






一、OCT概述
声明:概述部分摘取自参考文献,编者并非医学专业因而不保证完全正确,如有错误欢迎指出。
OCT是一种基于弱相干光干涉原理,检测入射弱相干光或若干个散射信号在生物组织不同层次上的背反射,从而通过扫描获得生物组织二维或三维结构图像的成像技术。
OCT是一种非侵入性检查,它可以拍摄眼睛视网膜层的横截面照片,使用近红外光谱范围内的光波,其在视网膜层的穿透深度为几百微米,这让眼科医生能够根据视网膜层进行诊断。因此,它是检测和定量视网膜疾病和视网膜异常的重要方式。对青光眼、老年性黄斑变性(AMD)、糖尿病性视网膜病变、脉络膜新生血管(CNV)、糖尿病性黄斑水肿(DME)等视网膜疾病和视网膜异常进行检测/量化,提供治疗指导是眼科医生的重要方式。
光学相干层析成像(OCT)可以进行无创的高分辨率三维(3D)成像,在生物医学领域得到了广泛的应用。
二、论文阅读
2.1 基于深度学习的OCT图像分类研究
论文研究内容:研究OCT在两种视网膜黄斑区病变早期观测的应用。
难点:①研究的视网膜OCT图像公共数据集在数量规模上较小。
②不同组织采集的视网膜OCT图像质量和大小存在巨大差异
论文成果:利用网络结构的特征来减少对数据集大小的依赖,增强对不同数据集之间差异的适应性。
算法综述:(原图来自论文)
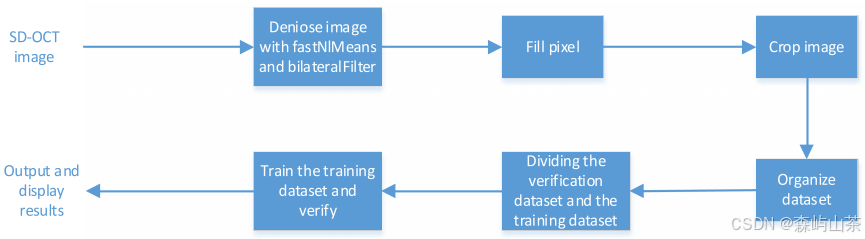
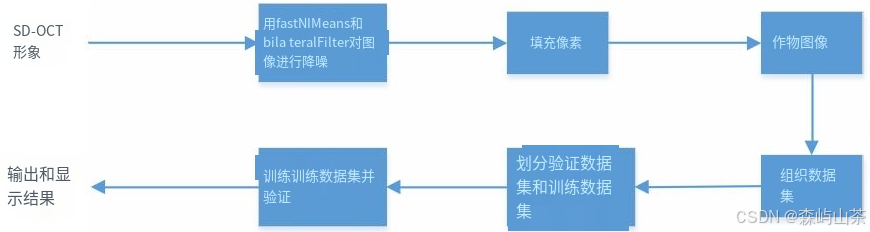
视网膜OCT图像分类方法的整个过程:①采用FastNIMeans和bilateralFller方法进行去噪。②填充像素,最后裁剪图像,完成预处理。③然后将不同的数据集组织成验证集和训练集。④将数据集发送给神经网络模型进行训练和输出。
FastNIMeans:NL-Means的全称是Non-Local Means,又称做非局部平均去噪,是利用了整幅图进行了去噪,所以相对来说,运行时消耗的时间也会更多。
双边滤波方法:一种非线性的滤波方法,是结合图像的空间邻近度和像素值相似度的一种折中处理,同时考虑空域信息和灰度相似性,达到保边去噪的目的。
卷积结构如下:
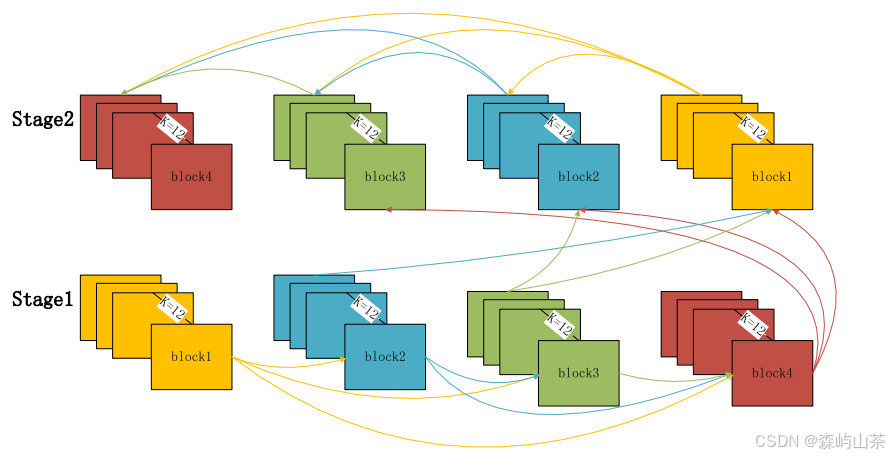
阶段1:进行特征的前向传递(将每个块提取的特征传递到下一个块中)。
阶段2:在前向传递的同时对特征进行回传(每个块提取的特征传递到最后一个块)。
阶段3:每个主块将输出输入特征xi (i = 0,1,2)和在其Stage2中提取的特征作为下一个块的输入,也起到了多尺度卷积的作用。
