



题目:Efficient Large Language Models: A Survey
链接:https://arxiv.org/pdf/2312.03863
github地址:GitHub - AIoT-MLSys-Lab/Efficient-LLMs-Survey: [TMLR 2024] Efficient Large Language Models: A Survey
这篇论文将高效LLM方式分成三大类:model-centric、data-centric和frameworks,本文主要摘录和总结论文中和LLM推理加速相关的内容。
model-centric
第一部分,模型压缩,主要包括量化、参数剪枝、低秩近似和知识蒸馏,这部分先略过
第二部分,高效预训练,主要包括混合精度加速、缩放模型、初始化技术、训练优化器和系统级的训练前的效率优化,由于目前重点在于推理阶段,所以这块也先略过
第三部分,高效微调,包括参数高效微调和内存高效微调,略
第四部分,高效推理,这是需要重点关注的部分,包括算法级别和系统级别的技术。下图展示了高效推理技术分类
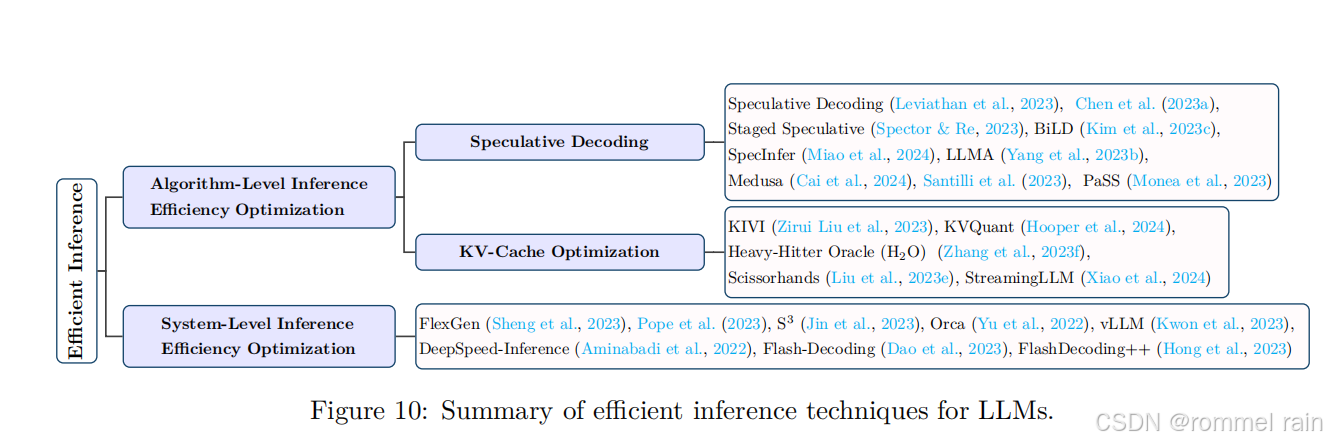
高效推理-投机解码
推测性解码 是一种自回归语言模型的解码策略,通过并行计算使用较小的草稿模型来生成token,从而加速采样过程,为大型目标模型创建推测性前缀。
Chen等人(2023a)专注于LLMs的分布式服务设置,并提出运行一个更快的自回归模型K次,然后用大型目标模型评估初步输出。采用了一种定制的拒绝采样策略,以从左到右的顺序批准草稿token的选择,从而在过程中重新捕获大型目标模型的分布。
Staged Speculative(Spector&Re,2023)将推测批转换为表示潜在令牌序列的树结构。这种重组加快了更大、更好的投机批次的产生。它还为初始模型的推测解码引入了一个额外的阶段,从而提高了整体性能,比标准推测解码高出1.36倍。
BiLD(Kim等人,2023c)通过两项创新技术优化了推测性解码:当较小的草稿模型缺乏足够信心时,允许它将控制权让给较大的目标模型的回退策略;以及使目标模型能够重新审视并纠正草稿模型所做出的任何不准确预测的回滚策略。
SpecInfer(苗等人,2024年)扩展了推测性解码,并通过采用推测性推理技术和标记树验证来加速推理。其核心思想是合并一系列经过微调的小型推测模型,这些模型共同协作预测大型目标模型的输出,然后用这些输出来验证所有预测。
与需要引入一个额外的高效草稿模型来生成检查用草稿的推测解码不同,LLMA(杨等人,2023b)选择一个与之密切相关的参考文献中的文本段落,并将其标记复制到解码器中。然后,它在单个解码步骤中同时评估这些标记作为解码输出的适用性。这种方法使得速度提高了两倍以上,同时保持了与传统贪婪解码相同的生成结果。
Medusa(Cai等人,2024年)提出了一种方法,它不是使用一个单独的草稿模型来顺序生成候选输出,而是冻结LLM的主干,微调额外的头部,并使用基于树的注意力机制并行处理预测以加快解码过程。
