







 本文详细讲解了隐马尔可夫链的前向后向算法、预测问题中的维特比算法,以及学习问题的参数估计方法,强调了在SLAM中的应用及其重要性。
本文详细讲解了隐马尔可夫链的前向后向算法、预测问题中的维特比算法,以及学习问题的参数估计方法,强调了在SLAM中的应用及其重要性。
前言
视频讲解在我女朋友的B站『隐马尔可夫链预测问题-从维特比到SLAM』
在上一篇文章《终于有人把隐马尔可夫链的前向后向算法讲懂了!》中,我们讲解了隐马尔科夫链中三个基本问题中的概率计算问题的前向后向求解方法:
-
概率计算问题:给定模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测序列 x = { x 1 , x 2 , . . . , x n } x=\{x_1,x_2,...,x_n\} x={x1,x2,...,xn}计算在模型参数 λ \lambda λ下观测到x的概率 P ( x ∣ λ ) P(x|\lambda) P(x∣λ)(评估模型和观测序列之间的匹配程度)
-
预测问题:给定模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测序列 x = { x 1 , x 2 , . . . , x n } x=\{x_1,x_2,...,x_n\} x={x1,x2,...,xn},求使得 P ( y ∣ x , λ ) P(y|x,\lambda) P(y∣x,λ)最大的状态观测序列 y = { y 1 , y 2 , . . . , y n } y=\{y_1,y_2,...,y_n\} y={y1,y2,...,yn}(根据观测序列推断最有可能的状态序列)
-
学习问题:给定观测序列 x = { x 1 , x 2 , . . . , x n } x=\{x_1,x_2,...,x_n\} x={x1,x2,...,xn},调整模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π),使得该序列出现的概率 P ( x ∣ λ ) P(x|\lambda) P(x∣λ)最大(训练模型使其更好地描述观测序列)
这篇文章将主要讲解维特比算法,维特比算法是用来解决预测问题的主要算法,其核心思想是动态规划,这个问题与SLAM问题相似,都是获得一组观测序列(地图点),然后求解一组状态(机器人位姿),使得在该位姿下获得该观测的概率最大,最后简要说明学习问题的求解算法。
1.预测问题-维特比算法
主要思想:利用动态规划求解概率最大路径,这里一条路径对应着一个状态序列。
如果最优路径 y ∗ y* y∗在t时刻通过结点 y t ∗ y_t* yt∗,那么这条路径从起始结点到结点 y t ∗ y_t* yt∗的路径中,局部路径 y 1 : t ∗ y_{1:t}* y1:t∗一定是最优的。(每个结点 y t ∗ y_t* yt∗对应一个最优路径)
假定从起始时刻到t时刻上各个状态的最优路径已经找到,那么在计算从起始时刻到t+1时刻上的某个状态 s j s_j sj的最优路径时,只需要考虑从起始时刻到上一时刻所有N个状态 s i s_i si的最优路径,以及从si到sj的“距离”。
我们定义中间变量 δ t ( i ) \delta_t(i) δt(i):在t时刻,隐马尔可夫链沿着一条路径到达状态i,并输出观测序列的最大概率。
路径变量 ϕ t ( i ) \phi_t(i) ϕt(i):表示该路径上状态i的前一个状态。
这样说可能很晦涩,我们实例演示一下就很容易明白:
-
假设只有第一个观测-红球,那么最可能得到这个观测的状态是0还是1呢?我们分别计算它们的概率:假设第一个状态为0,概率为: δ 1 ( 0 ) = π ( 0 ) ∗ B 00 = 0.25 \delta_1(0)=\pi(0)*B_{00}=0.25 δ1(0)=π(0)∗B00=0.25;假设第一个状态为1,概率为: δ 1 ( 1 ) = π ( 1 ) ∗ B 10 = 0 \delta_1(1)=\pi(1)*B_{10}=0 δ1(1)=π(1)∗B10=0.显然如果只有一个观测,最优状态是0.
