







熬夜整理两万字Python知识点
导学
注意环境变量查找顺序:
先是从当前路径下查找,然后再到系统变量中查找。如果都没有找到,最后报错。
注意环境变量的设置技巧:
先是创建一个独立的变量值,再将其加入到系统path变量,这样比较工整。见下图。
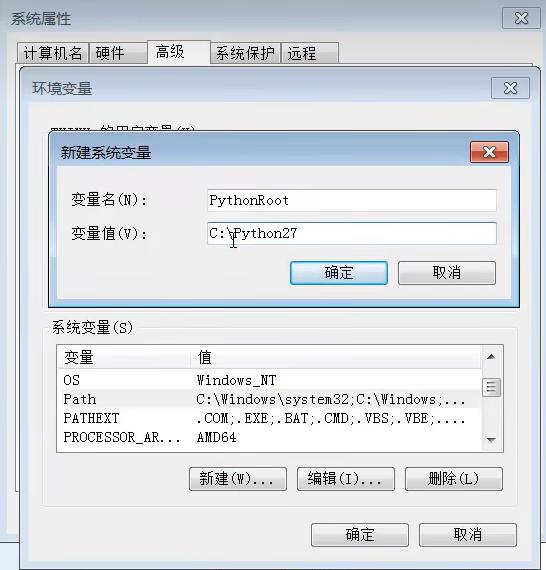
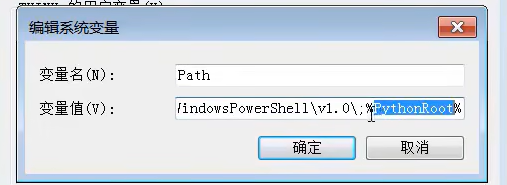
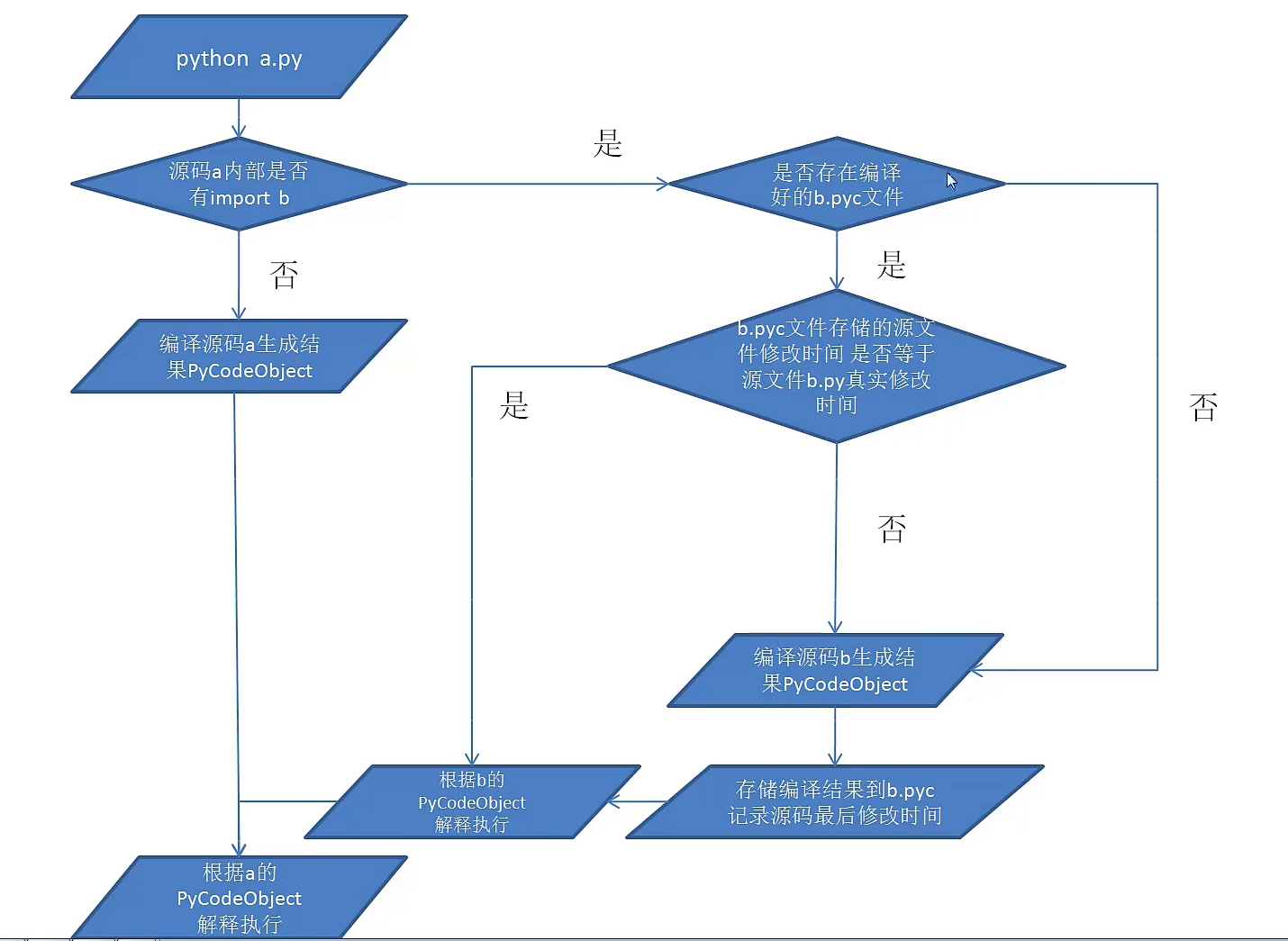
Python运行流程:
Python先是编译一个中间的字节码(在内存中,关于持久化,一般是import引用的那个是持久化,因为),然后解释器再解释执行;
并不是单纯的编译型或解释型。

0.1 PyCharm快捷键
- ctrl + r 替换操作
- ctrl + d 向下复制一行
- alt + enter 补全
- ctrl + alt + l 格式整理
第一章 变量和简单数据类型
数据类型种类:
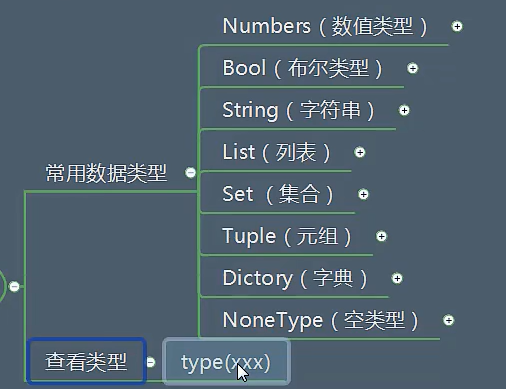
数据类型之间转换方式:
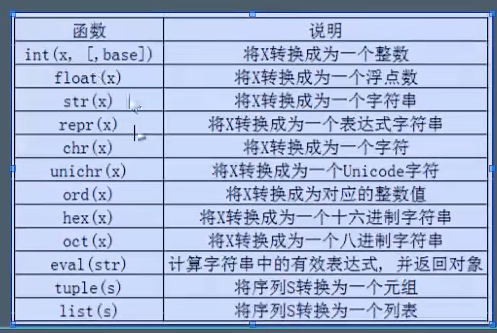
面试知识点:
- 动态类型/静态类型(Python是动态类型)
# 判断标志是以下过程是否是可以发生的
score = 123
score = "123"

- 强类型/弱类型(Python是强类型)
# 判断标志是一下可否发生转换,比如:转换、拼接等
"a" + 1

1.1 变量
变量的命名:
- 在使用标识符时,需要注意如下规则:
- 标识符可以由字母、数字、下画线(_)组成,其中数字不能打头。
- 标识符不能是 Python 关键字,但可以包含关键字。
- 标识符不能包含空格。
# 变量定义与使用
message = "hello python world"
a, b = 1, 2
print(message)
1.2 字符串
注意:
字符串的引号可以是单引号也可以是双引号
# 字符串
message = "this is a String"
message1 = 'this is a String'
1.2.1 使用方法修改字符串大小
-
title():以大写形式显示每个单词# 使用方法修改字符串大小 name = "ada lovelace" print(name.title())输出结果:
Ada Lovelace -
upper()和lower():分别是将字符串改为大写和全部小写name = "ada lovelace" print(name.upper()) # ADA LOVELACE print(name.lower()) # ada lovelace -
在字符串中使用变量
# 在字符串中使用变量 frist_name = "ada" last_name = "lovelace" full_name = f"{frist_name}{last_name}" # f:format的缩写,{}:里放变量 print(full_name)# adalovelace print("fullname{0}{1}".format(name, age)) # 也可以 -
删除空白(
rstrip():末尾空白,lstrip(): 去除开头空白,strip(): 去除两边空白){注意strip()的功能是暂时的}# 删除空白 favorite_language = 'python ' name = 'liuyu' print(favorite_language.rstrip())// 删除末尾的空格 print(f'{favorite_language}{name}') favorite_language = favorite_language.rstrip() print(f'{favorite_language}{name}') ''' 结果为: python(此处无空格) python liuyu pythonliuyu ''' ''' 我们还可以看见: rstrip()的删除作用只是暂时的,如果要永久需要将新值关联到旧值上 '''
1.3 数
注意:结果包含小数位数可能是不确定的
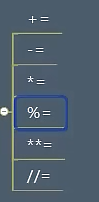
//= 是整除
**= 是 a **= b”这个操作符表示“a = a ** b”,即对变量a进行指数运算,并将运算结果赋值给a
>>> 0.2 + 0.1
0.300000000000004
>>>3 * 0.1
0.300000000000004
注意:书写数较大的数时可以使用下划线将数字分组
>>> universe_age = 14_000_000_000
>>> print(universe_age)
14000000000
1.4 注释
# 单行注释
'''多行注释'''
"""多行注释"""
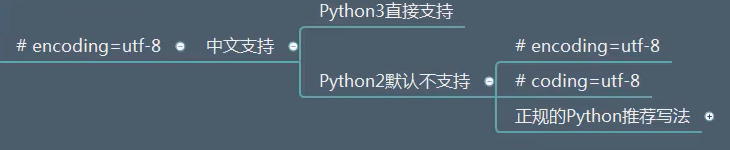
运行模式问题(主要是Linux下,一般使用后面的这种,如果是Windows系统会把它当成注释,从而失去效果):

中文问题:
1.5 比较运算符
