for line in open(txt_filepath, 'r', encoding='utf-8'):
result_data.writelines(line)
(2)数据清洗:
# # 数据清洗——删除昵称和时间记录
file=open(r'C:\Users\song'+'\''+'song\Desktop\微信备份数据汇总文本.txt',encoding="utf-8")
clear_file=open(r'C:\Users\song'+'\''+'song\Desktop\数据清洗微信备份数据汇总文本.txt',"w",encoding="utf-8")
for string in file:
end=string[0:string.find("):") + 2] #昵称和时间记录在字符串“)'”之前,这里我找到位置
string=string.replace(end, '') #因为昵称和时间记录在字符串“)'”之前,所以我要删除
clear_file.write(string)
4、我们使用jieba库进行分词:
代码如下:
with open(r'C:\Users\song'+'\''+'song\Desktop\数据清洗微信备份数据汇总文本.txt',"r+",encoding="utf-8") as text:
text=text.read()
text = " ".join(jieba.lcut(text)) #通过空格连接分好的词
若我们的云词有需要背景,则添加:mask,mask是word_cloud库中的对象的一个属性
mask = np.array(Image.open(r"C:\Users\song'song\Desktop\生成词云图\pikaqiu.png")) #将图片转换为多维数组
5、最后一步就是利用wordcloud库生成词云和matplotlib与PIL库展示图片

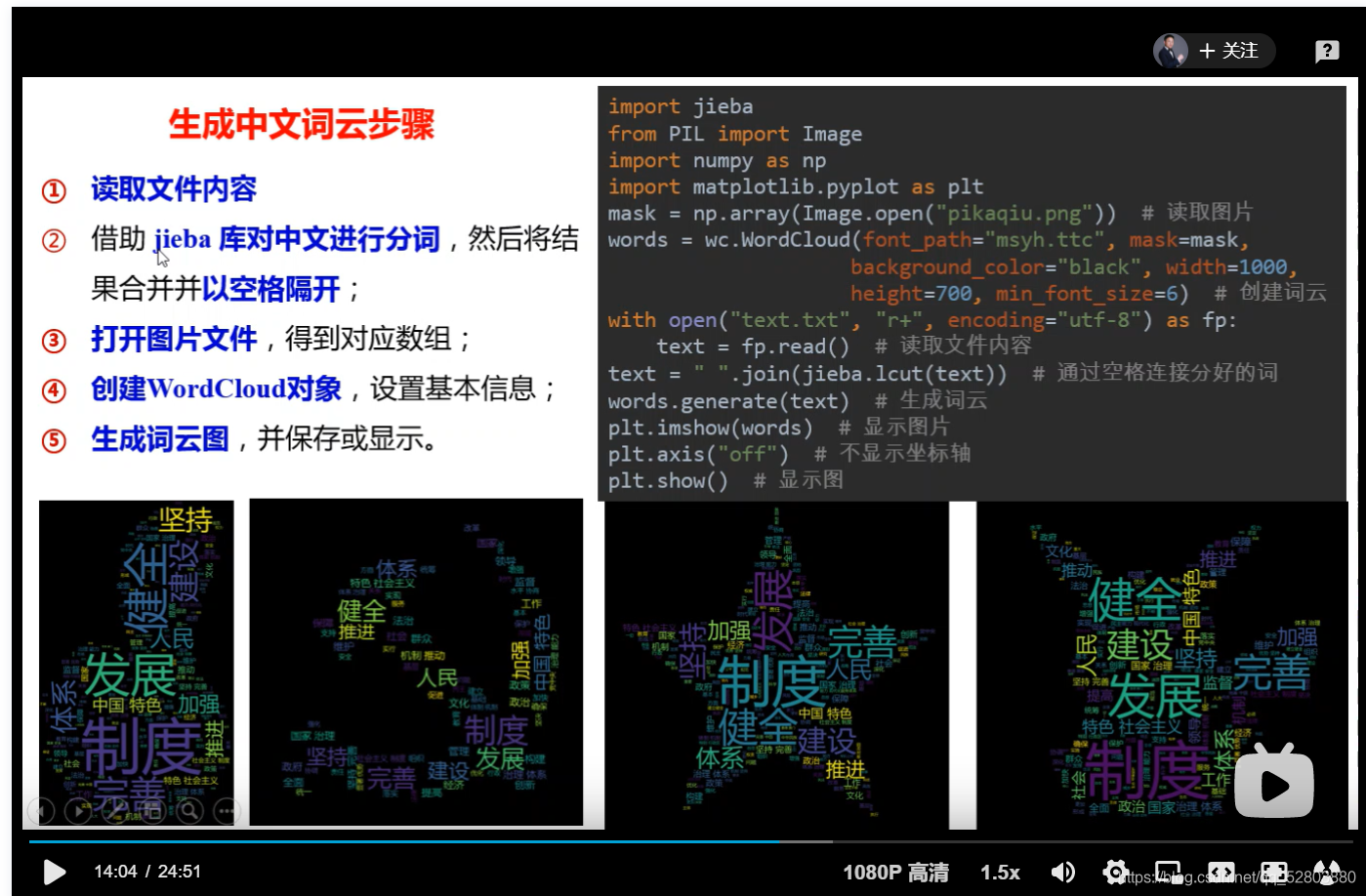
代码如下:
#创建wordcloud对象
word_cloud=wc.WordCloud(font_path=r"C:\Users\song'song\Desktop\生成词云图\msyh.ttc",mask=mask,background_color="black") #,width=1000,height=700,min_font_size=6
word_cloud.generate(text) #通过text生成词云图
word_cloud.to_file("微信备份数据词云生成图.png") #保存——将词云图转化为文件
#word_cloud.to_file(r"C:\Users\song'song\Desktop\词云demo.png") #保存——将词云图转化为文件
#关闭文件
result_data.close()
file.close()
clear_file.close()
plt.imshow(word_cloud) #显示图片
plt.axis("on")
plt.show() #显示图
以上就是全部过程啦,我没讲清楚的地方欢迎评论区留言,有问必答!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