Santilli等人(2023年)提出了包括Jacobi and Gauss-Seidel固定点迭代方法在内的并行解码方法,用于推测性解码。在这些方法中,雅可比解码被扩展为Lookahead解码(Fu等人,2023c),以进一步提高效率。
高效推理-KV-Cache 优化
在推理过程中,大型语言模型(LLMs)需要将过去标记的键值(KV)对存储到缓存中,以便未来生成token。随着生成token长度的增加,所需的KV缓存大小会大幅增加,导致显著的内存消耗和较长的推理延迟。因此,减少KV缓存的大小是提高推理效率的关键。现有的KV缓存优化技术大致可以分为两类。
第一类是压缩KV cache:例如KIVI,这是一种无需调整的2位KV缓存量化算法,它按通道对键缓存进行量化,按标记对值缓存进行量化,在推理过程中实现了2.6倍的峰值内存使用量减少。 Hooper进行一项实证研究,研究逐通道量化以及其他类型的量化(如在旋转位置嵌入之前的量化)的影响。基于他们的发现,他们提出了KVQuant,这是一种结合了这些量化方法的技术,用于将LLaMA的KV缓存量化到3位。以上都是量化方法。
第二类是将一些键值对从缓存中删除出去。例如,张等人(2023f)提出了Heavy-Hitter Oracle(H2O),这是一种KV缓存驱逐策略,将KV缓存驱逐问题建模为一个动态子模问题,并动态保持最近和性能关键的标记之间的平衡,从而提高了大型语言模型推理的吞吐量。同样,刘等人(2023e)提出了一个假设,即the persistence of importance,认为只有在早期阶段至关重要的标记才会对后续阶段产生显著影响。基于这个假设,他们设计了Scissorhands,显著减少了KV缓存的大小,同时不损害模型质量。最后,StreamingLLM(肖等人,2024)在其算法设计中融入了窗口注意力,其中只有最新的KV被缓存到一个固定大小的滑动窗口中。通过驱逐过时的KV,StreamingLLM确保了缓存首次填满后内存使用量和解码速度保持恒定。
高效推理-系统级推理优化
LLM推理的效率也可以在特定硬件架构下在系统级别进行优化。
例如,FlexGen(Sheng等人,2023年)是一个高吞吐量的推理引擎,它使得在内存有限的GPU上执行LLM成为可能。它采用基于线性规划的搜索方法来协调各种硬件,结合了GPU、CPU和磁盘的内存和计算资源。此外,FlexGen将权重和注意力缓存量化为4位,这提高了在单个16GB GPU上OPT-175B的推理速度。
Pope等人(2023年)开发了一种简单的分析框架,用于根据应用程序需求划分模型,以扩展Transformer推理。通过将此框架与调度和内存优化相结合,他们能够在PaLM(Chowdhery等人,2022年)上实现比FasterTransformer(NVIDIA,2023a)更好的效率。