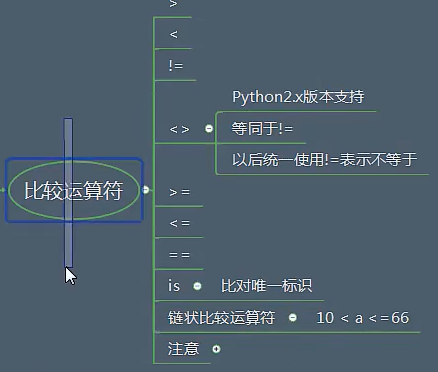
举例:
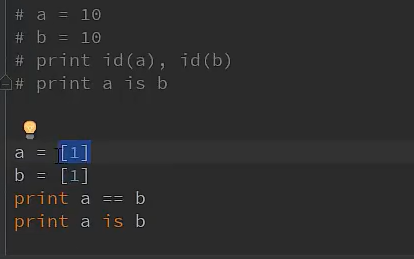
第一个是true, 第二个是false(注意)
链式比较:
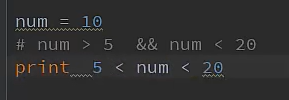
1.6 逻辑运算符
非0即真,非空即真:

逻辑表达式结果不一定只是true和false:(主要是短路运算符)

第二章 列表
2.1 列表概念
列表是由一系列按特定顺序排序的元素组成。
# 列表
price = 1200
bicycle = ["bike", 'redMi', price, 141241]
print(bicycle)# ['bike', 'redMi', 1200, 141241]
2.2 列表的相关操作
2.2.1 修改元素
# 修改元组元素
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)
motorcycle[0] = 'nuct'# ['honda', 'han', 'dao']
print(motorcycle)# ['nuct', 'han', 'dao']
2.2.2 添加元素
- 末尾添加元素
# 末尾添加元素
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)# ['honda', 'han', 'dao']
motorcycle.append('nuct')
print(motorcycle)# ['honda', 'han', 'dao', 'nuct']
- 列表中添加元素
# 列表中添加元素
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)# ['honda', 'han', 'dao']
motorcycle.insert(0, 'nuct')
print(motorcycle)# ['nuct', 'honda', 'han', 'dao']
2.2.3 从列表中删除数据
方法1:使用del语句删除元素
# 列表中删除数据——del
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)# ['honda', 'han', 'dao']
del motorcycle[0]
print(motorcycle)# [ 'han', 'dao']
方法2: 使用pop()函数删除元素
# 列表中删除数据——pop()
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)# ['honda', 'han', 'dao']
poped_motorcycle = motorcycle.pop()
print(motorcycle)# [ 'han', 'dao']
print(poped_motorcycle)# 'dao'
方法3:弹出列表中任意位置元素:
# 弹出列表中任意位置元素
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)# ['honda', 'han', 'dao']
first_owned = motorcycle.pop(1)
print(first_owned) # han
方法4: 根据值删除元素
# 根据值删除元素
motorcycle = ['honda', 'han', 'dao']
print(motorcycle)# ['honda', 'han', 'dao']
motorcycle.remove('honda')
print(motorcycle) # ['han', 'dao']
2.3 组织列表
2.3.1 使用sort()方法列表实现永久排序
# 使用sort()方法列表实现永久排序
cars = ['bem', 'ak', 'awp']
cars.sort()
print(cars)# ['ak', 'awp', 'bem']
2.3.2 使用sorted()对列表实现暂时的排序
# 使用sorted()对列表实现暂时的排序
cars = ['bem', 'ak', 'awp']
print(cars)# ['bem', 'ak', 'awp']
print(sorted(cars))# ['ak', 'awp', 'bem']
print(cars)# ['bem', 'ak', 'awp']
2.3.3 列表反转
# 列表反转
cars = ['bem', 'ak', 'awp']
reverse(cars)
print(cars)# ['awp', 'ak', 'bem']
2.3.4 列表长度
cars = ['bem', 'ak', 'awp']
print(len(cars))# 3
2.4 操作列表
2.4.1 遍历列表
实例代码:
magicians = ['alice', 'david', 'carolina']
for magician in magicians:
print(f"{magician.title()}, that was a trick!")
