







 本文介绍了Scrapy,一个Python爬虫框架,用于爬取和提取网络数据。文章详细阐述了Scrapy的工作流程,包括请求、响应处理、中间件和爬虫的交互。还提供了Scrapy的安装方法,以及如何创建和运行一个简单的爬虫项目,如爬取百度。通过数据提取和使用Pipeline进行数据保存,展示了Scrapy的基本用法。
本文介绍了Scrapy,一个Python爬虫框架,用于爬取和提取网络数据。文章详细阐述了Scrapy的工作流程,包括请求、响应处理、中间件和爬虫的交互。还提供了Scrapy的安装方法,以及如何创建和运行一个简单的爬虫项目,如爬取百度。通过数据提取和使用Pipeline进行数据保存,展示了Scrapy的基本用法。
days7 scrapy的使用
概念
Scrapy http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html 是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
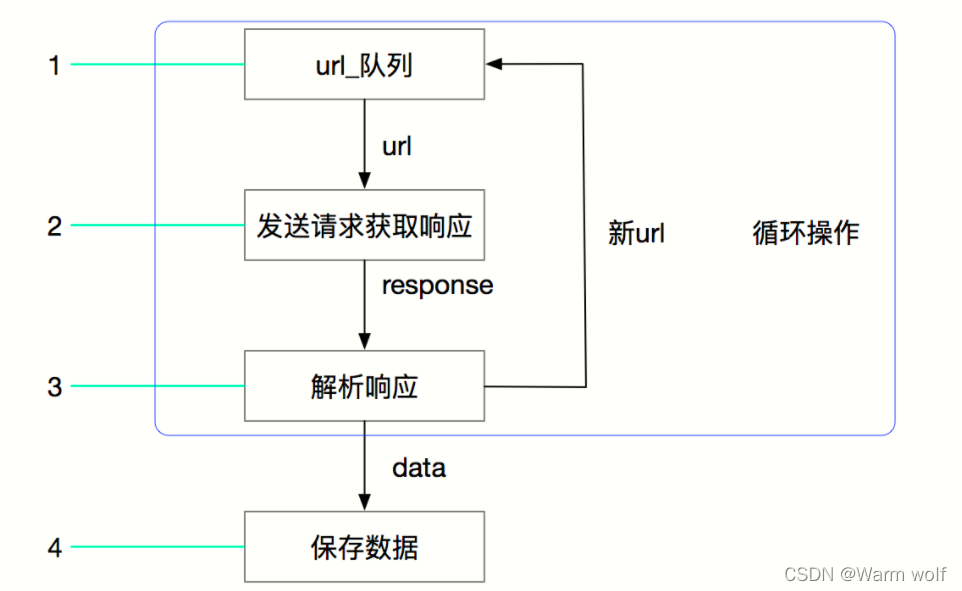