最后,将每个区块的stage2输出特征与输入特征xi(i = 0,1,2)进行整体池化,生成其最终特征。将三个主要块的最终特征拼接起来,生成我们最终的预测特征,这个预测特征被称为Prediction,它通过使用softmax激活函数的一层完全连接的层来生成我们最终的预测标签。
预测生成方式(ResNet网络)如下图:
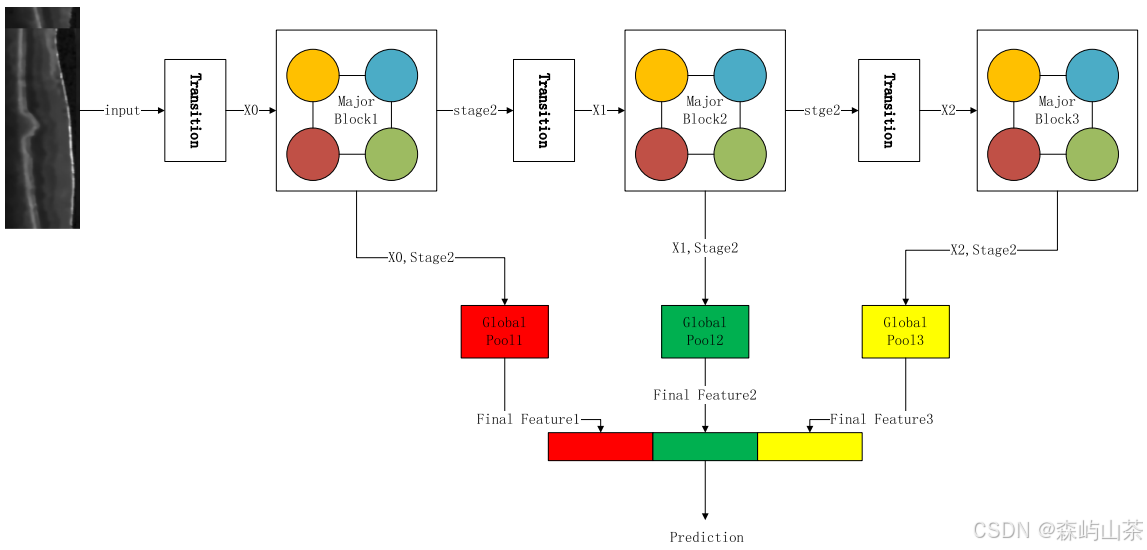
xi (i = 0,1,2)为每一层的输入特征,stage2为每一区块的输出特征,Final feature为每一区块的最终预测特征,将三个Final feature拼接生成prediction。图中Transition块中的卷积和池化操作起到了特征提取的作用。
选择ResNet50预训练模型进行迁移学习。对神经网络模型和参数进行微调:将最后一个全连接层的输出通道调整为3,使其输出为AMD、DEM和Normal的概率值。采用SGD作为梯度优化器,学习率为0.0001。
ResNext引入了Inception的多分支结构,将ResNet的单一卷积转换为多分支卷积[18]。使用ResNext101的预训练模型进行迁移学习。
对网络模型和参数进行如下微调:以SGD为梯度优化器,将输出层输出神经元的个数调整为3,dropout值为0.5,学习率为0.0001。
DenseNet具有增强特征传播和鼓励特征重用的双重特性[16]。由于这两个特点,我们选择DenseNet121的预训练模型进行迁移训练。DenseNet121的网络模型和参数微调与ResNext101相同。
ResNet支持特征重用,而DenseNet支持新特征探索,这对于学习良好的表示都很重要。双路径网络具有共同的特征,同时保持了通过双路径架构探索新特征的灵活性[15]。采用DPN92的预训练模型进行迁移学习训练。DPN92的网络模型和参数微调与ResNext101相同。
2.2 基于深度学习算法的OCT图像视网膜疾病分类(未完成)
论文研究内容:使用深度学习模型,自动将患者的OCT图像分为脉络膜新生血管(CNV)(多数湿性DME患有CNV)、糖尿病性黄斑水肿(DME)、Drusen(干性AMD)和正常四类。
难点:①需要大量的标记数据,这些数据成本高且难以获得;②实际应用中OCT眼病类别的不平衡,这可能会严重影响模型的性能。
论文成果:提出了两种不同的模型。一种是使用三个二进制卷积神经网络(CNN)分类器,另一种是使用四个二进制CNN分类器。采用VGG16、VGG19、ResNet50、ResNet152、DenseNet121、InceptionV3等几种cnn作为特征提取器开发二值分类器。