# Alice, that was a trick!
# David, that was a trick!
# Carolina, that was a trick!
2.4.2 创建数值列表
2.4.2.1 使用range()函数
## 创建数值列表
for value in range(1, 5):
print(value)
# 1
# 2
# 3
# 4
2.4.2.2 使用list() 函数
list()函数将range()的结果直接转换为列表。
## list()
numbers = list(range(2, 11, 2))
print(numbers)# [2, 4, 6, 8, 10]
squares = []
for value in range(1, 11):
square = value**2
squares.append(square)
print(squares)# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
2.4.2.3 对数字列表执行简单的统计计算max、 min和sum
digit = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
min(digit)
Out[4]: 0
max(digit)
Out[5]: 9
sum(digit)
Out[6]: 45
2.4.2.4 列表解析
# name = [表达式 变量取值]
squares = [values**2 for values in range(1, 11)]
print(squares)# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
2.4.3 使用列表的一部分
2.4.3.1 切片
# 切片
players = ['charles', 'martina', 'michanl', 'florence', 'eli']
print(players[0:3])# ['charles', 'martina', 'michanl']
如果没有指定第一个索引元素,那么Python将自动从首个元素开始。同理,如果没有指定最后一个索引元素,那么Python以最后一个元素结束。
players = ['charles', 'martina', 'michanl', 'florence', 'eli']
print(players[:3])# ['charles', 'martina', 'michanl']
2.4.3.2 遍历切片
# 遍历切片
players = ['charles', 'martina', 'michanl', 'florence', 'eli']
print("look there are:")
for player in players[:3]:
print(player)
# look there are:
# charles
# martina
# michanl
2.4.3.3 复制列表
注意:复制列表不可以 my_food = friend_food,这不是将副本赋值给新的变量
# 复制列表
my_Food = ['pizza', 'falafel', 'lisa']
friend_food = my_Food[:]
friend_food.append('ice cream')
my_Food.append('shit')
print(friend_food)
print(my_Food)
# ['pizza', 'falafel', 'lisa', 'ice cream']
# ['pizza', 'falafel', 'lisa', 'shit']
2.4.4 元组
python将不能修改的值称为不可变, 而不可变的列表称为元组
2.4.4.1 定义元组
元组看起来像列表,但使用圆括号而非中括号来标识。定义元组后, 就可以使用索引来访问。
## 定义元组
dimensions = (200, 50)
print(dimensions[0])
print(dimensions[1])
# 200
# 50
严格来说,元组只是由逗号标记的,圆括号只是让元组看起来更整洁,更清晰。如果你要定义只包含一个元素的元组,必须在这个元素后面的加上逗号:
例如: my_t = (3,)
创建只包含一个元素的元组通常是没有意义的, 但是自动生成的元组可能就只有一个元素
2.4.4.2 遍历与修改元组的值
- 遍历
dimensions = (200, 50)
for value in dimensions:
print(value)
- 修改
元组不可以被修改,但是可以被重新定义
## 修改元组
dimensions = (200, 50)
for dimension in dimensions:
print(dimension)
dimensions = (400, 100)# 重新定义
for dimension in dimensions:
print(dimension)
# 200
# 50
# 400
# 100
第三章 if语句
3.1 条件测试
3.1.1 大小写
Python检查时严格区分大小写
car = 'AUDI'
car== 'audi'
Out[4]: False
3.1.2 检查多个条件
3.1.2.1 使用and检查多个条件
age_0 = 22
age_1 = 18
age_0 >= 21 and age_1 >= 21
Out[4]: False
age_1 = 22
age_0 >= 21 and age_1 >= 21
Out[6]: True
3.1.2.2 使用or检查多个条件
age_1 = 18
age_0 = 22
age_0 >= 21 or age_1 >= 21
Out[9]: True
age_0 = 18
age_0 >= 21 or age_1 >= 21
Out[11]: False
3.1.2.3 检查特定值是否在列表中
要判断特定值是否在已包含列表中,可以使用关键词in。如果要检查不在,则使用not in。
banned_users = ['andrew', 'carolina', 'david']
user = 'marie'
if user not in banned_users:
print(f"{user.title()}, you can post a response if you wish.")
