







目录
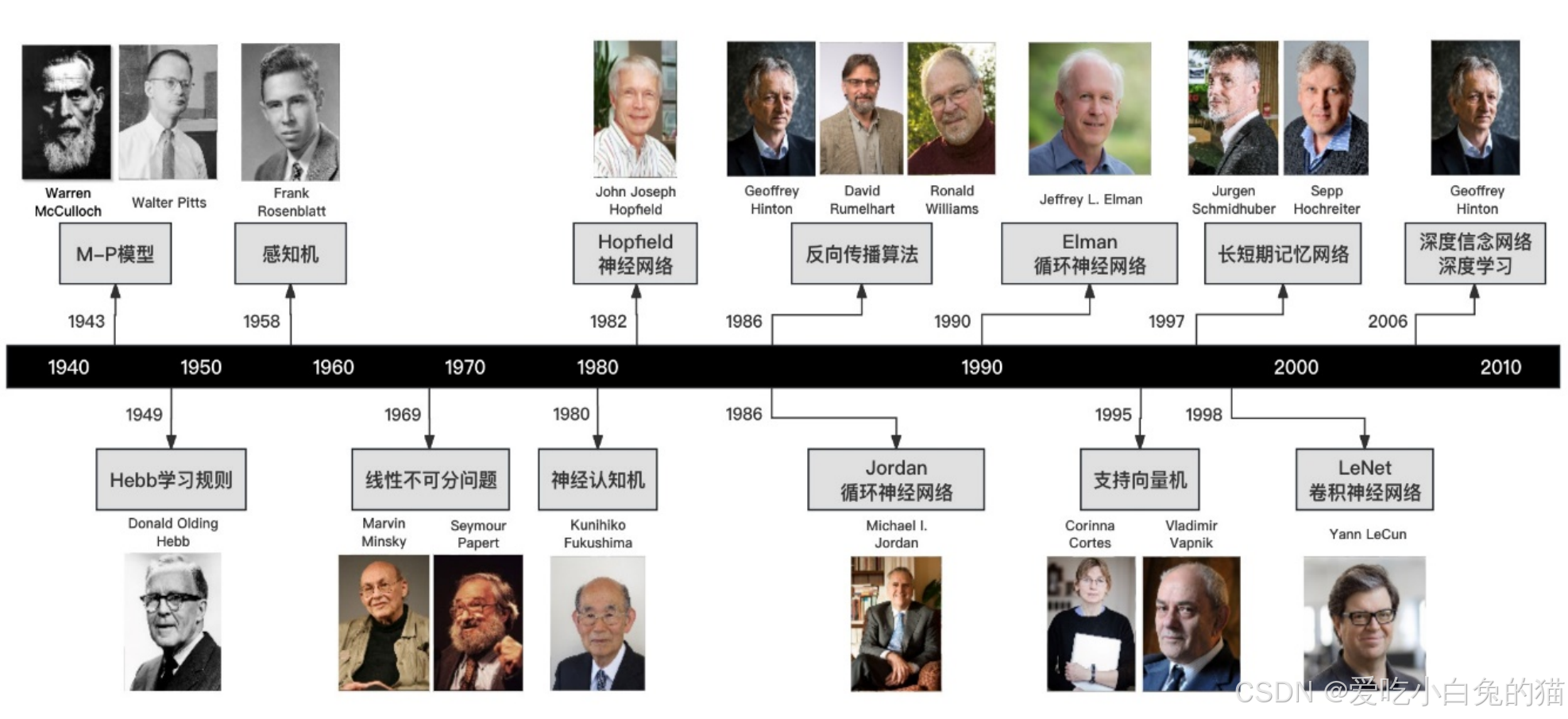
一、神经网络发展史
1.1 神经元和神经网络
生物神经网络:人脑,由众多神经元连接而成。当神经元“兴奋”时,就会向相邻的神经元发送化学物质,从而改变神经元内部的电位;如果某神经元的点位超过了一个“阈值”,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
在生物神经网络中,每个神经元与其他神经元相连。各个神经元传递复杂的电信号,树突接受到输入信号,然后对信号进行处理,通过轴突输出信号。生物神经元如下图:
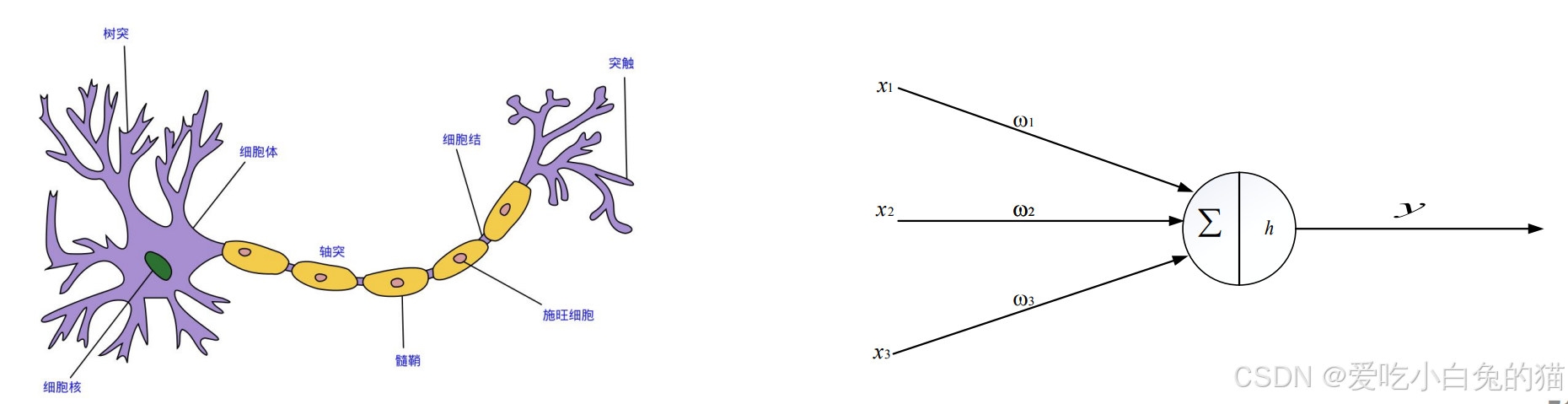
那么如何构建 人工神经网络 中的神经元呢?
1943 年,美国神经生理学家沃伦· 麦卡洛克(Warren McCulloch) 和数学家沃尔特 · 皮茨 (Walter Pitts)对生物神经元进行建模,首次提出了一种形式神经元模型,并命名为McCulloch-Pitts模型, 即后来广为人知的M-P模型。
受生物神经元的启发,人工神经元接受来自其他神经元或外部源的输入,每个输入都有一个相关的权值(w),它是根据该输入对当前神经元的重要性来确定的,对该输入加权并与其他输入求和后,经过一个激活函数f,计算得到该神经元的输出。
1.2 M-P模型
下图就是一个简单的神经元图(即M-P模型):
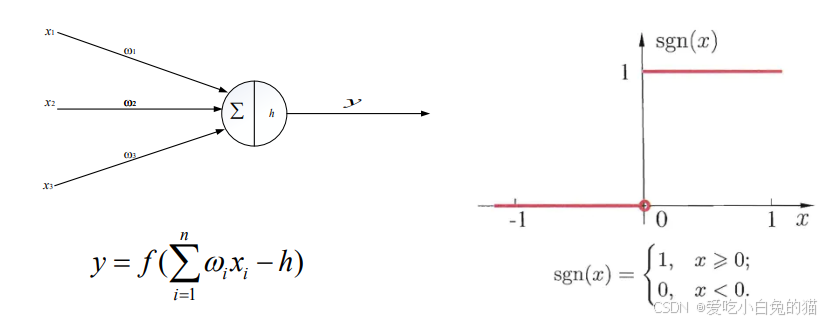
其中:
为各个输入的分量
为各个输入分量对应的权重参数
- h为偏置