2.3 基于互补专家池和专家批处理归一化的半监督学习方法的OCT图像视网膜病变识别
论文目的:解决深度学习在医学领域自动检测视网膜病变时面临的两个主要挑战:①大量标记数据的需求②OCT图像疾病类别的不平衡问题
论文成果:基于互补专家池(Complementary Expert Pooling,简称CEP)和专家级批量归一化(Expert-wise Batch Normalization,简称EBN)解决深度学习在医学领域自动检测视网膜病变时面临的两个主要挑战。提出了一种基于VGG-16架构的定制分类模型,使用CEP来模拟不同专家之间的类别分布,并引入EBN来解决特征分布不匹配问题,从而提高模型在识别少数类别时的准确性。
网络结构:
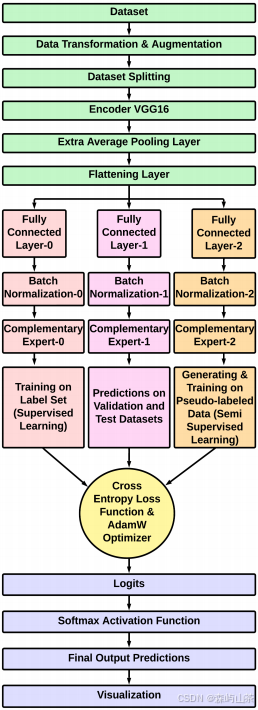
设计遵循三个完全连接的层,三个批处理规范化和三个互补专家。
首先进行了数据转换和扩充。我们将图像调整为244 × 244像素的固定大小,这是VGG16的标准输入大小。然后,我们以50%的概率进行随机的水平和垂直翻转,以使模型能够灵活地适应对象的左右方向。我们使用±15度的随机旋转来帮助模型在不同的方向上进行泛化。图像的亮度、对比度、饱和度和色调是随机改变的,以使模型对光照条件的变化更健壮。对图像的随机仿射变换也在水平和垂直方向上进行了高达10%的平移,使模型对图像对象的小位置移动更加稳健。规范化确保输入数据具有一致的规模和分布。它调整图像的像素值,使其适合特定的范围,因为像VGG16这样的模型需要图像具有特定的统计属性,如平均值、平均值和标准差。
在VGG16中加入了额外的平均池化层、平坦层、三个全连接层,然后是ReLU激活函数和dropout,以确保特征图大小的一致性,将可变输入大小转换为固定大小的输出,将2D特征图转换为一维向量,分别馈送到全连接层和正则化,从而有助于从提取的特征中学习复杂的模式。
2.4 基于多尺度区域卷积神经网络的前段OCT图像前房角分类
论文目的:通过判断前房角的开闭状态来辅助判别闭角青光眼类型。现有的大部分工作只能将前房角分为开角和闭角,但实际上闭角型青光眼可分为原发性开角型青光眼(开角)、原发性疑似闭角型青光眼(缩角)和原发性闭角型青光眼(闭角或结连)三种类型,目前已有方法较粗糙。
成果:首先利用前段光学相干断层成像(AS-OCT)观察截取出清晰的整个前房截面,再通过多尺度区域卷积神经网络(MSRCNN)架构判断前房角的状态为开放、狭窄或闭合,进而判断青光眼类型为原发性开角型青光眼(POAG)和原发性闭角型青光眼(PACG)(亚洲人失明主要原因)。