-
加入一个状态,第二个观测为黑球,第二个状态可能为0/1,我们分别计算第二个状态为0/1情况下,得到观测为黑球的概率:
-
如果第二个状态为0,它可能由第一个状态为0/1转移而来,这时我们要取一个概率更大的情况: δ 2 ( 0 ) = m a x ( δ 1 ( 0 ) ∗ A 00 ∗ B 01 , δ 1 ( 1 ) ∗ A 10 ∗ B 01 ) = 0 \delta_2(0)=max(\delta_1(0)*A_{00}*B_{01},\delta_1(1)*A_{10}*B_{01})=0 δ2(0)=max(δ1(0)∗A00∗B01,δ1(1)∗A10∗B01)=0,两种情况概率一样大,记录最优前一个节点 ϕ 2 ( 0 ) = 0 , 1 \phi_2(0)=0,1 ϕ2(0)=0,1;
-
如果第二个状态为1,它可能由第一个状态为0/1转移而来,这时我们要取一个概率更大的情况: δ 2 ( 1 ) = m a x ( δ 1 ( 0 ) ∗ A 01 ∗ B 11 , δ 1 ( 1 ) ∗ A 11 ∗ B 11 ) = 0 \delta_2(1)=max(\delta_1(0)*A_{01}*B_{11},\delta_1(1)*A_{11}*B_{11})=0 δ2(1)=max(δ1(0)∗A01∗B11,δ1(1)∗A11∗B11)=0,第一种情况更大,记录最优前一个节点 ϕ 2 ( 1 ) = 0 \phi_2(1)=0 ϕ2(1)=0
- 依次类推,我们最终计算出了最后一个节点的情况: δ 5 ( 0 ) = m a x ( δ 4 ( 0 ) ∗ A 00 ∗ B 00 , δ 4 ( 1 ) ∗ A 10 ∗ B 00 ) = 0.015625 \delta_5(0)=max(\delta_4(0)*A_{00}*B_{00},\delta_4(1)*A_{10}*B_{00})=0.015625 δ5(0)=max(δ4(0)∗A00∗B00,δ4(1)∗A10∗B00)=0.015625, ϕ 5 ( 0 ) = 1 \phi_5(0)=1 ϕ5(0)=1; δ 5 ( 1 ) = m a x ( δ 4 ( 0 ) ∗ A 01 ∗ B 10 , δ 4 ( 1 ) ∗ A 11 ∗ B 10 ) = 0 \delta_5(1)=max(\delta_4(0)*A_{01}*B_{10},\delta_4(1)*A_{11}*B_{10})=0 δ5(1)=max(δ4(0)∗A01∗B10,δ4(1)∗A11∗B10)=0, ϕ 5 ( 0 ) = 0 , 1 \phi_5(0)=0,1 ϕ5(0)=0,1;