Orca(Yu等人,2022年)采用迭代级调度来服务具有可变输出序列长度的批量序列。当批量中的一个序列完成时,它会被返回给用户,以便可以立即服务一个新的序列。因此,与静态批处理相比,Orca提高了GPU利用率,在相同的延迟水平下,与FasterTransformer相比,吞吐量提高了36.9倍。(可以发现,在系统级别实现推理优化,主要的baseline是Faster Transformer)
S3(Jin等人, 2023) 创建了一个系统,该系统预先知道输出序列。它可以预测序列的长度,并相应地安排生成请求,优化设备资源的使用并提高生产率,显示出比使用相同数量的GPU的Orca更高的吞吐量。然而,由于对每个请求的内存分配不准确,Orca和S3都会导致内存碎片化。
vLLM(Kwon等人,2023年)使用PagedAttention解决了的内存效率问题,它使得连续的键和值可以在非连续的内存空间中存储。具体来说,PagedAttention将每个序列的KV缓存划分为多个块,每个块包含固定数量的令牌的键和值。在注意力计算过程中,PagedAttention内核通过维护一个块表来高效管理这些块,以减少内存碎片。具体来说,序列的连续逻辑块通过该表映射到非连续的物理块,并且每当生成新的令牌时,表会自动分配一个新的物理块。这减少了生成新令牌时浪费的内存量,从而提高了效率。研究表明,PagedAttention在与FasterTransformer(NVIDIA,2023a)和Orca(Yu等人,2022)相同的延迟水平下,将流行大型语言模型(LLMs)的吞吐量提高了2-4倍。
DeepSpeed-Inference(Aminabadi等人,2022)是一种多GPU推理方法,旨在提高密集型和稀疏型Transformer模型的效率,当这些模型被包含在集体GPU内存中时。此外,它提供了一种混合推理技术,该技术利用CPU和NVMe内存,以及GPU内存和计算,即使对于那些太大而无法适应组合GPU内存的模型,也能实现高吞吐量推理。这种方法在相同的吞吐量下展示了比FasterTransformer更低的延迟。
Flash-Decoding(Dao等人,2023年)通过将键/值分解为更小的部分,在这些部分上并行计算注意力,然后将它们组合以生成最终输出,从而提高了长上下文推理的速度。它在长序列解码速度方面的性能优于FasterTransformer和FlashAttention。
FlashDecoding++ (Hong et al., 2023) 通过异步softmax、用于平面GEMM优化的双缓冲以及启发式数据流支持主流语言模型和硬件后端,与HuggingFace实现相比,在Nvidia和AMD GPU上分别实现了高达4.86倍和2.18倍的加速,显示出在相同吞吐量下比Flash-Decoding更高的加速比。
系统级的推理优化要求最高,需要再硬件层面下很多功夫。
第五部分,高效架构设计:
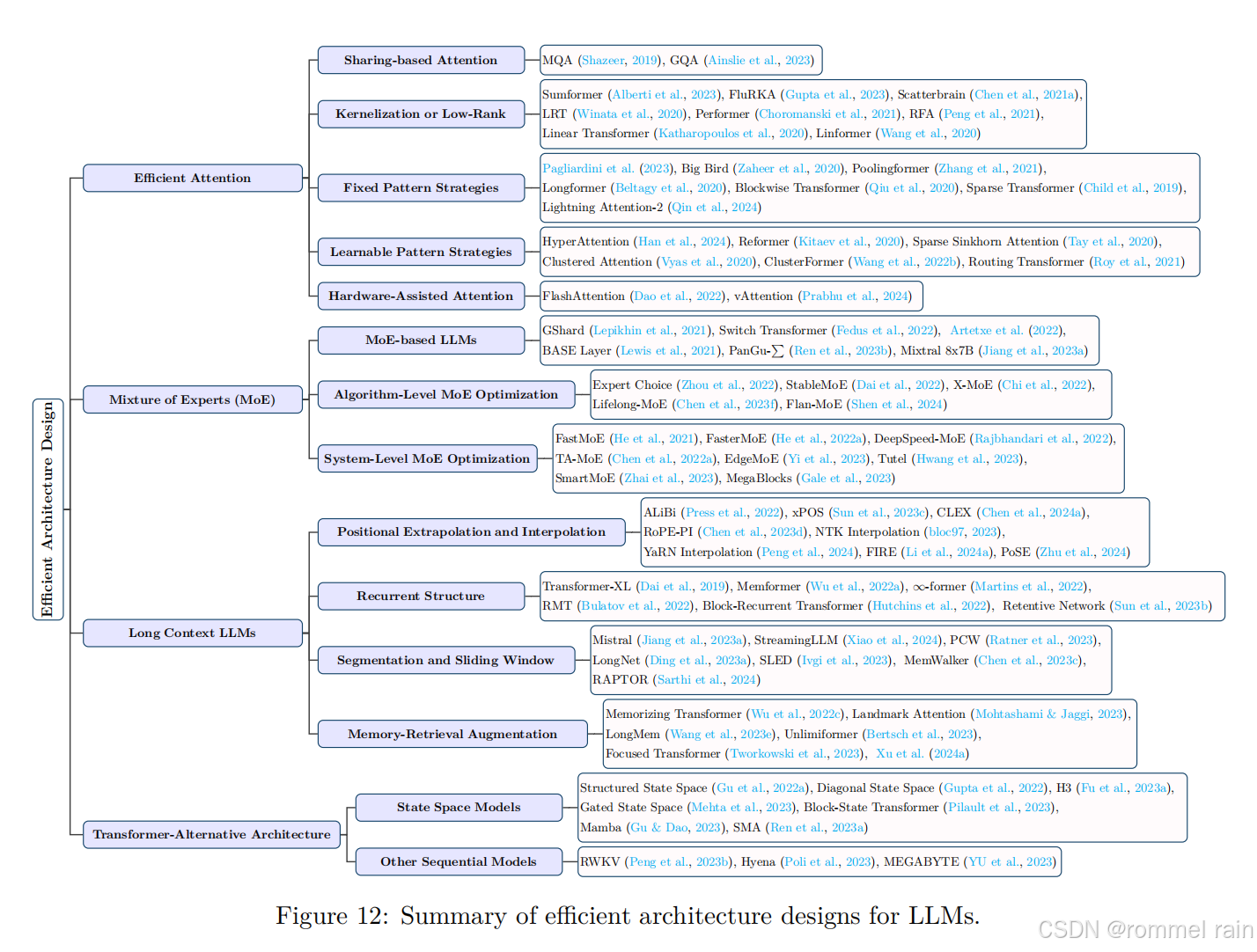
