



hugging face的使用
官网链接:点击跳转 需要梯子才可以访问,文件下载的时候也需要魔法
 请先登录注册,接着需要申请使用:
请先登录注册,接着需要申请使用:
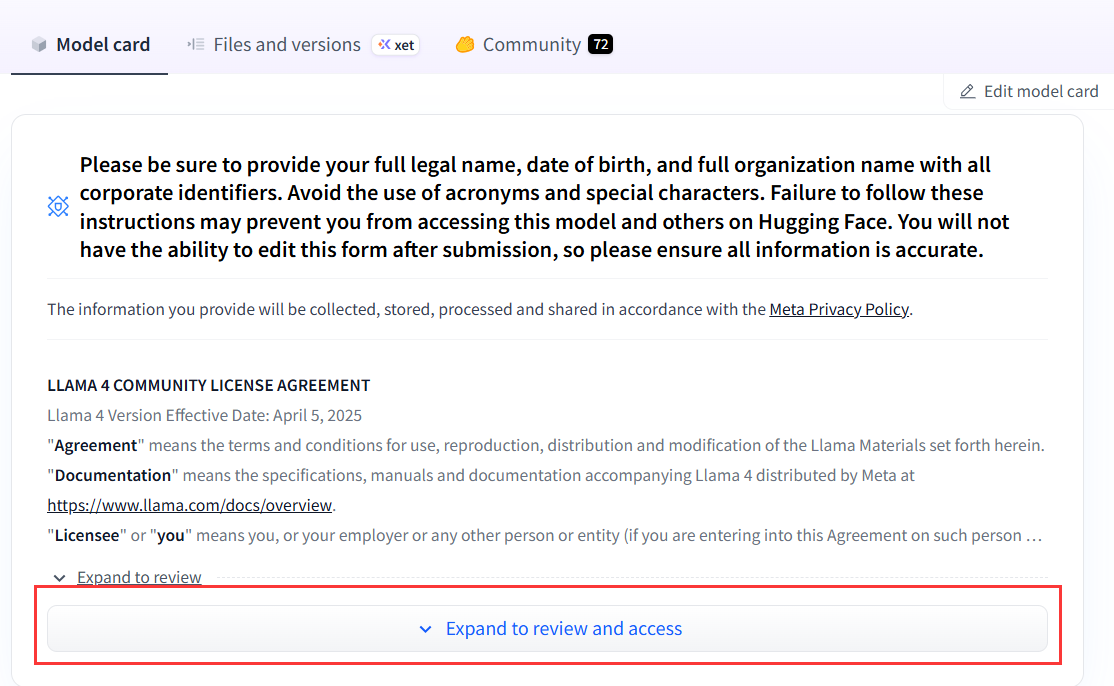
一直往下滑,填写个人信息,这里需要注意:尽量填其他国家,申请之后需要耐心等待,审核有时候比较快有时候比较慢,大家注意登录时填写的邮箱,申请通过后会在邮箱收到一个链接,点击跳转之后就可以使用啦!
模型的下载
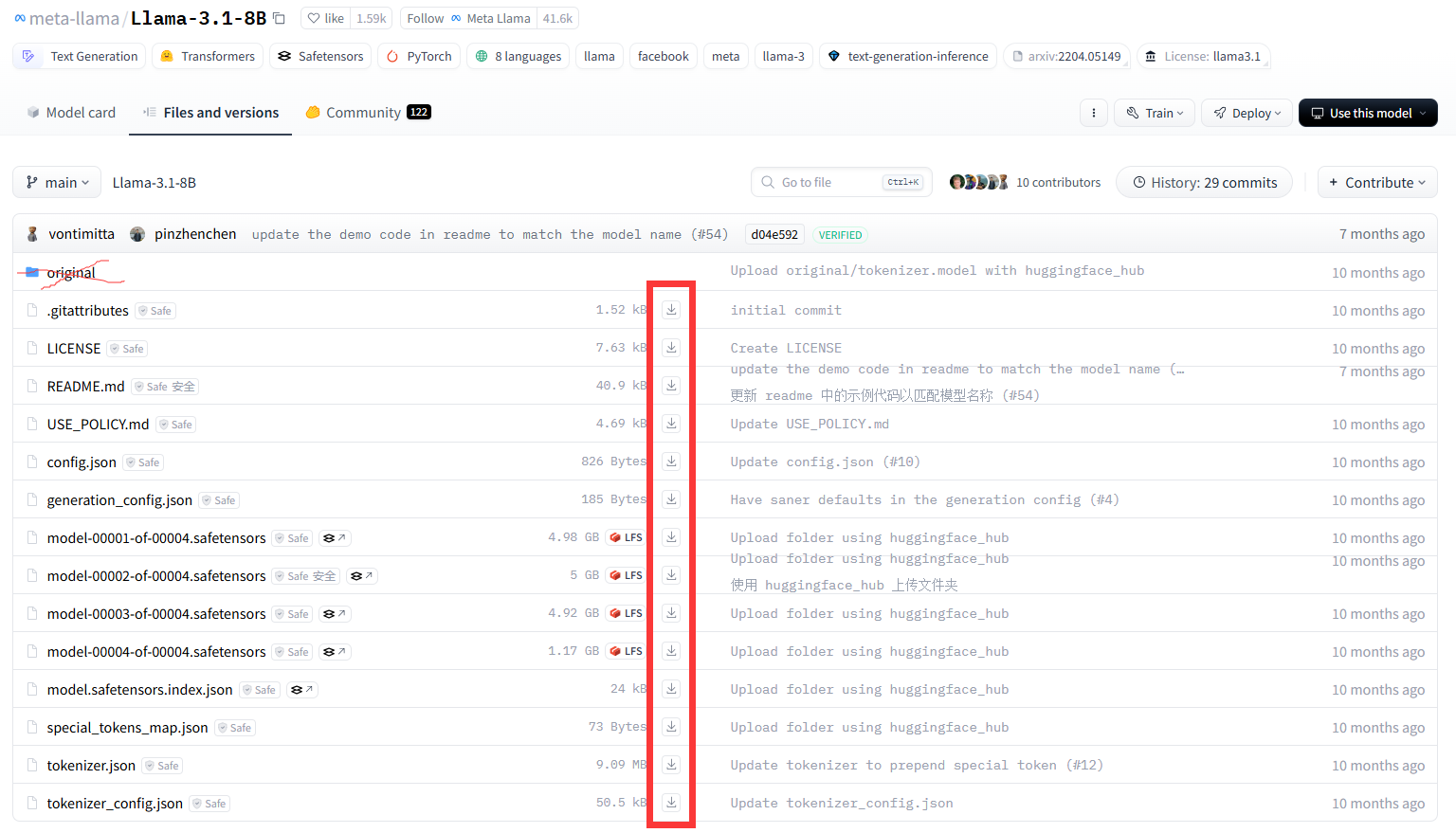
点击Files and versions,在下面的文件中,original文件夹不用下载,其他的文件都直接点击下载按钮下载到本地同一个文件夹目录下
meta-llama/Llama-3.1-8B模型的使用
下面给出 meta-llama/Llama-3.1-8B模型的使用,注意代码中的 auth_token 需要替换成前面创建的token。
注意检查自己的gpu型号和内存,这里采用的4090 24G运行的,最低可以采用 RTX 3090 24GB
如果是RTX 3060 12GB,需要进行4-bit量化处理,生成时启用cpu_offload应对长上下文。
# 安装库:pip install transformers torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import time
import os
# 配置环境变量(优化显存分配)
os.environ["TOKENIZERS_PARALLELISM"] = "false" # 避免tokenizer多线程警告
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True" # 防止显存碎片
try:
model_path = "xxx" # 填写前面下载的文件夹目录
