




题目:A Survey on Efficient Inference for Large Language Models
链接:https://arxiv.org/abs/2404.14294
论文首先介绍了模型制约LLM推理速度的三个要素:
-
模型大小:主流大型语言模型通常包含数十亿甚至数万亿个参数。例如,LLaMA-70B模型包含700亿个参数,而GPT-3模型则扩展到1750亿个参数。这种相当大的模型尺寸显著增加了在大型语言模型推理过程中的计算成本、内存访问成本和内存使用量。
-
注意力操作:在预填充阶段,自注意力操作在输入长度上表现出二次方的计算复杂度。因此,随着输入长度的增加,注意力操作的计算成本、内存访问成本和内存使用量迅速增加。
-
解码方法:自回归解码方法一次生成一个token。在每个解码步骤中,所有模型权重都会从片外高带宽内存(HBM)加载到GPU芯片上,导致巨大的内存访问成本。此外,随着输入长度的增长,KV Cache的大小也会增加,可能会导致内存碎片化和不规则的内存访问模式。
感觉上面的分类不是很底层,比如说第一点,模型大小是由隐藏层维度、Transformer层的数量等方面决定的,它们也决定了访存的快慢,这和第三点讲到的东西有些重合了。
对推理加速方法的分类:
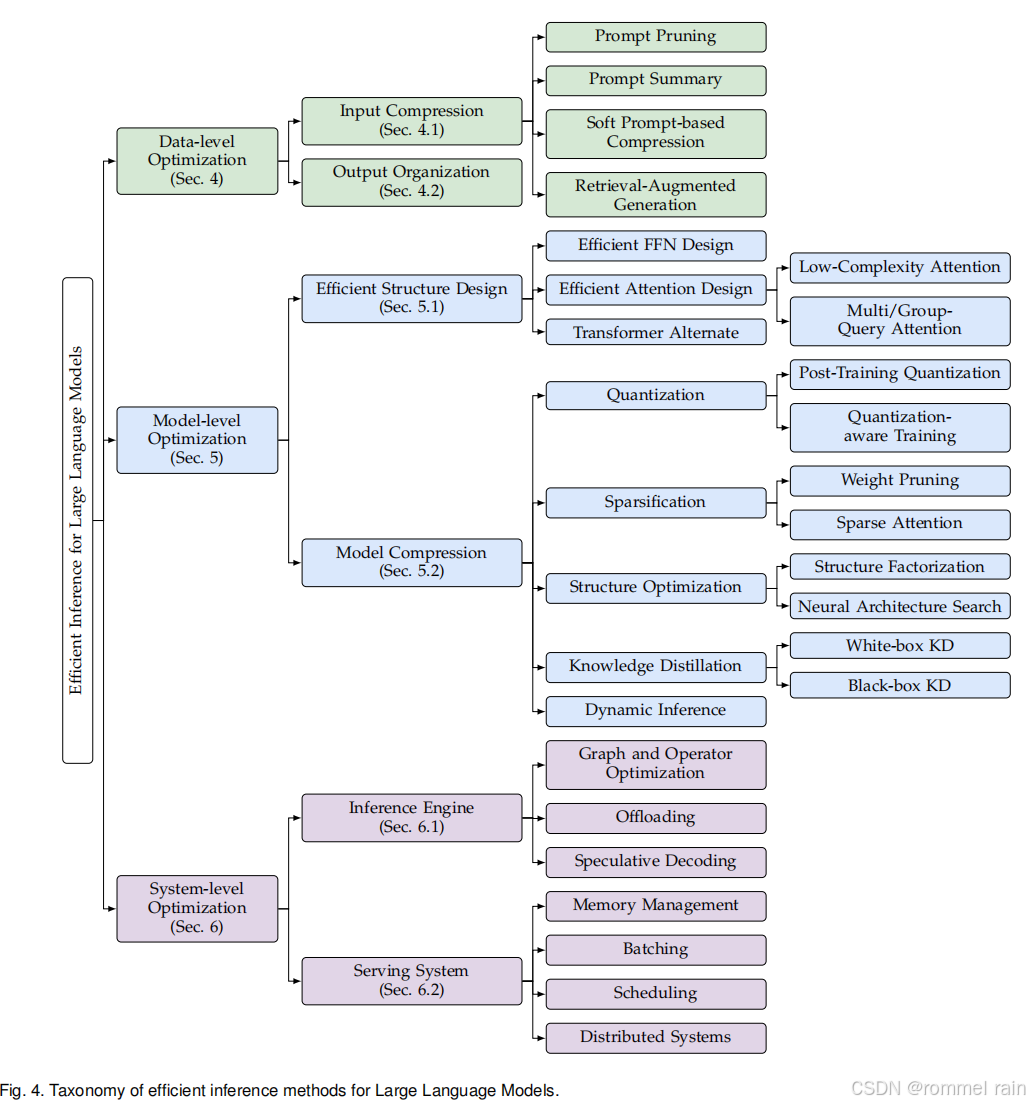
这篇综述对加速的大类划分和上一篇很像,但是在大类下面子类的划分就不太一样了。它同样是将大类划分成了数据级、模型级和系统级。
数据级的推理加速主要是输入压缩和输出组织。输入压缩就是减少prompt的量,从而缩短prefill的时间,有prompt剪枝、prompt摘要等方法;输出组织就是重新组织输出的方式,比如说先让LLM生成问题的关键点,然后再结合各个关键点来进行并行的回复。例如SOT方法在此基础上对关键点进行扩展时共享公共前缀。
感觉数据级的推理加速不太像正儿八经的推理加速,因为它没有改动推理的实际运行过程,只是改了整个系统的输入输出。后面的输出组织可能还有机会和改模型、改硬件逻辑有一些沾边。
模型级优化,本篇论文根据是否需要预训练来划分类别,也就是一类是从训练到推理的优化(设计新的Transformer结构),另一类是只优化推理(模型压缩)。
高效结构
也就是改进模型结构,包括改进FFN、改进self-attention和改用别的架构。整体架构:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