网络结构:
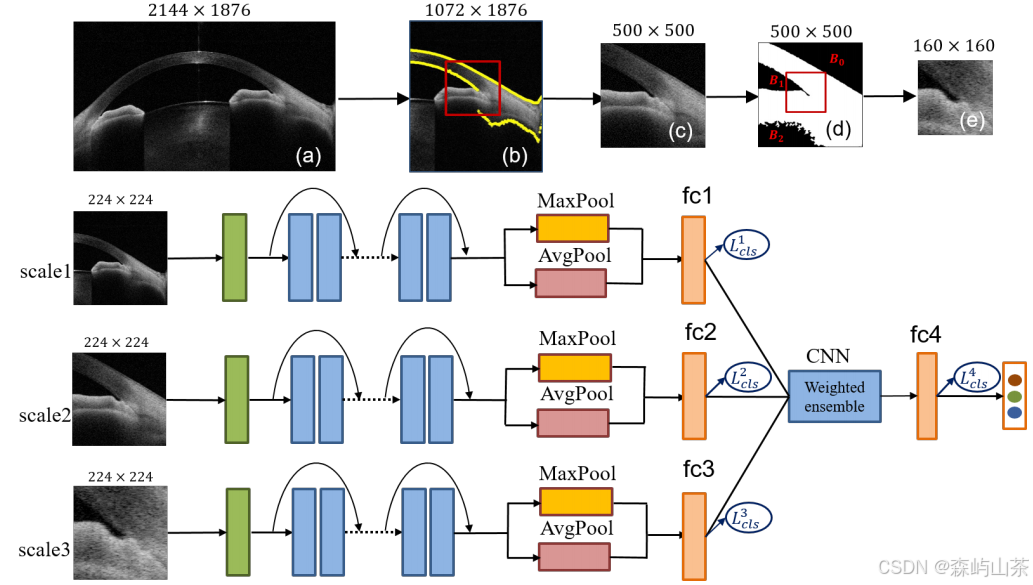
该网络结构会自动锁定前房角,该架构包含三个并行的卷积神经网络,用于提取特征表示。最后,将这些表示堆叠到全连接层进行青光眼类型的分类。
我们的MSRCNN架构包括三个并行流,以获得青光眼类型分类的联合表示。如图所示,每个流由一系列卷积单元组成,每个卷积单元包含用于卷积、批处理归一化和整流线性单元(ReLU)激活的层。在我们的方法中,我们使用Resnet-50作为主干
该分类框架的具体工作分为两个阶段:①基于AS-OCT图像的自动ACA区域定位;②基于多尺度区域卷积神经网络的分类。
(1)基于AS-OCT图像的自动ACA区域定位
①原始的AS-OCT图像 (图中a)首先被裁剪成左/右图像(图中b),为了方便,所有的左图像都被翻转,因为所有的ACAs都在同一个方向(记为Scale1);
②使用Ostu阈值方法将scale1图像阈值化为二值图像(黑色为0,白色为1),并执行形态学操作以去除孤立的对象。将得到的大连通区域的上下边界标记为粗ACA区域,该区域以500 × 500的边界框为中心进行局部化(记为Scale2);
③Otsu首先将Scale2图像转换为二值图像,然后对二值图像应用CCLS方法检测Schwalbes线,即角膜下边界,如图 (d)中的B1区域可以定义为ACA区域,因为Schwalbes线在该区域内。最后,通过以区域B1右坐标为中心的160 × 160的边界框定位Scale3图像。
(2)基于多尺度区域卷积神经网络的分类
①在临床上,ACA区是青光眼临床诊断的重要标志,因而将ACA量表(Scale1 - 3)被用作我们网络的输入。具有完整AS-OCT结构的全局图像可以为网络提供更多的全局信息,而局部图像Scale1、Scale2和Scale3保留了更高分辨率的局部细节,有利于学习精细表示;
②将三个不同大小的尺度区域调整为224 × 224,并用于学习不同的特征表示,这些特征表示是最后一个卷积层的输出。从并行网络模块得到的含有7×7的特征映射分别被送入全局最大池化和全局平均池化。我们将两个输出连接成完全连接的融合层,用于三种青光眼类型的分类;
③我们从每个流中得到一组不同的描述符,每个描述符的大小为3 × 1,是在分类网络的全连通层中生成的。为了得到最好的预测结果,将CNN叠加到三个描述符上,得到最终的预测结果;
