







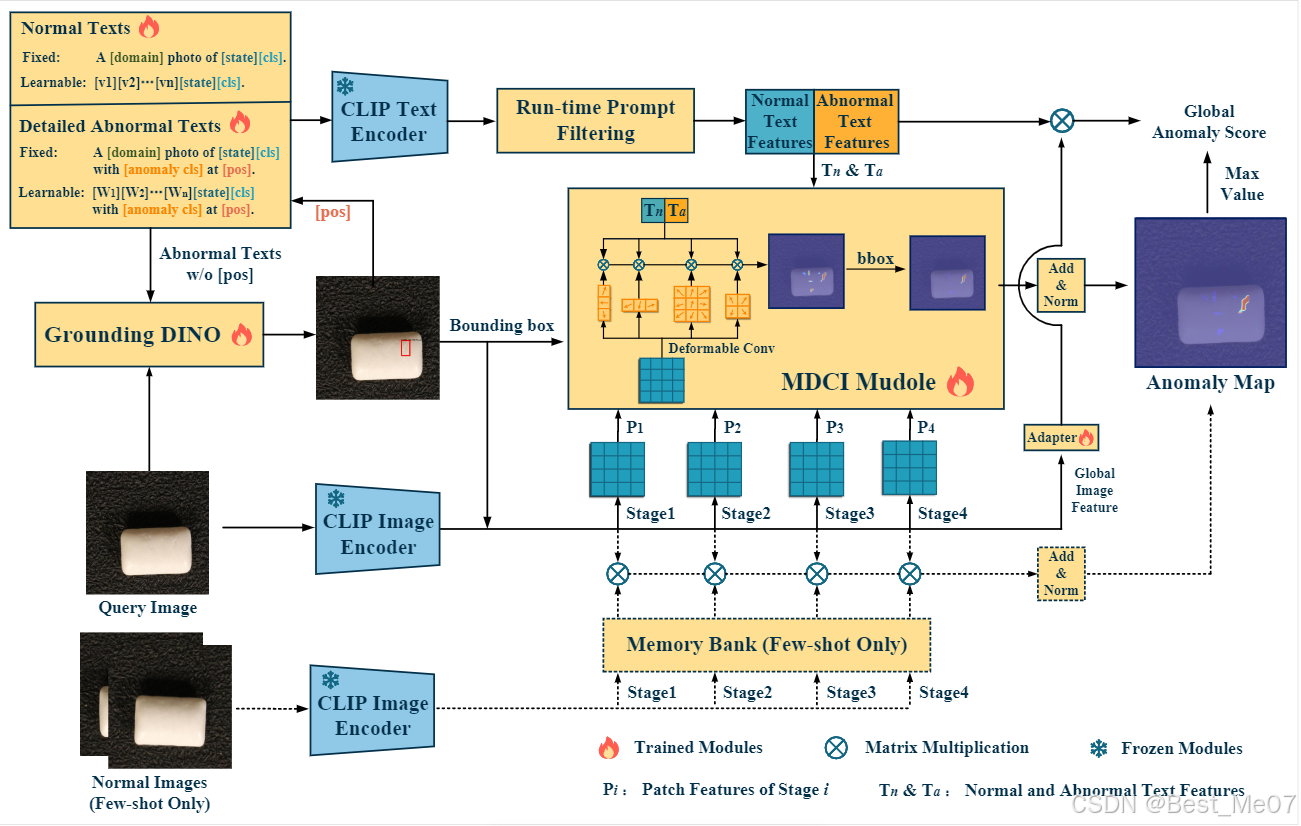
FiLo++实验步骤总结
训练阶段
步骤1:训练可学习模板
• 输入:正常/异常图像及其类别名称(III.B.2)
• 操作:
- 使用固定模板(如“A [domain] photo of [state][cls]”)与可学习文本向量结合。
- 通过LLM生成细粒度异常描述,插入模板的
[anomaly cls]字段。 - 利用交叉熵损失优化可学习文本向量和适配器参数。
• 输出:优化后的可学习文本模板和适配器参数。
• 原文片段:
“By inserting the fine-grained anomaly descriptions generated by LLMs into the [anomaly cls] field of the adaptive text templates, we obtain complete text prompts.” (III.B.2)
“Training is conducted with a batch size of 1.” (IV.C)
/
模板解析:A [domain] photo of [state][cls]
在FiLo++的文本模板设计中,每个占位符的含义如下:
1. [domain]
• 含义:图像所属的领域或场景类别,用于关联特定应用场景的上下文语义。
• 作用:增强模型对不同领域(如工业、医学)的图像特征适配能力。
• 例子:
• 工业检测:industrial
• 医学影像:medical
• 自然场景:natural
• 原文片段:
“The domain field adapts the prompt to specific application scenarios (e.g., industrial or medical).” (III.B.2)
2. [state]
• 含义:图像的状态描述,区分正常(intact)或异常(defective)状态。
• 作用:引导模型关注正常与异常状态的语义差异。
• 例子:
• 正常状态:intact
• 异常状态:defective(或具体异常类型,如cracked, scratched)
• 原文片段:
“The [state] field explicitly separates normal and abnormal semantics to improve discriminative power.” (III.B.2)
3. [cls]
• 含义:目标物体或场景的具体类别名称,提供细粒度的类别信息。
• 作用:定位特定类别物体的正常/异常特征。
• 例子:
• 工业零件:circuit board(电路板)
• 医学影像:lung tissue(肺组织)
• 日常物品:bottle(瓶子)
• 原文片段:
“The [cls] field is replaced by the category name of the test sample for fine-grained alignment.” (III.B.1)
完整模板示例
-
工业场景正常图像:
"An industrial photo of intact circuit board"
•[domain]=industrial,[state]=intact,[cls]=circuit board -
医学场景异常图像:
"A medical photo of defective lung tissue"
•[domain]=medical,[state]=defective,[cls]=lung tissue -
自然场景异常图像:
"A natural photo of cracked bottle"
•[domain]=natural,[state]=cracked,[cls]=bottle
设计原理(III.B.2)
通过动态填充占位符,模板能够:
- 领域适配:通过
[domain]关联不同场景的语义特征。 - 状态区分:通过
[state]强化正常/异常状态的对比学习。 - 细粒度对齐:通过
[cls]实现类别级别的特征对齐。
原文片段:
“The adaptive template dynamically adjusts text prompts based on domain, state, and category, enabling precise cross-modal alignment.” (III.B.2)
注释结束//
步骤2:训练MDCI模块
• 输入:CLIP图像编码器提取的多层图像块特征(III.C.3)
• 操作:
- 设计多尺度可变形卷积核,聚合不同尺度和形状的图像块特征。
- 结合位置增强的文本特征进行跨模态交互,计算相似度得分。
- 使用Focal Loss和Dice Loss优化定位结果。
