







今天是纯文字,代码没有保存,所以没有实验结果图哦,忘记保存代码了。哈哈,开玩笑的,我这么严谨的人怎么可能没有图呢?
实验五 内排序
1. 实验目的:
掌握各种内排序算法设计及其比较。
2. 仪器与材料:
装有Windows操作系统和VC++6.0编程环境的PC机一台。
3. 实验内容:
编写一个程序exp10-13. cpp,随机产生n个1~99的正整数序列,分别采用直接插入排序、折半插入排序、希尔排序、冒泡排序、快速排序、简单选择排序、堆排序和二路归并排序算法对其递增排序,求出每种排序方法所需要的绝对时间。
4. 实验记录:
插入排序、冒泡排序、二叉树排序、二路归并排序及其他线形排序是稳定的;选择排序、希尔排序、快速排序、堆排序是不稳定的。
函数功能:
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。
归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
实验结果
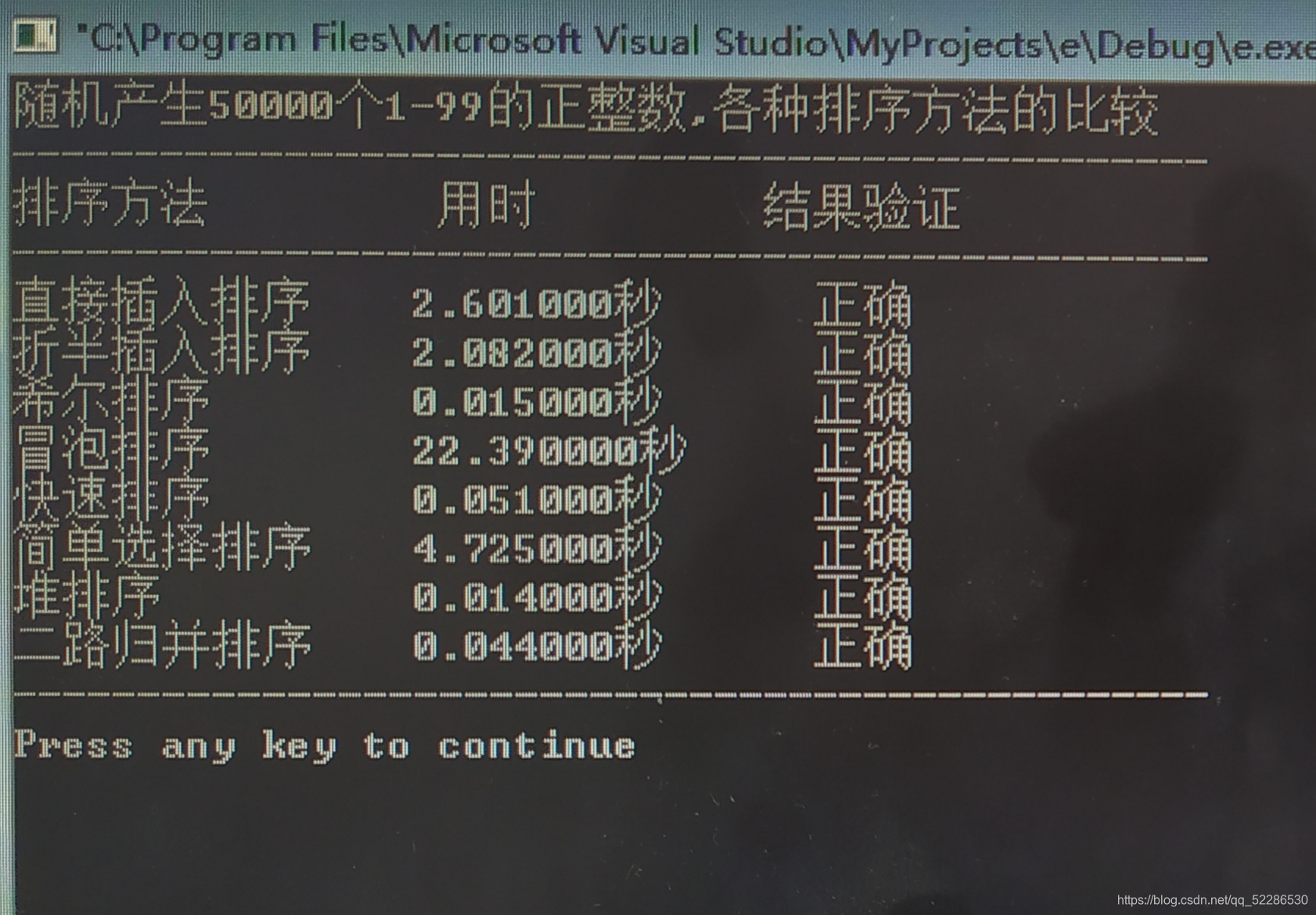
5. 实验体会:
当n较大时,关键字元素比较随机,对稳定性没要求宜用快速排序。当n较大时,关键字元素可能出现本身是有序的,对稳定性有要求时,空间允许的情况下,宜用归并排序。当n较大时,关键字元素可能出现本身是有序的,对稳定性没有要求时宜用堆排序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