# Marie, you can post a response if you wish.
3.2 if语句
3.2.1 if语句
if condition_test:
do something
3.2.2 if-else语句
age = 17
if age >= 18:
print("age >= 18")
else:
print("<18")
# <18
3.2.3 if-elif-else 结构
age = 17
if age >= 18:
print("age > 18")
elif age == 18:
print("== 18")
else:
print("<18")
# <18
3.2.4 其他结构
比如:省略else, 多个elif等
3.3 使用if语句处理列表
3.3.1 确定列表不是空
requested_toppings = []
if requested_toppings:
print("okk")
else:
print("Are you sure you want a plain pizza")
# Are you sure you want a plain pizza
第四章 字典
字典是一系列键值对。每一个键值对都与一个值相关联,你可以使用键来访问相关联的值。与值相关联的值是数、字符串、列表甚至是字典。事实上,任何Python对象都可以作为字典中的值。
示例:
alien_0 = {'color': 'green'}
4.1 字典基本操作
4.1.1 访问字典中的值
alien_0 = {'color': 'green'}
print(alien_0['color'])
# green
4.1.2 添加键值对
字典是一种动态结构,可随时在其中添加键值对。要添加键值对,可依次指定字典名、用方括号括起来的键和相关联的值。
alien_0 = {'color': 'green'}
print(alien_0['color'])
green
alien_0['x_position'] = 0
alien_0['y_position'] = 25
print(alien_0)
# {'color': 'green', 'x_position': 0, 'y_position': 25}
4.1.3 创建空字典
alien_0 = {}
4.1.4 修改字典中的值
alien_0 = {'color': 'green'}
print(alien_0['color'])
green
alien_0['x_position'] = 0
alien_0['y_position'] = 25
print(alien_0)
# {'color': 'green', 'x_position': 0, 'y_position': 25}
alien_0['color'] = 'orange'
print(alien_0)
# {'color': 'orange', 'x_position': 0, 'y_position': 25}
4.1.5 删除键值对
可使用del语句将相应的键值对彻底删除。
alien_0['point'] = 15
print(alien_0)
# {'color': 'orange', 'x_position': 0, 'y_position': 25, 'point': 15}
del alien_0['points']
del alien_0['point']
print(alien_0)
# {'color': 'orange', 'x_position': 0, 'y_position': 25}
注意:删除的键值对,会永远消失
4.1.6 由类似对象组成的字典
在最后一个键值对后面加上逗号,为以后在下一行添加键值对做好准备。
favorite_language = {'jen': 'python','sarah' : 'c',}
4.1.7 使用get()来访问值
就字典而言, 我们可以使用方法get()在指定的键不存在时返回第一个默认值,从而避免这样的错误。
方法第一个参数用于指定键,是必不可少的;第二个参数为指定的键不存在时要返回的值,是可选的。
print(alien_0['points'])
Traceback (most recent call last):
File "D:\Anaconda\lib\site-packages\IPython\core\interactiveshell.py", line 3437, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-35-f1f50dde710a>", line 1, in <module>
print(alien_0['points'])
KeyError: 'points'
point_value = alien_0.get('points', 'No point value assigned.')
print(point_value)
# No point value assigned.
如果指定的键不存在,应考虑使用方法get(), 而不是方括号法。
4.2 遍历字典
4.2.1 遍历所有键值对
- key与value可以使用任意名称,注意用看的懂的名称
- items()
user_0 = {"user_name": "liuYu", 'first': 'enrico', 'second' : 'feiMao'}
for key, value in user_0.items():
print(f"\nkey{key}")
print(f"Value:{value}")
#keyuser_name
#Value:liuYu
#keyfirst
#Value:enrico
#keysecond
#Value:feiMao
4.2.2 遍历所有的键
在不需要使用字典的值时,可以使用keys()
favorite_language = {'jen': 'python','sarah' : 'c',}
for name in favorite_language.keys():
print(name)
#jen
#sarah
4.2.3 按照特定顺序遍历字典中所有的键
favorite_language = {'jen': 'python','sarah' : 'c',}
for name in sorted(favorite_language.keys()):
print(name)
4.2.4 遍历字典中所有值
在不需要使用字典的键时,可以使用values()
favorite_language = {'jen': 'python','sarah' : 'c',}
for language in favorite_language.values():
print(language)
为了剔除重复项,可以使用set()。不同与列表与字典,集合不会以特定的顺序存储元素
favorite_language = {'jen': 'python','sarah' : 'c',}
for name in set(favorite_language.keys()):# 此处使用set来提取值中不同的的元素
print(name)
4.3 嵌套
有时候需要将一系列字典存储在列表中,或将列表作为值存储在字典中,这叫嵌套。
4.3.1 字典列表
alien_0 = {'color' : 'green', 'points': 5}
alien_1 = {'color' : 'yellow', 'points': 10}
alien_2 = {'color' : 'red', 'points': 15}
aliens = [alien_0, alien_1, alien_2]
for alien in aliens:
print(alien)
#{'color': 'green', 'points': 5}
#{'color': 'yellow', 'points': 10}
#{'color': 'red', 'points': 15}
4.3.2 在字典中存储列表
favorite_languages = {'jen':['python', 'ruby'], 'sarah' : ['c'], 'edward':['ruby', 'go'], 'phil':['python', 'haskell'],}
for name, languages in favorite_languages.items():
print(f"\n{name.title()}'s favorite language are:")
for language in languages:
print(f"\t{language.title()}")
"""
Jen's favorite language are:
Python
Ruby
Sarah's favorite language are:
C
Edward's favorite language are:
Ruby
Go
Phil's favorite language are:
Python
Haskell
"""
4.3.3 在字典中存储字典
users = {
'aeinstein': {
'first': 'albert',
'last': 'einstein',
'location' : 'priceton'
},
'mcurie': {
'first': 'marie',
'last': 'curie',
'location' : 'paris'
},
}
第五章 用户输入与while循环
5.1 函数input() 的工作原理
message = input("tell me what the truth")
print(message)
# 创建多行提示:
prompt = "if you tell us who you are, we can personlize the message you see."
prompt += "\nWhat is your first name?"
name = input(prompt)
5.2 使用int() 来获取数值输入
在函数input()时,Python将用户输入解读为字符串。如果还是把输入当成数值来使用,那么会出现错误。
为了解决这个问题,我们可以使用函数int(),他让PYthon将输入认为是数值。函数int()将数的字符串表示转换为数值表示。
#使用int() 来获取数值输入
age = input('How tall you are, in inches?')