高效架构-attention
注意力模块的二次时间和空间复杂度显著减慢了大型语言模型(LLMs)的预训练、推理和微调过程。为了使注意力更轻量级以提高执行效率,已经提出了许多技术。这些技术大致可以归类为基于共享的注意力、核化或低秩、固定模式策略、可学习模式策略以及硬件辅助的注意力。我们忽略核化或低秩吧。
基于共享的注意力Sharing-based Attention,主要方法就是MQA和GQA,这部分比较熟悉,不介绍了。
固定模式策略就是稀疏attention,通过固定的模式,只计算部分token之间的注意力。
可学习模式策略,通过学习token相关性并将token分组到桶或集群中。
硬件辅助注意力。专注于开发硬件特定的技术以提高注意力效率。例如,FlashAttention(Dao等人,2022年)在计算LLMs中的注意力模块时,减少了GPUHBM与片上SRAM之间的内存访问次数。与标准注意力机制中多次在HBM和SRAM之间传输值和结果不同,FlashAttention将所有注意力操作合并到一个内核中,并将权重矩阵划分为更小的块,以更好地适应小型SRAM。因此,每个注意力块只需要一次通信处理,这显著提高了处理整个注意力块的效率。vAttention(Prabhu等人,2024年)提出了一种在连续的虚拟内存中存储KV缓存的方法,而无需预先分配物理内存。它利用CUDA对低级虚拟内存API的支持,避免了存储KV缓存的软件复杂性。
这一部分的baseline通常是flashattention。
高效架构-Moe
专家混合模型(MoE)代表了一种在LLMs中广泛使用的大规模稀疏方法。它的运作原理是将指定的任务分割成若干个子任务,然后开发出许多较小的、专门化的模型,这些模型被称为专家,每个专家专注于一个特定的子任务。随后,这些专家协作以提供一个综合的输出。对于预训练或微调,MoE要求开发者高效地管理大量的参数,从而增强模型的容量和可能的性能,同时保持计算和内存需求相对可控。对于推理,MoE通过不同时激活所有专家而是只激活少数几个来减少推理时间。此外,MoE能够在模型分布式场景中通过将每个专家分配给一个单独的加速器来最小化设备间的通信;通信仅在承载路由器和相关专家模型的加速器之间是必要的。
Moe下面又分成一些类别,比如算法级的Moe优化和系统级的Moe优化,感觉如果深入研究Moe又需要很大的工作量。
高效架构-长上下文LLM
在许多应用中,例如多轮对话和会议摘要,现有的LLMs通常需要理解和生成比它们预训练时更长的上下文序列,这可能导致由于对长上下文记忆不佳而准确度下降。解决这个问题的一个直接方法是用类似的长序列数据微调LLMs,然而,这既耗时又计算密集。为了填补这一空白,已经开发出新的方法,使LLMs能够以更高效的方式适应更长的上下文长度。这些方法大致可以分为四类:位置外推和内插、循环结构、分段和滑动窗口以及记忆检索增强。
这部分内容在前面的调研中没有见过,不知道是不是因为比较小众。