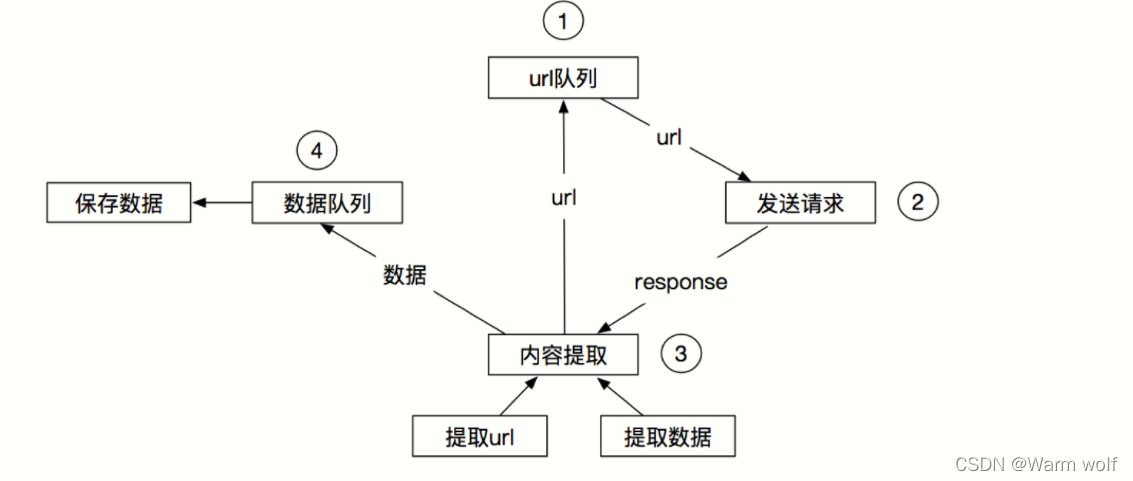
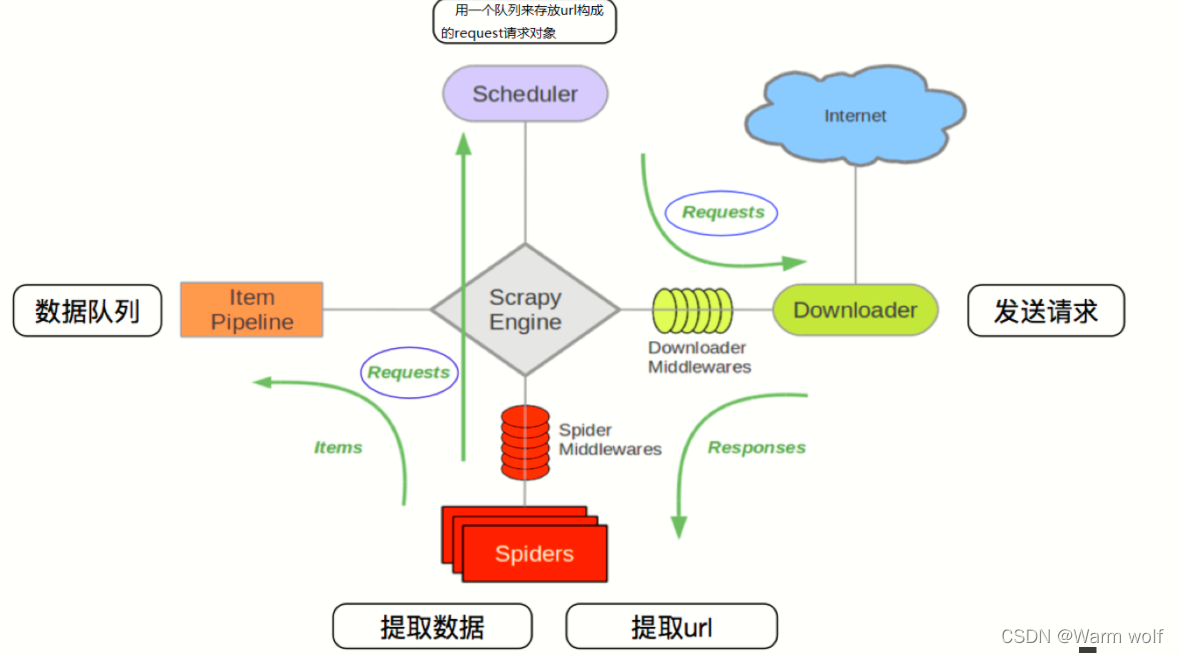 其流程可以描述如下:
其流程可以描述如下:
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据

入门
安装
pip/pip3 install scrapy (window)
sudo apt-get install scrapy(linux)
项目创建
爬取百度
scrapy crawl baidu
- 创建项目:
scrapy startproject test - 生成一个爬虫:
scrapy genspider baidu www.baidu.com - 提取数据:
根据网站结构在spider中实现数据采集相关内容 - 保存数据:
使用pipeline进行数据后续处理和保存
—2022.04.20


















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