How tall you are, in inches?>? 12
age = int(age)
age > 18
Out[55]: False
5.3 while循环
5.3.1 使用while循环
使用标志(flag)
5.3.2 使用break退出循环
5.3.3 在循环中使用continue跳过某流程
5.3.4 使用while循环处理列表与字典
while unconfirmed_users:
current_user = unconfirmed_users.pop()
print(f"Verifying user: {current_user.title()}")
confirmed_users.append(current_user)
print("\nthe following users have been confirmed:")
# Verifying user: Brain
# Verifying user: Alice
当前一个字典变为空时,即此时False
5.3.5 删除为特定值的所有列表元素
pets = {}
pets = ['dog', 'cat', 'monkey']
while 'cat' in pets:
pets.remove('cat')
print(pets)
第六章 函数
6.1 定义函数
def greet_user():
print("Hello")
greet_user()
# Hello
6.2 实参与形参
形参:函数完成工作所需的信息
实参:调用函数时传递给函数的信息
6.2.1 传递实参
6.2.1.1 位置实参
此时根据函数参数位置来选择参数。如果位置出错,可能出现意想不到的错误
def describe_pet(animal_type, pet_name):
print(f"My {animal_type}'s name is {pet_name.title()}.")
describe_pet('hamster', 'harry')
# My hamster's name is Harry.
6.2.1.2 关键字实参
def describe_pet(animal_type, pet_name):
print(f"My {animal_type}'s name is {pet_name.title()}.")
describe_pet(animal_type = 'hamster', pet_name = 'harry')# 这两种都行
describe_pet(pet_name = 'harry', animal_type = 'hamster')
# My hamster's name is Harry.
# My hamster's name is Harry.
6.2.1.3 默认值
def describe_pet(animal_type = 'dog', pet_name):
print(f"My {animal_type}'s name is {pet_name.title()}.")
describe_pet('Harry')
# My dog's name is Harry.
6.3 返回值
6.3.1 返回可选值
如果返回可选值,可以使用默认值来处理
def get_formatted_name(first_name, last_name, middle_name = ' '):
if middle_name:
full_name = f"{first_name} {middle_name} {last_name}"
else:
full_name = f"{first_name} {last_name}"
return full_name.title()
mucian = get_formatted_name('jimi', 'hendrix')
print(mucian)
# Jimi Hendrix
注意:禁止函数直接修改列表
function_name(list_name[:])-------->>>这个可以实现副本传递
6.3.2 传递任意数量的实参
def make_pizza(*toppings):
print(toppings)
make_pizza('pepperoni')
make_pizza('mushroom', 'green peppers', 'extra cheese')
#('pepperoni',)
#('mushroom', 'green peppers', 'extra cheese')
形参名*toppings中的星号让python创建一个名为toppings的空元组,并将收到的所有值收入到这个元组中。注意:函数体python将实数参数封装到一个元组中,即使函数只收到一个值。
注意:我们还可以结合使用位置和任意数量参数
例:def make_pizza(size, *topping)
6.3.3 使用任意数量的关键字实参
有时候需要接受任意数量的实参,但预先不知道传递给函数的会是什么样的信息。在这种情况下,可将函数编成能够接受任意数量的键值对——调用语句提供多少就接受多少。
def build_profile(first, last, **user_info):
user_info['first_name'] = first
user_info['last_name'] = last
return user_info
user_profile = build_profile('albert', 'einstein', location = 'princeton', filed = 'physics')
print(user_profile)
# {'location': 'princeton', 'filed': 'physics', 'first_name': 'albert', 'last_name': 'einstein'}
6.4 将函数存储在模块中
使用函数的最大优点是可将代码块与主程序相分离。我们还可以更进一步,将函数的存储在称为模块的独立文件中。再将文件模块导入主程序中。
6.4.1 导入整个模块
要让模块可导,得先创建模块。模块是扩展名为.py的文件。
下面我们创建pizza.py的文件
# pizza.py
def make_pizza(size, *toppings):
print(f"\nMaking a {size} - inch pizza with the following toppings:")
for topping in toppings:
print(f"-{topping}")
我们再创建一个make_pizzas.py的文件,调用此函数。
import pizza
pizza.make_pizza(16, 'peppereroni')
pizza.make_pizza(12, 'peppereroni', 'mushroom', 'extra cheese')
6.4.2 导入特定的函数
# 格式1:
from module_name import function_name
# 格式2:
from module_name import function_name1, function_name2, function_name3
# 示例:
from pizza import make_pizza
make_pizza(12, 'papper')
6.4.3 使用as给函数指定别名
# 格式:
from module_name import function_name as fn
# 示例:
from pizza import make_pizza as mp
mp(16, 'pepperoni')
6.4.4 使用as给模块指定别名
# 格式:
import module_name as mn
# 示例:
import pizza as p
p.make_pizza(16, 'pepperoni')
注意:使用*可以导入全部函数
第七章 类
7.1 创建和使用类
7.1.1 创建Dog类
class Dog:
def _init_(self, name, age):
self.name = name
self.age = age
def sit(self):
print(f"{self.name} is now sitting.")
def roll_over(self):
print(f"{self.name}roll over!")
方法
_init_():
此方法为特殊方法,每当你使用Dog类创建新对象时,Python会自动调用该方法。在这个方法的名称中,开头语末尾都有两个下划线,这个是一个约定,旨在避免python默认方法与普通方法发生冲突。务必保证两边都有两个下划线,否则当函数调用时将不会自动调用该函数,进而引起难以发现的问题。
我们将方法__init__()定义的成包含是三个形参:self、 name和age。在这个方法的定义中,形参self() 必不可少,而且必须位于其他形参的前面。为何必须在方法定义中包含形参self呢?因为Python调用这个方法来创建Dog实例时,将自动传入实参self。每个与实例相关联的方法调用都自动传递实参self,它是一个指向实例本身的引用,让实例能够访问类中的属性和方法。创建Dog实例时,Python将调用Dog类的方法_init_()。我们将通过实参向Dog()传递名字和年龄,self会自动传递,因此不需要传递它。每当根据Dog类创建实例时,都只需给最后两个形参(name和age)提供值。
7.1.2 根据类创建实例
my_dog = Dog('Willie', 6)
print(f"My dog's name is {my_dog.name}.")
print(f"My dog is {mydog.age} years old.")