④首先,我们将描述符连接起来,以获得新的描述符3 × 3。然后,我们对新的描述符进行32核1×3卷积运算,并将结果提供给全连接层进行最终分类。1 × 3的核可以对三个模型的预测进行加权,并输出到下一层。因此,特征集成的方法使模型自动学习不同基本模型预测的重要性。
2.5 基于三维无监督深度学习处理和数据的实相光学相干层析成像
论文目的:OCT的一个内在挑战在于OCT图像中存在斑点噪声,这明显影响了图像的质量,从而损害了随后的解释和诊断。
论文成果:提出了一种新的无斑点OCT成像策略,称为面向地面真相OCT (tGT-OCT),它利用无监督3D深度学习处理并利用OCT 3D成像特征来实现无斑点OCT成像。tGT-OCT有效地进一步降低了散斑噪声,并在保持空间分辨率的同时显示了原本会被散斑噪声遮挡的结构。tGT-OCT在去散斑方面的表现优于以往的技术,甚至达到了与散斑调制OCT(SM-OCT)(SM-OCT在光路中使用移动扩散器,并且必须进行重复的扫描,这大大降低了OCT系统的成像灵敏度和时间分辨率)相当的性能,后者被认为是OCT去散斑的理想方法。
网络结构(代码:GitHub - Voluntino/tGT-OCT: Tensorflow implementation of tGT-OCT):
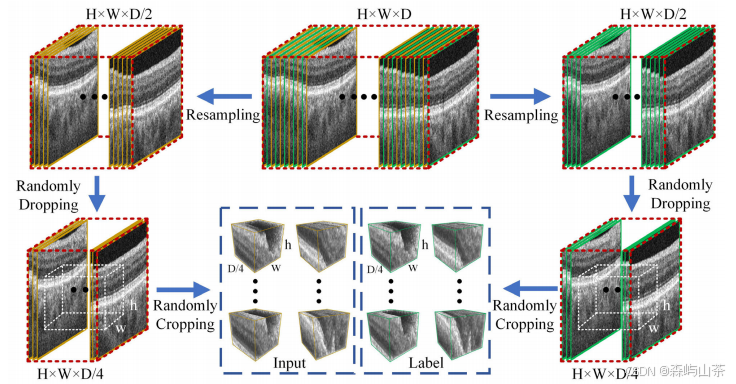
上图是配对数据的处理流水线,将原始体积数据相邻地重新采样到两个相似的体积数据中,然后通过随机丢弃和裁剪将其分割成成对的体积块。其中一个成对的数据是输入,另一个是训练的标签。
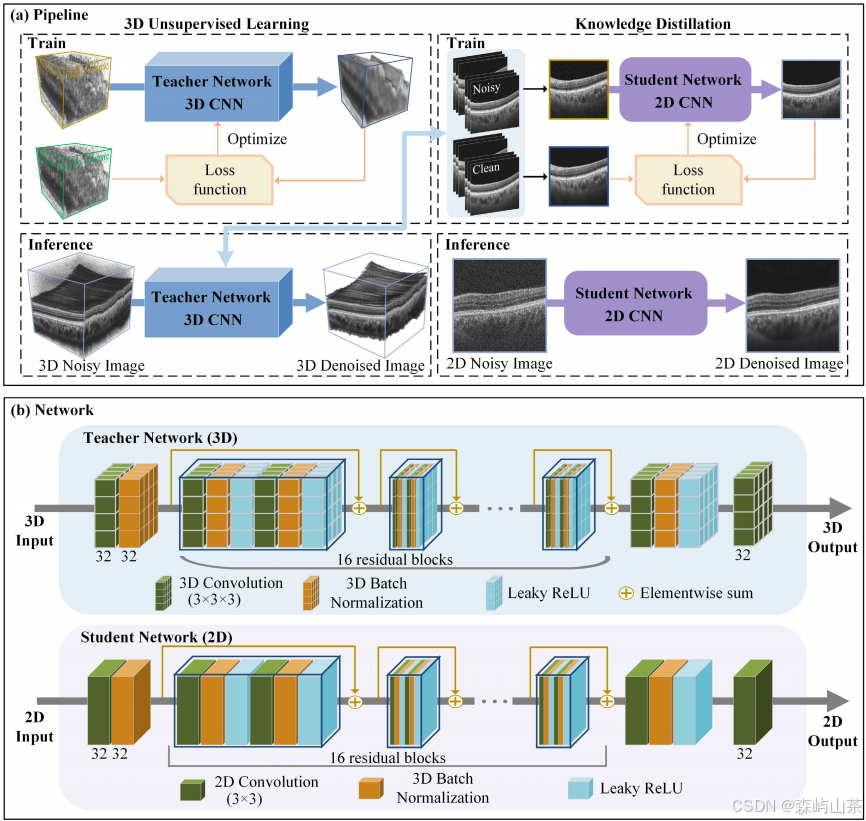
上图为tGT-OCT的管道和网络,(a)管道和(b)网络。提出的tGT-OCT包含一个带无监督学习的3D CNN和一个带知识蒸馏的2D CNN。使用带噪声的成对体数据训练3D CNN,从3D CNN生成的带噪声体和去噪体中选择用于训练2D CNN的去噪对。在推理和应用过程中,根据输入数据和计算资源的大小,分别使用3D CNN和2D CNN。
该综合策略包括3D CNN和2D CNN,以适应不同维度的OCT数据,即分别用于3D体积输入和单帧输入。
3D CNN使用无监督学习策略进行训练,该策略使用成对的相似噪声体积数据:其中一个被认为是输入,而另一个被认为是目标。由于需要大量的计算资源,并且现有的公共OCT数据集图像是二维的,我们引入了一种知识蒸馏机制,将3D CNN(作为教师网络)的知识提取到2D CNN(作为学生网络)中。在训练2D CNN时,从噪声体中选取有噪声的b扫描和从3D CNN生成的去噪体中选取相应的干净b扫描作为2D CNN的输入和标签。在推理过程中,分别使用教师网络和学生网络对单帧或3d体积进行去噪。