- f为激活函数,常见的有tanh,sigmoid,relu
- y为神经元的输出
可见,一个神经元的功能时求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
M-P 模型可以表示多种逻辑运算 。取反运算可以用单输入单输出模型表示,即如果输入为0则输出1,如果输入为1则输出0。由MP模型的运算规则可得w = −2,h = −1。
逻辑或与逻辑与运算可以用双入单输出模输型表示。以逻辑与运算为例, = 1,
= 1, h = 1.5。当时还没有通过对训练样本进行训练来确定参数的方法,上述参数只能人为事先计算后确定。

把许多这样的神经元按照一定的层次结构连接起来,就得到了神经网络。
二、神经网络的种类
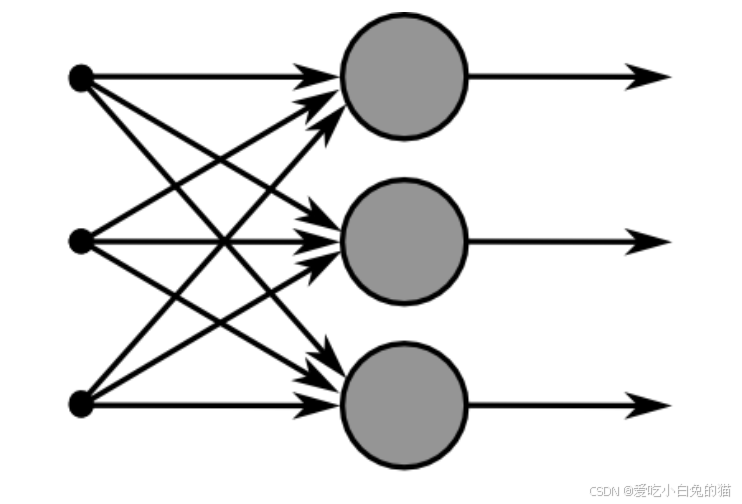
2.1 单层神经网络
单层神经网络时最基本的神经网络形式,由有限个神经元构成,所有神经元的输入向量都是同一个向量。由于每一个神经元都会产生一个标量结果,所有单层神经元的输出都是一个向量,向量的位数等于神经元的数目。
示意图如下:
2.2 感知器
1958 年,罗森布拉特( Rosenblatt )提出了感知器,与 M-P模型需要人为确定参数不同,感知器能够通过训练自动确定参数。
感知器是人工神经网络的基本构件之一,用于模拟生物神经元的工作方式。其核心思想是:对输入数据进行加权求和,并通过激活函数输出结果。感知器是最基本的线性分类器,适用于线性可分问题。
2.2.1 感知机结构
在原来MP模型的“输入”位置添加神经元节点,标志其为“输入单元”。
感知器的结构可以分为两个层次:
- 输入层:输入数据的传递层,不参与计算。
- 输出层:包含计算单元,负责根据输入和权重计算输出。
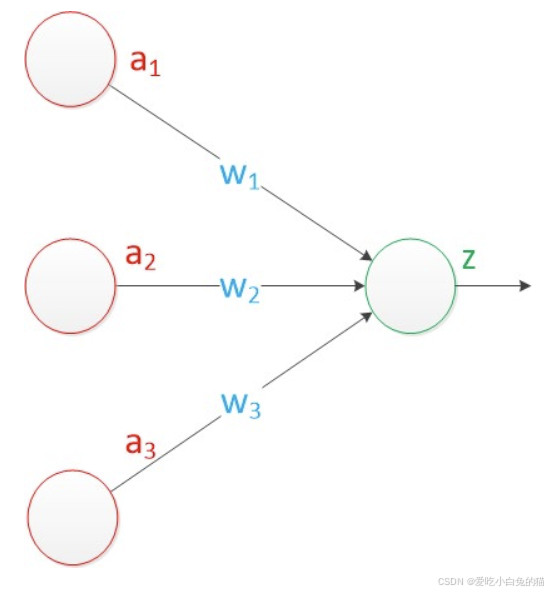
以下是感知器的基本结构示意图:
- 输入单元:
表示输入特征。
- 权重:
表示每个输入特征的权重。
- 加权求和:将输入特征和权重相乘并求和,公式为:
- 激活函数:g(x)是激活函数,用于将加权求和的结果映射到输出值。
2.2.2 感知机扩展
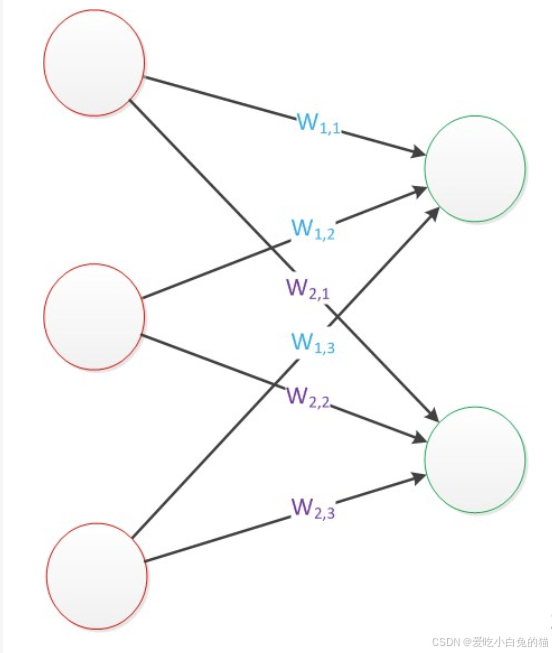
如果输出目标是多个值(例如一个向量),可以在输出层增加多个计算单元(即多个神经元)。每个输出单元都有独立的权重和偏置。
公式:
对于两个输出单元 z1 和 z2
计算公式分别为:
2.2.3 矩阵表示法
为了简化计算,我们可以利用矩阵运算来表示单层神经网络的计算过程。
输入向量:
权重矩阵:
输出向量:
2.2.4 效果
与神经元模型不同,感知器中的权值是通过训练得到的。因此,感知器类似一个逻辑回归模型,可以做线性分类任务。
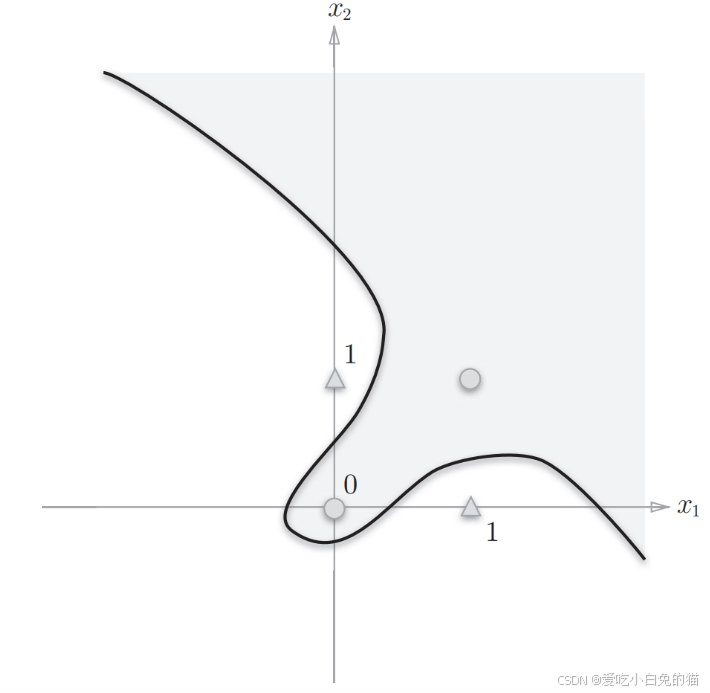
可以用决策分界来形象的表达分类的效果。决策分界就是在二维的数据平面中划出一条直线,当数据的维度是3维的时候,就是划出一个平面,当数据的维度是n维时,就是划出一个n-1维的超平面。
下图显示了在二维平面中划出决策分界的效果,也就是感知器的分类效果。
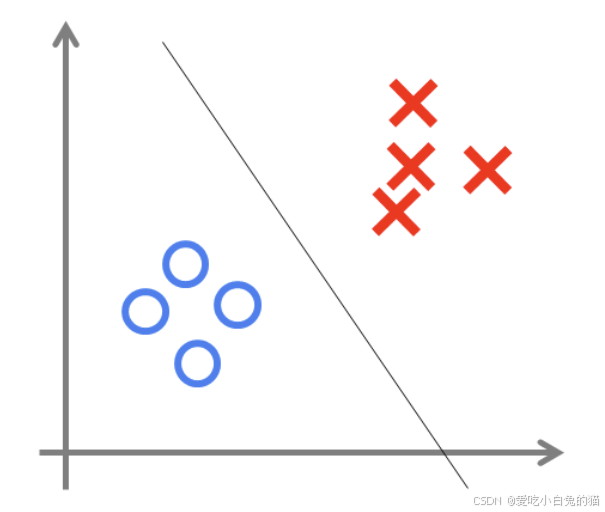