- 访问属性:
my_dog.name
- 调用方法
my_dog.sit()
- 创建多个实例
洛洛洛
7.2 使用类和实例
7.2.1 Car类
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
def get_descriptive_name(self):
long_name = f"{self.year}{self.make}{self.mode}"
return long_name.title()
my_new_car = Car('audi', 'a4', 2019)
print(my_new_car.get_descriptive_name())
7.2.2 给属性指定默认值
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = 0
7.2.3 修改属性的值
- 直接修改属性的值
my_new_car.odometer_reading = 23
my_new_car.read_odomenter()
- 通过方法修改属性的值
def update——odometer(self, milage):
self.odometer_reading = mileage
my_new_car.update_odometer(23)
my_new_car.read_odometer()
7.3 继承
在继承时,并非总是要从空白开始。如果要编写的类是另一个现成类的特殊版本,可以使用继承。一个类继承另一个类时,将自动获得另一个类的所有属性与方法。原有的类称为父类,而新的类称为子类。子类继承了父类所有属性和方法,同时还有属于自己的方法。
7.3.1 子类的方法__init__()
下面创建ElectricCar类的一个简单版本,他具备Car类的所有功能
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
def get_descriptive_name(self):
long_name = f"{self.year}{self.make}{self.mode}"
return long_name.title()
def update——odometer(self, milage):
self.odometer_reading = mileage
class ElectricCar(Car):
def __init__(self, make, model, year):
super().__init__(make, model, year)
my_tesla = ElectricCar('tesla', 'model s', 2019)
print(my_tesla.get_descriptive_name())
super()是一个特殊函数,让你能够调用父类的方法。这行代码让python调用Car类的方法__init__(),让ELectricCar 实例包含这个方法中定义的所有属性。父类也称为超类(superclass), 名称super就此而来。
7.3.2 给子类定义属性和方法
class ElectricCar(Car):
def __init__(self, make, model, year):
super().__init__(make, model, year)
self.battery_size = 75# 定义子类特有属性
def describe_battery(self):# 定义子类特有方法
print(f"This car has a {self.battery_size}-kwh battery.")
7.3.3 重写子类的方法
class class ElectricCar(Car):
def fill_gas_tank(self):
print("This car does't have tank.")
现在如果有人对电动车调用方法fill_gas_tank(), Python将忽略Car类中的方法,转而运行上述代码。使用继承时,可让子类保证从父类继承的是精华。
7.3.4 将实例用作属性
class Car:
--snip--
class Battery:
def __init__(self, battery_size = 75):
self.battery_size = battery_size
def describe_battery(self):
print(f"This car has a {self.battery_size}-kwh battery.")
class ElectricCar(Car):
def __init__(self, make, model, year):
super().__init__(make, model, year)
self.battery = Battery()# 定义子类特有属性
def describe_battery(self):# 定义子类特有方法
print(f"This car has a {self.battery_size}-kwh battery.")
my_tesla = ElectricCar('tesla', 'models', 2019)
print(my_tesla.battery.describe_battery())# 我们可以将实例作为属性
7.4 导入类
7.4.1 导入单个类
# car.py
# 一个可以用于表示汽车的类
class Car:
"""这是一个汽车类"""
def __init__(self, make, model, year):
"""描述汽车的属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性名称"""
long_name = f"{self.year}{self.name}{self.model}."
return long_name.title()
def read_odometer(self):
"""打印一条关于里程的消息"""
print(f"This car has {self.obometer_reading} miles on it.")
# my_car.py
from car import Car# 导入单个类
my_new_car = Car('audi', 'a4', 2019)
print(my_new_car.get_descriptive_name())