• 输出:训练后的多尺度可变形卷积参数。
• 原文片段:
“We design deformable convolution kernels of varying sizes and shapes to aggregate regions of the patch features.” (III.C.3)
“The learning rate for the MDCI module is set to 1e-4.” (IV.C)
测试阶段
零样本场景
步骤1:生成细粒度异常描述
• 输入:测试图像类别名称(III.B.1)
• 操作:调用LLM(如GPT-4o)生成该类别可能的异常类型描述。
• 输出:细粒度异常文本描述(如“裂纹”“划痕”等)。
• 原文片段:
“We utilize the powerful knowledge of LLMs to generate detailed anomaly types for each test sample.” (III.B.1)
步骤2:生成文本特征
• 输入:LLM生成的描述与模板组合(III.B.2)
• 操作:
- 结合固定模板(含位置信息)与可学习模板生成文本提示。
- 使用运行时提示过滤策略(去除重叠区间的模糊提示)。
• 输出:过滤后的正常/异常文本特征集合。
• 原文片段:
“A runtime prompt filtering strategy that boosts the distinguishability between normal and abnormal text features.” (III.B.3)
步骤3:异常检测与定位
• 输入:测试图像(III.C)
• 操作:
- 使用Grounding DINO初步定位异常区域,抑制背景干扰。
- 通过MDCI模块进行多尺度可变形卷积特征交互,生成异常分数图。
- 结合全局图像-文本相似度得分计算最终异常分数。
• 输出:图像级异常得分(Img-AUC)和像素级定位图(Px-AUC)。
• 原文片段:
“DefLoc utilizes Grounding DINO for initial anomaly localization to filter out backgrounds.” (III.C.1)
“MDCI integrates multi-scale deformable cross-modal interaction to handle varying anomaly shapes.” (III.C.3)
少样本场景
步骤1:构建正常样本记忆库
• 输入:少量正常样本(III.C.4)
• 操作:提取正常样本的块级特征并存储至记忆库(Memory Bank)。
• 输出:记忆库中存储的各阶段块特征。
• 原文片段:
“Extract patch-level features from known normal samples and store them in memory banks.” (III.C.4)
步骤2:位置增强的块特征匹配
• 输入:测试图像与记忆库(III.C.4)
• 操作:
- 基于DefLoc的初步定位结果约束匹配区域。
- 计算测试图像块特征与记忆库的最小余弦距离。
- 融合视觉-语言匹配结果与块匹配结果。
• 输出:结合定位约束的异常定位图。
• 原文片段:
“Constraining the regions involved in patch matching using DefLoc’s localization results.” (III.C.4)
关键实验设置(IV.C)
- 主干网络:CLIP-L/14@336px,冻结图像/文本编码器。
- 训练参数:
• 可学习模板学习率:1e-3
• MDCI模块学习率:1e-4
• 适配器学习率:1e-5 - 推理优化:高斯滤波器(σ=4)平滑异常得分图。
原文片段:
“We employ the publicly available CLIP-L/14@336px model as the backbone, freezing the parameters… Training is conducted for 15 epochs using AdamW optimizer.” (IV.C)
“A Gaussian filter with σ=4 is applied during testing.” (IV.C)
总结:FiLo++通过训练阶段优化文本模板与跨模态交互模块,测试阶段结合LLM生成的细粒度描述、多尺度可变形定位和少样本记忆库匹配,实现零样本与少样本下的高效异常检测。

















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