# 全局路径如:"E:\\datasets\\meta-llama" 注意要用双斜杠
# 加载分词器和模型(FP16原生精度,无需量化)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16, # FP16加速
device_map="auto", # 自动分配GPU
low_cpu_mem_usage=True # 减少CPU内存占用
).eval() # 设为评估模式(减少计算图缓存)
# 输入提示
prompt = """ 请用中文回答以下问题:
问题:你认为学习AI有意义吗?
回答: """
print(f"\n📝 输入提示: {prompt}")
# 生成回复(启用优化参数)
input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
**input_ids,
max_new_tokens=500, # 生成长度
temperature=0.7, # 控制随机性
top_p=0.9, # 核采样(提高多样性)
do_sample=True,
repetition_penalty=1.1, # 避免重复
eos_token_id=tokenizer.eos_token_id, # 标记生成文本的结束位置
pad_token_id=tokenizer.eos_token_id # 避免警告 (Llama-3 需要)
)
# 打印结果(结构化输出)
print("\n--- 回复内容 ---")
print(tokenizer.decode(output[0], skip_special_tokens=True))
except Exception as e:
print(f"错误类型: {type(e).__name__}")
print(f"详细错误: {str(e)}")
if "CUDA out of memory" in str(e):
print("显存不足!建议:1) 减少max_new_tokens;2) 关闭其他GPU进程")
finally:
torch.cuda.empty_cache() # 清空显存


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