my_new_car.obometer_reading = 23
my_new_car.read_obometer()
注意:书写类时,我们应包含模块级文档字符串,对该模块的内容作出简要的描述。此外,导入类简化了主程序文件。
7.4.2 在一个模块中存储多个类
虽然同一个类之间应存在某种相关性,但可以根据需要在一个模块中存储任意数量的类。
# 这里只是示例
class Car:
--snip--
class ElctricCar:
--snip--
7.4.3 在一个模块中导入多个类
# 语法结构
from module_name import class_name1, class_name2, ...
7.4.4 导入整个模块
# 语法结构
import car
7.4.5 导入模块中的所有类
# 语法结构
from module_name import *
注意:这不推荐使用此方法,因为其导入类不够明确。所以,容易导致重名的情况。如果需要从一个模块导入很多类,最好是导入整模块,并使用module_name.ClassName语法来访问类。
7.4.6 使用别名
# 语法规范
from module_name import ElectricCar as EC
7.5 类编码风格
类名都要采用驼峰命名法,即类名中每个字母的首字母都要大写,而使用下划线。实例名和模块名采用小写格式,并且在单词之间添加下横线。
第八章 文件和异常
8.1 从文件中读取数据
8.1.1 读取整个文件
要读取文件,需要一个包含几行文本的文件。下面首先创建一个包含几行文本的文件。下面首先创建一个文件,它包含精确到小数点后30位的圆周率值,并且小数点后每10位换行:
# pi_digits.py
3.1415926535
8979323846
2643383279
# 执行程序
with open('pi_digit.txt') as file_object: # open相当于一个管道,此处为默认设置
contents = file_object.read()
print(contents)
'''
res:
3.1415926535
8979323846
2643383279
'''
在这个程序中,我们注意到open(), 但没有调用close()。也可以调用close(),但这样做时,如果程序中存在bug导致方法close()未执行。文件将不会关闭。这看似微不足道,但未妥善关闭文件会导致数据丢失或受损。如果程序中过早调用close(),你会发现这可能在使用过程中,文件已经关闭,这样导致的错误会更多。我们其实就可以使用前面所示的结构,可让python确定:你只管打开文件,并在需要的时候使用它,python会自动将其关闭。
我们还发现结果末尾还多出一个空行,这是由于read()到文件末尾时返回一个空字符串,而将这个空字符串显示出来就是一个空行。我们可以使用下面程序去掉空行。
# 去除空行
with open('pi_digit.txt') as file_object:
contents = file_object.read()
print(contents.rstrip())
'''
res:
3.1415926535
8979323846
2643383279
'''
8.1.2 文件路径
- 相对路径:
with open('test_file/ file_name.txt') as file_object:
# 注意:显示文件路径时,Windows使用的是反斜杠(\)而不是斜杆(/),但是代码中依然可以使用斜杠。
- 绝对路径:
file_path = 'C:\Windows\addins'
with open(file_path) as file_object:
# 如果在文件路径中直接使用反斜杠,将引发错误,因为与转义字符冲突。可对文件路径的每一个反斜杠进行转义,如:“C:\\Windows\\addins”
8.1.3 逐行读取
filename = 'pi_digits.txt'
with open(filename) as file_object:
for line in file_object:
print(line)
'''
res:
3.1415926535
8979323846
2643383279
'''
将要读取的文件的名称赋值给变量filename。这是使用文件时的一种常见的做法。变量filename表示的并非实际文件——他只是一个让python知道到哪里查找文件的字符串。因此可以将’pi_digit.txt’替换为要使用的另一个文件的名称。调用open()后,将一个表示文件及其内容的对象赋给了变量file_object。这时候发现空行更多了,可以依旧采用上文方法来消除空行。
8.1.4 创建一个包含文件各行内容的列表
如果要使用文件中内容的,就要把文件内容保存下来。
filename = 'pi_digit.txt'
with open(filename) as file_object:
lines = file_object.readlines()
for line in lines:
print(line.rstrip())
'''
res:
3.1415926535
8979323846
2643383279
'''
readlines()从文件中读取每一行,并将其存储在一个列表中。接下来,该列表的被赋值给变量lines。
8.1.5 使用文件的内容
在读取文件时,Python将其中的所有文本都解读为字符串。如果读取的是数,并将其作为数值使用,就必须使用int()将其转换,或者使用float()函数转换为浮点数。
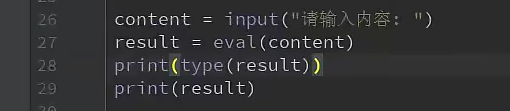
8.1.6 常见的输入函数
input("输入你的姓名")
eval(content)
# 将content转换为代码,如果未定义的话,会报错.而不是字符串
print(content)
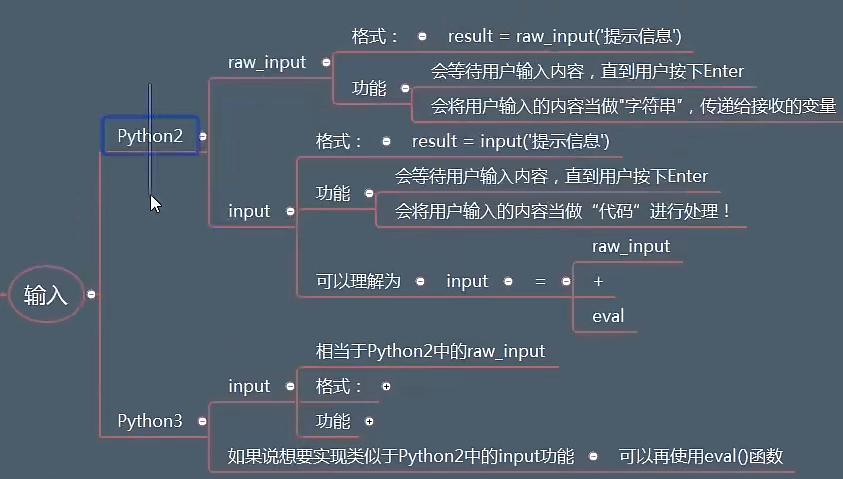
如何在Python3中实现Python2的功能:
8.2 写入文件
8.2.1 写入空文件
filename = 'programming.txt'
with open(filename) as file_object:
file_object.write("I love programming.")