(1)无监督的3D CNN
本文提出的3D CNN是对深度残差网络(deep residual network, ResNet)的一种改进,深度残差网络通常用于图像超分辨率和去噪。
如图中(b)所示,ResNet由残差前层、16个残差块和残差后层组成。预残差层是一个三维卷积层,之后是一个批处理归一化层。3D卷积层有32个滤波器,每个滤波器的核大小为3 × 3 × 3。每个残差块具有两个与预残差层相同的3D卷积层,然后是批归一化层;网络使用泄漏的ReLU函数作为激活层。残差后层由3 × 3 × 3三维卷积层、批归一化层、漏ReLU函数和1 × 1 × 1三维卷积层组成。在每个剩余块中引入跳跃式连接,以连接该块的输入和输出。通过网络的特征图像的大小保持不变,在训练过程中保持64 × 64 × 64的大小。
(2)知识蒸馏
知识蒸馏机制,是将3D CNN的知识提取到2D CNN中。如图中(b)所示,将3D CNN表示为教师网络,将2D CNN表示为学生网络。从教师网络生成的带噪体积数据和去噪体积数据中分别选取1张带噪b扫描图和相应的去噪b扫描图,这些框架被用来用监督学习策略训练学生网络。为了在知识蒸馏过程中保留尽可能多的特征图,将学生网络的结构与教师网络对齐,将教师网络中的三维卷积层改为二维卷积层,除最后一层为1 × 1外,所有卷积层的大小均为3 × 3。
三、思考和总结
经过几篇文献的阅读,个人感觉目前OCT大多与深度学习相关技术结合,用于眼部疾病的分类问题。
目前OCT+深度学习任务大多面临两个共性问题:①难以获取满足条件的数据,主要体现在数据格式不统一和数据量需求难以满足(眼部疾病的分类问题大多需要较大数量且清晰的数据)两个方面。②识别难度大。眼部疾病的差距往往是很细微的,且类型较多,这使分类任务的进行存在很大难度,因而需要更加精细、效率更高的神经网络结构。
因此,大部分的OCT相关任务主要目标为:①降低数据依赖性②提出更好的网络结构实现更高效的分类or获取更高质量的图像和模型。
四、参考文献
[1] A. M. Nakib, Y. Li and Y. Luo, "Retinopathy Identification in OCT Images with A Semi-supervised Learning Approach via Complementary Expert Pooling and Expert-wise Batch Normalization," 2024 9th Optoelectronics Global Conference (OGC), Shenzhen, China, 2024, pp. 170-174, doi: 10.1109/OGC62429.2024.10738779.
[2]Depeng Wang, Liejun Wang, "On OCT Image Classification via Deep Learning", Volume 11, Number 5, October 2019. IEEE Photonics Journa, DOI: 10.1109/JPHOT.2019.2934484.
[3] Jongwoo Kim, Loc Tran, "Retinal Disease Classification from OCT Images
Using Deep Learning Algorithms", 2021 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB) | 978-1-6654-0112-8/21/$31.00 USG | DOI: 10.1109/CIBCB49929.2021.9562919.
[4] H. Hao et al., "Anterior Chamber Angles Classification in Anterior Segment OCT Images via Multi-Scale Regions Convolutional Neural Networks," 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 2019, pp. 849-852, doi: 10.1109/EMBC.2019.8857615.
[5] G. Ni et al., "Toward Ground-Truth Optical Coherence Tomography via Three-Dimensional Unsupervised Deep Learning Processing and Data," in IEEE Transactions on Medical Imaging, vol. 43, no. 6, pp. 2395-2407, June 2024, doi: 10.1109/TMI.2024.3363416.

















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