高效架构还有一个根本性的解决方式就是不用Transformer,有很多新架构,但是暂时都无法撼动Transformer的地位。
data-centric主要包括数据选择和提示工程两方面,由于它们的应用主要体现在预训练和微调,也就不在此处展开
LLM Frameworks
LLM框架通常可以根据它们是否支持训练、微调和推理任务来分组。具体来说,支持训练微调的框架旨在提供可扩展、高效和灵活的基础设施,以提高计算效率,减少内存占用,优化通信效率,并确保训练/微调过程的可靠性。支持推理的框架则专注于优化推理吞吐量,并减少内存占用和延迟。这些框架提供了多种部署功能以满足LLM请求。
论文的这部分介绍了很多框架,这里只摘录其中比较重要的DeepSpeed和vLLM
DeepSpeed:
由微软开发,DeepSpeed(Rasley等人,2020年)是一个集成了训练和部署大型语言模型(LLMs)的框架。它已被用于训练像Megatron-Turing NLG 530B(与Nvidia Megatron框架合作)和BLOOM这样的大型模型。在这个框架内,DeepSpeed-Inference是基础库。DeepSpeed-Inference的一个关键特性是ZeRO-Inference,这是一种优化技术,旨在解决大型模型推理时的GPU内存限制问题。ZeRO-Inference将模型状态分布在多个GPU和CPU之间,提供了一种管理GPU内存限制的方法。
DeepSpeed-Inference的另一个重要特性是其深度融合机制,该机制允许在不必要进行全局同步的情况下,通过在迭代空间维度上对计算进行分块,实现操作的融合
vLLM:
vLLM 是一个开源库,用于LLM的推理和提供服务。它采用了一种不同的设计,关于如何在内存中存储键值(KV)缓存。这一设计的核心是PagedAttention机制,它将一组固定数量的标记的注意力键和值(KV)缓存进行分段。与连续空间存储不同,PagedAttention的KV缓存块是灵活存储的,类似于操作系统中的虚拟内存管理。这促进了在不同序列之间共享内存块,这些序列可能与同一请求甚至不同请求相关联,从而提高了处理注意力机制时的内存管理效率。
因此,vLLM可以在使用复杂解码技术(如并行采样和束搜索)时减少总内存使用,因为不同候选样本之间可以共享内存块。它还允许按需分配缓冲区,同时消除了外部碎片,因为块的大小是统一的。此外,vLLM还集成了保护措施,通过交换和重新计算需要时驱逐和恢复块来防止由于KV缓存大小增加而导致的GPU内存溢出。vLLM还支持Multi-LoRA (Wang等人, 2023g)、连续批处理(Yu等人, 2022)和量化(GPTQ (Frantar等人, 2023)、AWQ (Lin等人, 2023)和SqueezeLLM (Kim等人, 2024))。最后,它为Nvidia和AMD的GPU实现了高效的内核。


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