注意:单层感知器只能解决线性可分问题,而不能解决线性不可分问题。 为了解决线性不可分问题,我们需要使用多层感知器 。
2.2.5 例:感知器解决 AND 问题
(1) AND 数据集
- 输入:[x1,x2]
- 输出:y 输入 X= [[0,0],[0,1],[1,0],[1,1]],输出 Y = [ 0,0,0,1 ]
(2) 初始化
- 权重:w1=0.5 ,w2=0.5
- 偏置:b = −0.7
- 激活函数:阶跃函数 f(z)
(3) 计算过程
对于每个输入点,计算
- 输入 [0,0]:
- 输入 [0,1]:
- 输入 [1,0]:
- 输入 [1,1]:
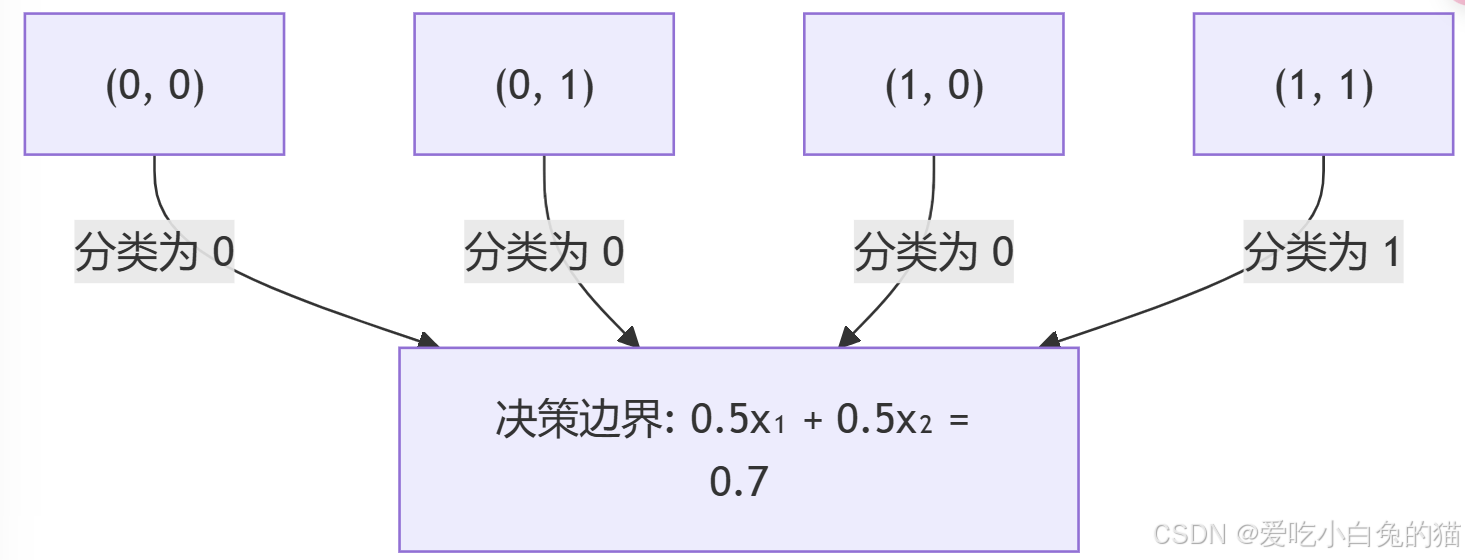
(4) 决策边界
感知器学习到的决策边界是:
这是一条直线,将输入空间分为两部分:
输出为1
输出为0
-
2.3多层感知器
2.3.1 多层感知机概念
多层神经网络就是由单层神经网络进行叠加之后得到的,所以就形成了 层 的概念,常见的多层神经网络有如下结构:
- 输入层(Input layer),众多神经元(Neuron)接受大量输入消息。输入的消息称为输入向量。
- 输出层(Output layer),消息在神经元链接中传输、分析、权衡,形成输出结果。输出的消息称为输出向量。
- 隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有一层或多层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性(robustness)更显著。
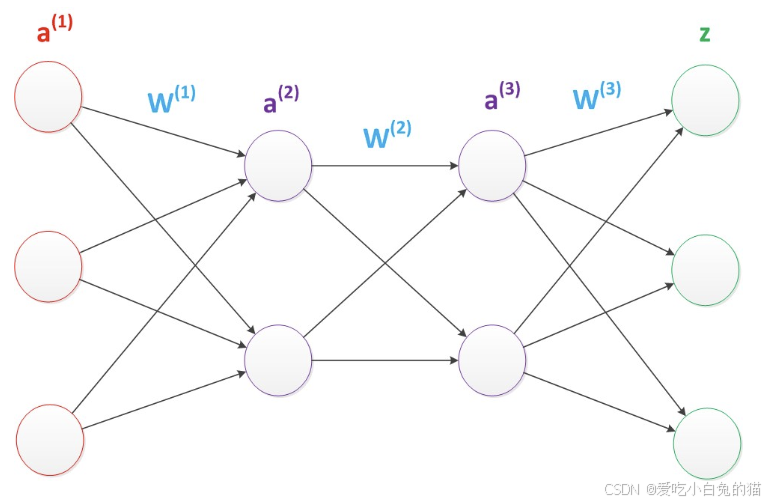