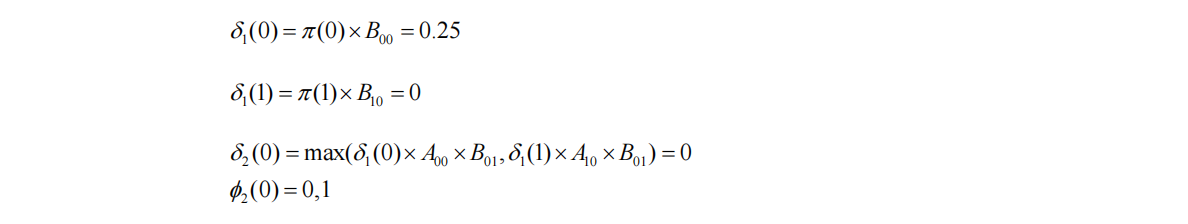
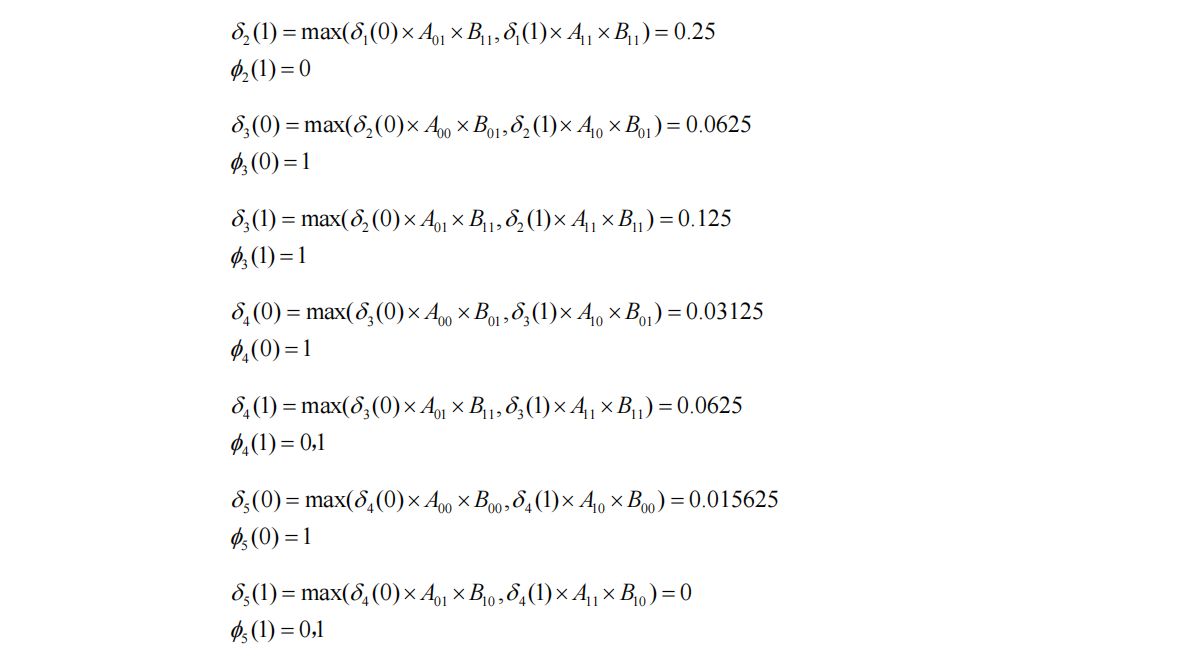
- 回溯:我们发现最后一个节点 δ 5 ( 0 ) \delta_5(0) δ5(0)概率更大,我们确定最后一个状态为0更好,然后根据 ϕ 5 ( 0 ) = 1 \phi_5(0)=1 ϕ5(0)=1回溯,其指向前一个最优状态 δ 4 ( 1 ) \delta_4(1) δ4(1),所以第4个状态确定为1,然后再根据 ϕ 4 ( 1 ) = 1 \phi_4(1)=1 ϕ4(1)=1回溯,指向前一个最优状态 δ 3 ( 0 ) 或 \delta_3(0)或 δ3(0)或\delta_3(1)$,然后我们对两条路径分别重复上述回溯,就可以得到最终路径:
0->1->0->1->0或0->1->1->1->0
2.学习问题
学习问题的主要解决目标是学习参数,主要方法是用模式识别中基于参数估计的方法区估计其中的参数,常用的方法有:基于参数估计的极大似然估计、贝叶斯估计;基于半参数估计的EM算法,分为有监督方法和无监督方法。
(1)有监督方法
训练数据包含𝑆个长度相同的观测序列和对应的状态序列 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x s , y s ) } \{(x_1,y_1),(x_2, y_2),...,(x_s,y_s)\} {(x1,y1),(x2,y2),...,(xs,ys)},利用极大似然法估计隐马尔可夫模型的参数。也就是P(X,Y)最大似然估计。
(2)无监督方法
将观测序列看作观测数据𝒳,状态序列看作不可观测的隐数据𝒴,隐马尔可夫模型等价
于含有隐变量的概率模型。
相应的参数学习可以由EM算法实现
总结
通过三篇文章,我们详细的介绍了马尔科夫链中的相关概念,以及三个基本问题的解法,马尔科夫链是各个领域应用十分广泛的数学工具,其结合了图论和概率论的相关算法模型,特别是在SLAM领域,很多现代的算法都是在马尔科夫链基础上发展而来,希望大家通过这三篇文章的讲解,可以比较好的理解相关内容!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









