






Tokenizer简介
数据预处理
- S1 分词;
- S2 构建词典:根据数据分词结果,构建词典映射(这一步并不绝对,如果用预训练次向量,词典映射要根据词向量文件进行处理);
- S3 数据转换:根据构建好的词典,将分词处理后的数据做映射,文本序列——》数字序列
- S4 数据填充与截断:对过短的数据填充,过长的截断,保证数据长度符合模型接受范围,同时Batch内的数据维度大小一致。
基本使用
- 加载保存(from_pretrained / save_pretrained)
- 分词(tokenize)
- 查看词典(vocab)
- 索引转换(convert_tokens_to_ids / conver_ids_to_tokens)
- 填充截断(padding / truncation)
- 其他输入(attention_mask / token_type_ids)
加载和保存
加载时会因为,代理,导致无法下载
解决方法1:手动下载
解决方法2:输入代理
import requests from transformers import AutoTokenizer proxies = { "http": "http://your-proxy-address:port", # 替换为你的代理地址 "https": "http://your-proxy-address:port", } tokenizer = AutoTokenizer.from_pretrained( "uer/roberta-base-finetuned-dianping-chinese", proxies=proxies )### hugging face的Model、tokenizer加载保存在“ C:\Users\用户\.cache\huggingface ”
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器 tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese") tokenizer### 也可以将tokenizer另存为一个路径
# tokenizer 保存到本地
tokenizer.save_pretrained("./roberta_tokenizer")
# 从本地加载tokenizer# 从本地加载tokenizer tokenizer = AutoTokenizer.from_pretrained("./roberta_tokenizer/") tokenizer
分词
tokens = tokenizer.tokenize(sen) tokens
查看词典
tokenizer.vocab #查看词典 tokenizer.vocab_size #词典大小 21128
索引转换
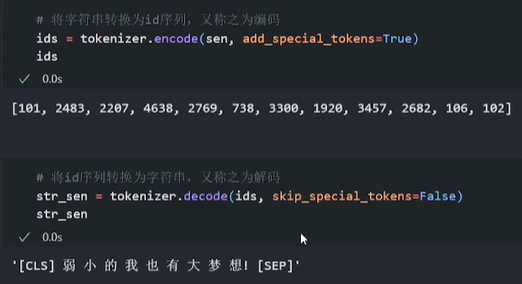
# 将词序列转换为id序列 ids = tokenizer.convert_tokens_to_ids(tokens) ids # 将id序列转换为token序列 tokens = tokenizer.convert_ids_to_tokens(ids) tokens # 将token序列转换为string str_sen = tokenizer.convert_tokens_to_string(tokens) str_sen##更便捷的方式
# 将字符串转换为id序列,又称之为编码 ids = tokenizer.encode(sen, add_special_tokens=True) ids # 将id序列转换为字符串,又称之为解码 str_sen = tokenizer.decode(ids, skip_special_tokens=False) str_senadd_special_tokens # 添加标记位 即首尾101、102
skip_special_tokens # 跳过标记位输出 即首尾 cls、sep
填充与截断
#填充: padding=‘max_length’,max_length=15 ##用0在末尾填充至15
#截断: truncation=True ##即与padding相斥,表示截断
# 填充 ids = tokenizer.encode(sen, padding="max_length", max_length=15) ids # 截断 ids = tokenizer.encode(sen, max_length=5, truncation=True) ids##填充截断,默认带首尾表示符号
填充输出
截断输出
其他输入部分
下述俩个返回相同
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15) inputs inputs = tokenizer(sen, padding="max_length", max_length=15) inputs#返回:input_ids编码序列,token_type_ids同长度0序列, attention_mask编码序列中的非填充字符标识(0表示填充字符)
处理Batch数据
输入Batch
sens = ["弱小的我也有大梦想", "有梦想谁都了不起", "追逐梦想的心,比梦想本身,更可贵"] res = tokenizer(sens) res输出每个序列即为多维列表

Fast / Slow Tokenizer
tokenizer——Fast
- Fast:基于Rust实现,速度快;额外返回值:offset_mapping、word_ids
- Slow:基于Python实现
## Fast fast_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese") fast_tokenizer ## Slow 即use_fast=False slow_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese", use_fast=False) slow_tokenizerFast额外返回
下述inputs,额外包含key——‘offset_mapping’,并包含属性word_ids()
inputs = fast_tokenizer(sen, return_offsets_mapping=True) inputs inputs.word_ids()inputs #‘offset_mapping’——每个词的位置
inputs.word_ids() #其中Dreaming被拆成俩个词——7,7


特殊Tokenizer加载
即本地自定义或他人的Tokenizer,进行加载
#即通过,trust_remote_code=True
# 新版本的transformers(>4.34),加载 THUDM/chatglm 会报错,因此这里替换为了天宫的模型
tokenizer = AutoTokenizer.from_pretrained("Skywork/Skywork-13B-base", trust_remote_code=True)
tokenizer
















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