多层神经网络中,输出也是按照一层一层的方式来计算。从最外面的层开始,算出所有单元的值以后,再继续计算更深一层。只有当前层所有单元的值都计算完毕以后,才会算下一层。有点像计算向前不断推进的感觉。所以这个过程叫做“正向传播”。
2.3.2 多层感知机结构
1)如下图:W(1)中有9个参数,W(2)中有12个参数,W(3)中有12个参数。所以整个神经网络共有33个参数。
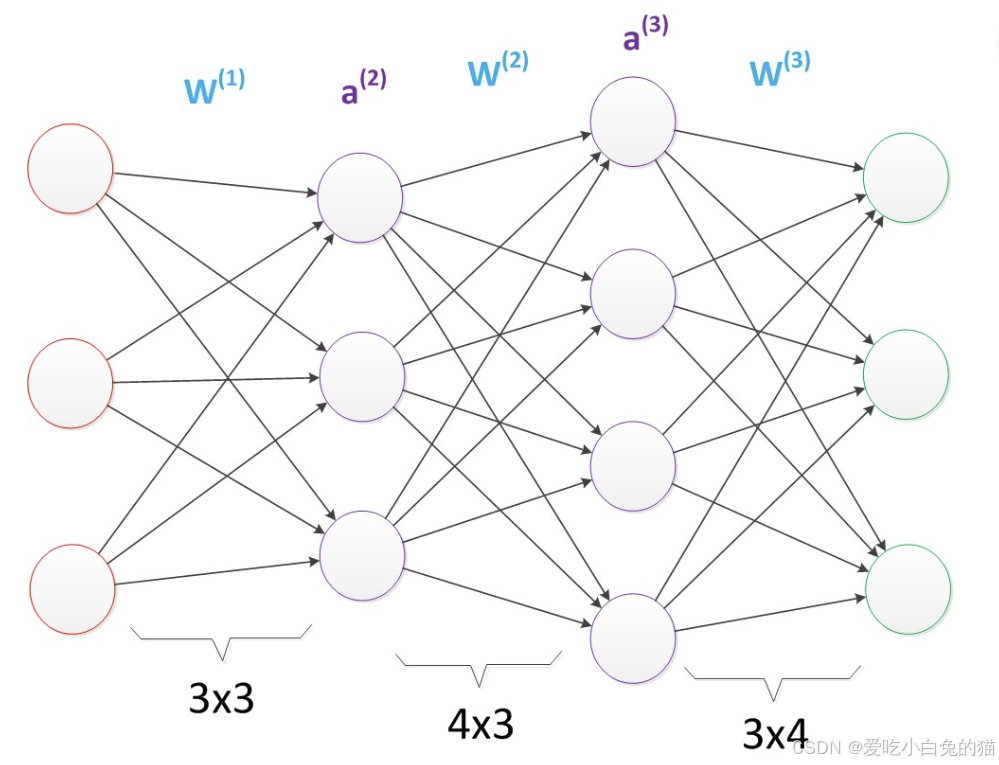
2)表示能力是多层神经网络的一个重要性质,请看下方的神经网络图:
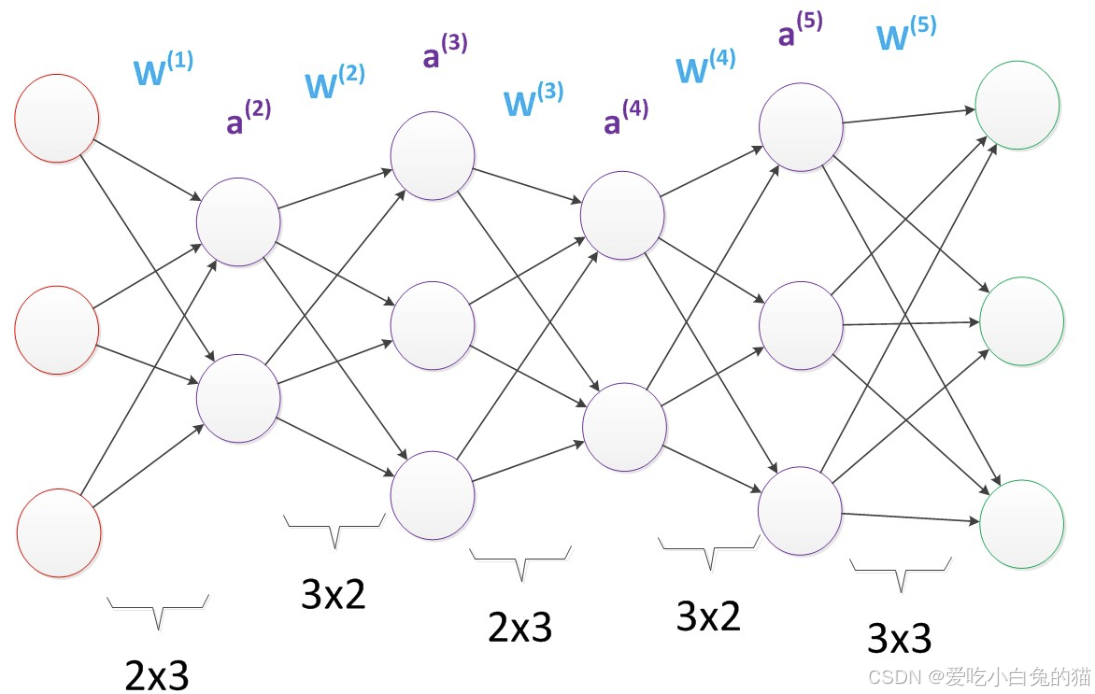
所包含的参数个数为:2*3+3*2+2*3+3*2+3*3=33,该网络中,虽然参数数量仍然是33,但却有4个中间层,是原来层数的接近两倍。这意味着一样的参数数量,可以用更深的层次去表达。
2.3.3 效果
与两层层神经网络不同。多层神经网络中的层数增加了很多。
增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。
更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
更强的函数模拟能力是由于随着层数的增加,整个网络的参数就越多。而神经网络其实本质就是模拟特征与目标之间的真实关系函数的方法,更多的参数意味着其模拟的函数可以更加的复杂,可以有更多的容量(capcity)去拟合真正的关系。
三、 激活函数
3.1 激活函数的概念
