







这里写目录标题
1.Dataset类
作用:告诉程序数据集在哪里、数据集的大小
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir # "dataset/train"
self.label_dir = label_dir # "ants"
self.path = os.path.join(self.root_dir, self.label_dir) # "'dataset/train\\ants'"
self.img_path = os.listdir(self.path) # 图片名称de列表
def __getitem__(self, idx):
img_name = self.img_path[idx] # '0013035.jpg'
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 'dataset/train\\ants\\0013035.jpg'
img = Image.open(img_item_path) # 读取图片需要路径
# img.show()
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
img, label = train_dataset[123]
img.show()
img, label = train_dataset[124]
img.show()
2.tensorboard
打开网址显示图象+指定端口
一般在logs下的文件删除后会执行该命令
tensorboard --logdir D:\6.PyCharm\1项目代码\test\TensorBoard\logs --port 6007
2.1add_scalar使用
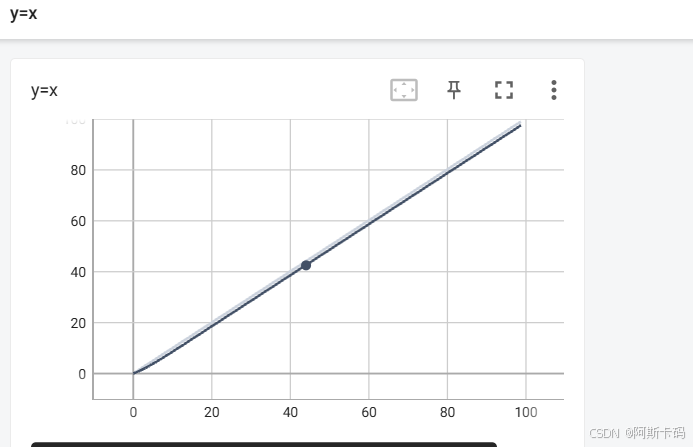
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# y = x
for i in range(100):
writer.add_scalar("y=x", i,i)
writer.close()
2.2add_image使用
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
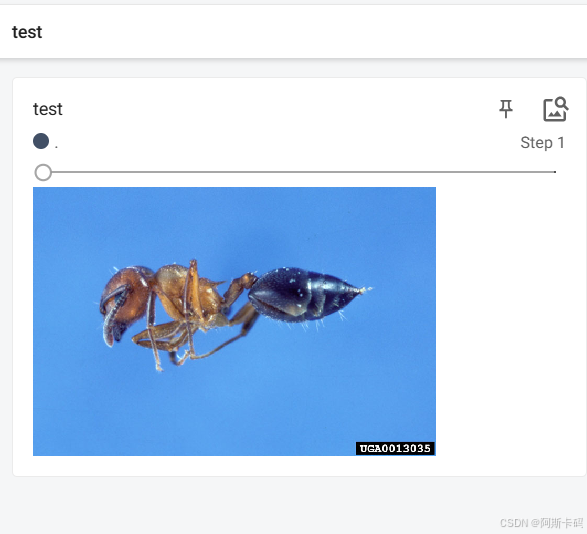
img_path = "D:\\6.PyCharm\\1项目代码\\test\data\\train\\ants_image\\0013035.jpg" # 5650366_e22b7e1065.jpg
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
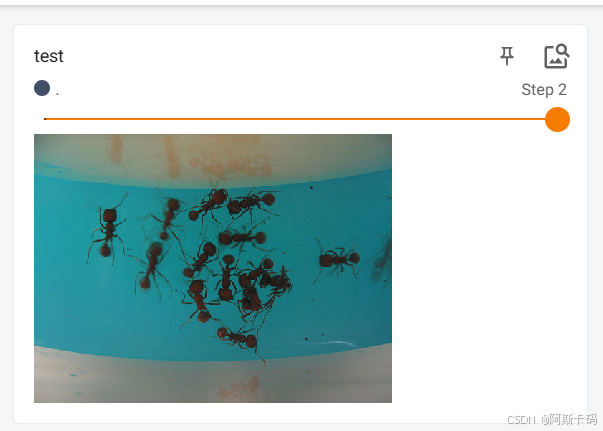
# "test"名称, img_array数据, 2步骤(同一名称下要设置不同的步骤), dataformats='HWC'数据格式
writer.add_image("test", img_array, 2, dataformats='HWC')
# writer.add_image("test", img_array, 1, dataformats='HWC')
writer.close()
3.Transforms类
3.1ToTensor
3.2ToPILImage
3.3Normalize
3.4Resize
3.5Compose
3.6RandomCrop
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img = Image.open("image/pytorch.jpg") # img(PIL类型)
writer = SummaryWriter("logs")
trans_totensor = transforms.ToTensor() # ToTensor(将PIL Image、Numpy-->tensor)
img_tensor = trans_totensor(img)
writer.add_image("Totensor", img_tensor); # 需要numpy类型、或者tensor类型
'''
trans_PIL = transforms.ToPILImage() # ToPILImage(将tensor、Numpy-->PIL Image)
img_PIL = trans_PIL(img_tensor)
img_PIL.show()
'''
# print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) # param1:均值 param2:标准差 (输入-均值)/标准差
img_norm = trans_norm(img_tensor) # img_norm(tensor类型)
# print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# img PIL -> resize -> img_resize PIL
trans_resize = transforms.Resize((512, 512)) # 固定(H,W) = (高,宽)
img_resize = trans_resize(img)
# img_resize PIL -> Totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
trans_resize_2 = transforms.Resize(256) # 1.输入int,将最小边设置=256,然后长边等比缩放 2.输入序列 固定的(h,w)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor]) # 参数是一系列的transforms的对象object
img_resize2 = trans_compose(img) # 将compose组合作用,img先Resize后Totensor操作
writer.add_image("Resize", img_resize2, 1)
trans_random = transforms.RandomCrop((100,200)) # 1.输入int类型, 不会等比缩放,会直接(512,512) 2.输入序列(h,w) ==>(高,宽)=(h,w)
trans_compose2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose2(img)
writer.add_image("RandomHW", img_crop, i)
writer.close()
4.torchvision中数据集的使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 图片默认PIL类型---》转换为tensor类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
# 1.root="./dataset"当前文件的相对位置 , 2.train=True是否为训练集, 3.transform=dataset_transform将图片使用该方法转换, 4.download=True是否下载到root路径中)
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
# print(test_set[0])
# print(test_set.classes)
# img, target = test_set[0]
# print(img)
# print(test_set.classes[target])
print(test_set[0])
writer = SummaryWriter("logs_dataset_transform")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
5.DataLoader的使用
当shuffle=False是,不打乱数据集顺序,batch_size=64就是隔63张取一张。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False, transform=torchvision.transforms.ToTensor())
# dataset=test_set:数据集,
# batch_size=4:一次取四张图片,
# shuffle=True:True为打乱顺序,
# num_workers=0:进程数,
# drop_last=False:True最后不能整除的舍弃
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=False, num_workers=0, drop_last=True)
# 测试数据集中的第一张图片+target
# img, target = test_set[0]
# print(img.shape)
# print(target)
writer = SummaryWriter("logs_dataloader")
for epoch in range(2):
i = 0
for data in test_loader:
imgs, targets = data
writer.add_images("dataloader_shuffle" + str(epoch), imgs, i)
i = i + 1
# print(imgs.shape)
# print(targets)
writer.close()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