激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式。
不使用激活函数的话,神经网络的每层都只是做线性变换,多层输入叠加后也还是线性变换。因为线性模型的表达能力通常不够,所以这时候就体现了激活函数的作用了,激活函数可以引入非线性因素。
3.2 激活函数的作用
- 引入非线性:神经网络本质上是通过对输入数据进行加权求和来计算输出,如果没有激活函数,整个网络的输出将是输入的线性组合。激活函数通过引入非线性,使神经网络能够学习和逼近复杂的非线性关系。
- 提供输出范围限制:激活函数可以将输出限制在特定范围内(例如,0到1或-1到1),使结果更易解释或满足问题需求。
- 帮助梯度传播:某些激活函数可以避免梯度消失问题,促进深度网络训练。
3.3 激活函数的原理和分类
激活函数是作用于神经元加权和结果 的数学函数,用于决定神经元的输出。
激活函数的数学表达为: a=f(z) 其中:
- z 是神经元的加权和。
- f(z)是激活函数。
- a是激活函数的输出。
激活函数通过不同的数学形式控制输出的非线性程度、范围以及梯度传播特性。
- Sigmoid函数
- 双曲正切函数(Tanh函数)
- 线性整流函数(ReLU函数)
- Leakly ReLU函数
- ELU函数
- Parametric ReLU(PReLU)函数
- Softmax函数
- Swish函数
- Maxout函数
- Softplus函数
- Softsign函数
- 高斯误差线性单元(GELUs)
相关文档较多,此处不再赘述。
四、 BP算法
4.1 BP算法的提出和概念
BP算法是目前使用较为广泛的一种参数学习算法。
BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络。
我们无法直接得到隐层的权值,所以先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值。BP算法就是采用这样的思想设计出来的算法,它的基本思想:学习过程由信号的正向传播(求损失)与误差的反向传播(误差回传)两个过程组成。
4.2 BP算法的流程
1) 正向传播FP(求损失):根据输入的样本,给定的初始化权重值W和偏置项的值b, 计算最终输出值以及输出值与实际值之间的损失值。如果损失值不在给定的范围内则进行反向传播的过程; 否则停止W,b的更新。
2) 反向传播BP(回传误差):将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
由于BP算法是通过传递误差值δ进行更新求解权重值W和偏置项的值b, 所以BP算法也常常被叫做δ算法。
4.3 算法推导
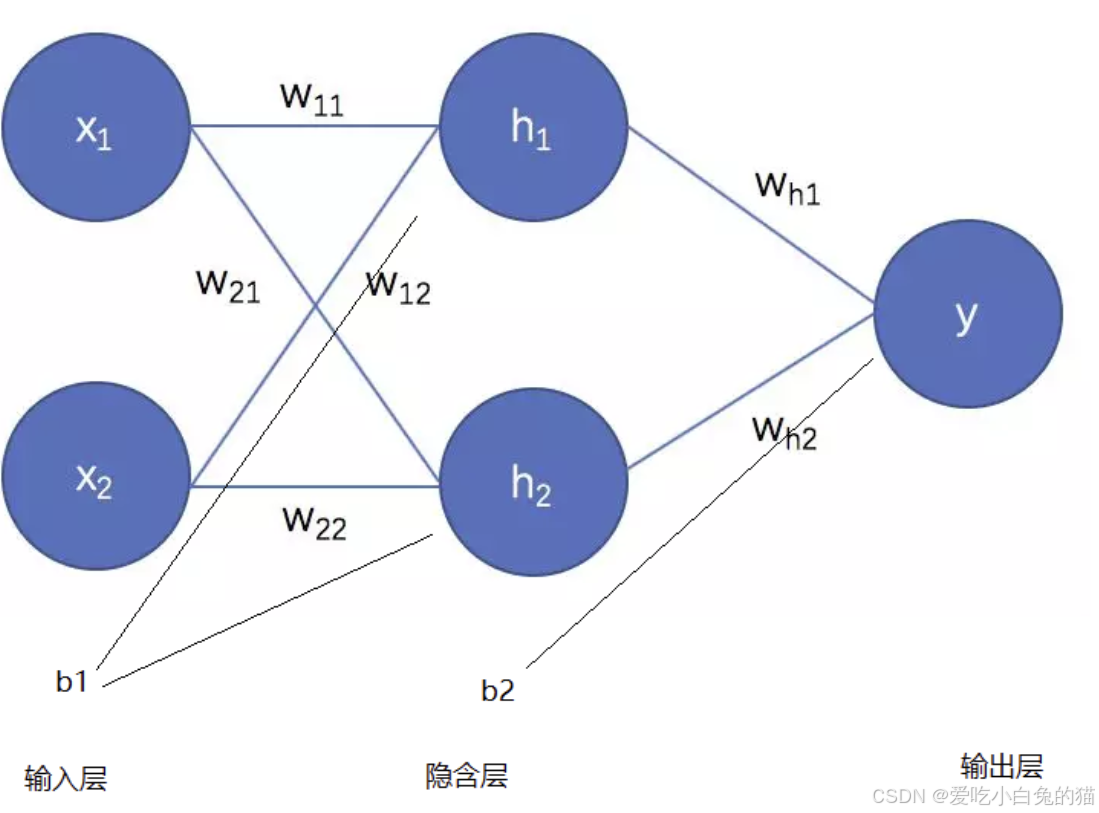
1.前向传播
1)输入层到隐藏层
w是权重,b是偏置项(输入到隐含):
2)隐藏层到输出层:
3)激活函数
激活函数采用 Sigmoid 函数,公式为:
每个节点的输出值通过激活函数计算得到。
2.误差计算
输出层的预测值为 ,真实值为 y(t)y(t)。误差采用平方差公式:
3.反向传播(Back Propagation)
反向传播的目标是通过梯度下降法最小化误差函数 E,更新权重和偏置项。
1)链式求导
以 为例,误差对
的梯度为:
各部分展开:
- 误差对输出值的偏导:
- 激活函数对净输入的偏导:
- 净输入对权重的偏导:
综合:
2)权重更新公式
其中
为学习率。
3)对其他权重的更新
类似方法可以更新其他权重和偏置项:
- 输入层到隐藏层的权重
;
- 隐藏层到输出层的权重
- 偏置项
4.4 BP算法经典实例
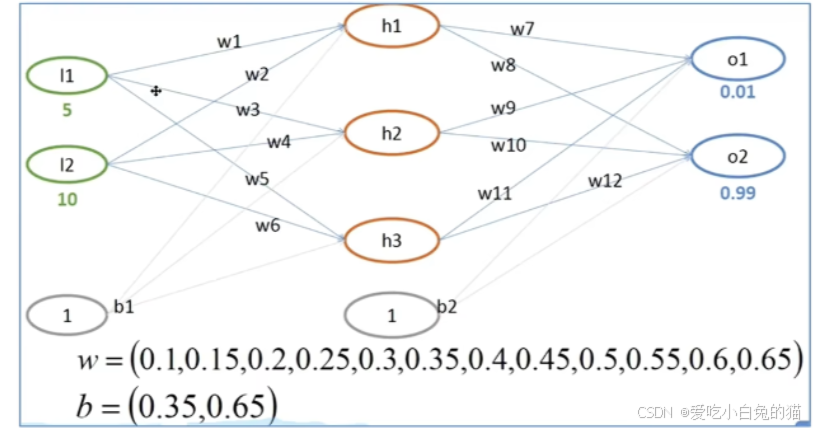
1) 问题背景
给定一个简单的神经网络(如图所示),包括:
- 输入层: 两个输入节点
和
,以及偏置节点
;
- 隐藏层: 三个隐藏节点
;
- 输出层: 两个输出节点
,以及偏置节点
。
初始权重和偏置:
- 权重 w=(0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65)
- 偏置 b=(0.35,0.65)
目标:通过 BP 算法更新权重,使得输出层的预测值 更接近真实值
。
2)前向传播(Forward Propagation, FP)
输入层到隐藏层:
则:
激活函数(Sigmoid)将净输入值转换为输出值:
具体计算:
隐藏层到输出层:
具体计算:
激活函数的输出值:
具体计算:
3)误差计算
4)反向传播(以为例)
梯度下降公式:
计算:
则:
更新:
类似方法更新其他权重即可。
五、总结
啃了好久的深度学习,也参考了很多网上的资料,算是集合各家智慧,记录一下最近的学习内容。



















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