在本例中, 调用open()时提供两个实参。第一个是要打开的文件名称, 第二个实参(‘w’)告诉Python, 要以写入模式打开这个文件。打开文件时,可指定读取模式(‘r’)、写入模式(‘w’)、附加模式(‘a’)和读写模式(‘r+’)。如果省略第模式参数,将以只读模式打开文件。
如果要写入的文件不存在,函数open()将自动创建它。然而,以写入模式(‘w’)打开文件时千万要小心,因为如果指定的文件已经存在,Python将在返回文件时清空该文件的内容。
Python只能将字符串写入文本文件。要将数值数据存储到文本文件中,必须先要使用str()将其装换为字符串格式。
8.2.2 写入多行
注意:函数write()不会在写入的文本末尾添加换行符,因此如果写入多行时没有指定换行符,文件看起来不会像你希望的那样。
filename = 'programming.txt'
with open(filename) as file_object:
file_object.write("I love programming.\n")
file_object.write("I don't love gamming.\n")
8.2.3 附加到文件
如果要给文件添加内容,而不是覆盖原来内容,可以以附加模式打开文件。如果指定的文件不存在,Python将为你创建一个文件。
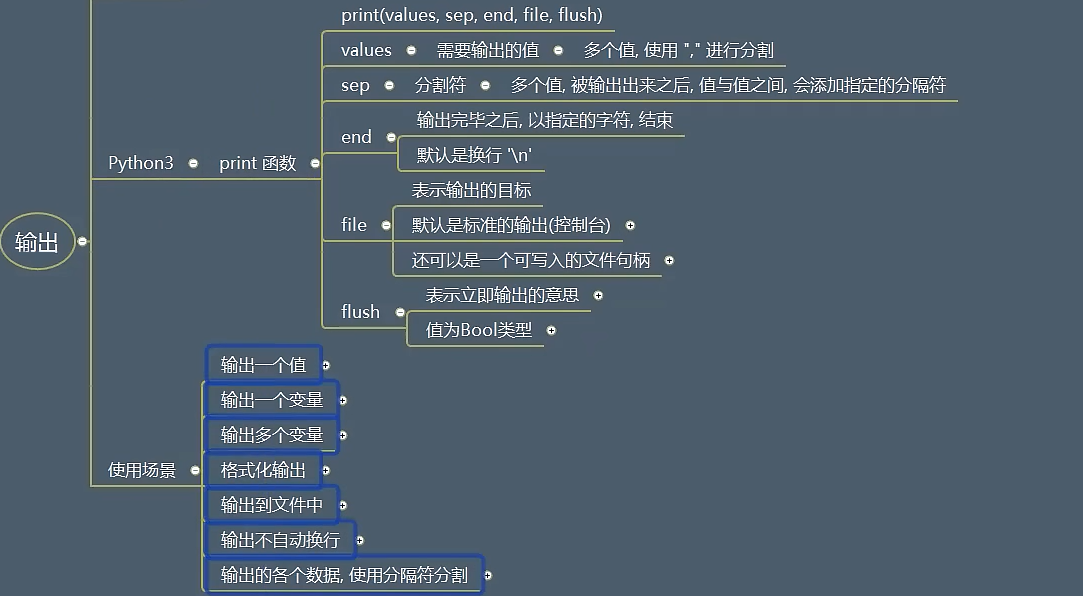
8.2.4 常见的输出函数
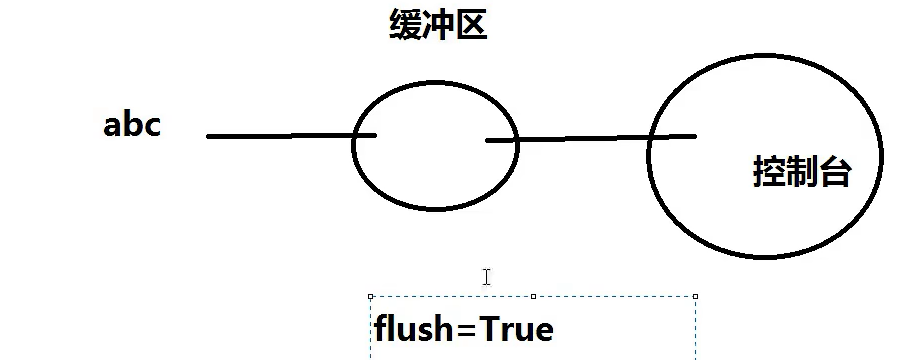
flush的作用:
决定是否直接到控制台(下图是
print(123, end="") # 表示不换行输出
# 关于分隔符的使用
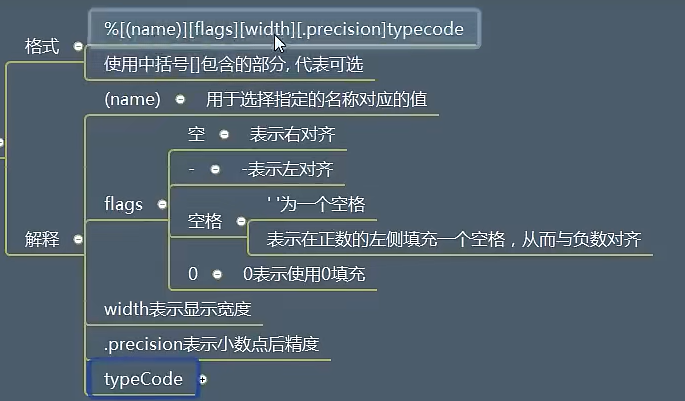
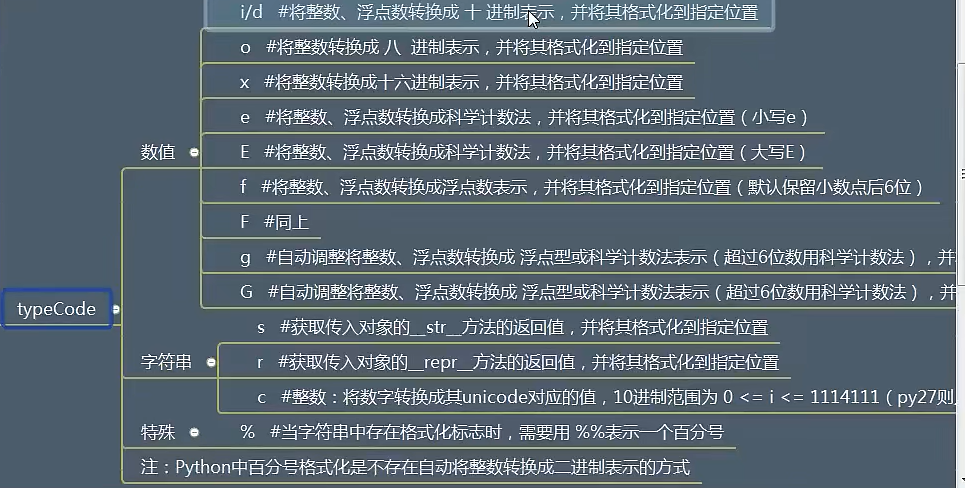
# [(name)][flags][width][.precision]typecode, 其中[]表示可以省略
# (name)
# 表示,根据,制定的名称(key), 查找对应的值,格式化到字符串当中
# 示例如下:
mathScore = 165
englishScore = 99
print("数学成绩为%d,英语成绩为%d"%(mathScore, englishScore))
print("数学成绩为%(ms)d,英语成绩为%(es)d"%({"es":englishScore, "ms": mathScore})) # 后面的是一个字典了
# width, 表示占用的宽度
print("%3d" % mathScore) # 输出的结果为:“ 99”, 默认左边对齐
print("% d" % mathScore) # 输出的结果为:“ 99”, 前面加上一个空格
print("%03d" % mathScore) # 输出的结果为:“099”, 用0来填充

8.3 异常
8.3.1 处理ZeroDivisionError异常
# 以下会出现错误
print(5/0)
8.3.2 使用try-except代码块
try:
print(5/0)
except ZeroDivisionError:
print("You cant't divide by zero!")
使用异常可以避免程序奔溃。
8.3.3 else代码块
--snip--
while True:
--snip--
if second_number == 'q'
break
try:
answer = int(first_number)/int(second_number)
except ZeroDivisionError:
print("error")
else:
print(answer)
有时候,有一些仅仅try代码块成功时才需要执行的代码,这些代码放在else代码块中。
8.3.4 处理FileNotFoundError异常
file_name = 'alice.txt'
with open(filename, encoding = 'utf-8') as f:
contents = f.read()
这里有两个不同之处:一是使用变量f来表示文件对象,这是一种常见方法。二是给参数encoding指定了值,在系统默认编码与要读取文件使用的编码不一致时,必须这样做。
file_name = 'alice.txt'
try:
with open(filename, encoding = 'utf-8') as f:
contents = f.read()
except FileNotFoundError:
print('error')
8.3.5 静默失败
Python有个pass语句,可让Python在代码块中什么都不要做:
def count_words(filename):
try:
--snip--
except:
pass
else:
--snip--
filename = ['alice.txt', 'litte_women.txt']
for filename in filenames:
count_words(filename)
pass语句还充当占位符,提醒你在那里什么没做,并且也许要做什么。
8.4 存储数据
很多程序都要求用户输入某种信息,如让用户存储游戏信息什么的。用户关闭程序时还要保存数据。一种简单的方式就是使用模块json来存储数据。
模块json让你能够将简单的Python数据结构转存到文件中,并在程序运行时加载该文件。使用json还可以在python程序之间分享数据。
8.4.1 使用json.dump()和json.load()
函数json.dump()接收两个实参:要存储的数据,以及可用于存储数据的文件对象。
import json
number = [2, 3, 4, 5, 6]
filename = 'number.json'
with open(filename, 'w') as f:
json.dump(number, f)
这个程序没有输出,当打开文件 number.json 来看看内容。数据存储格式与python中的一样:
[2, 3, 4, 5, 6]
下面使用json.load()将列表读取到内存中:
import json
filename = 'number.json'
with open(filename) as f:
numbers = json.load(f)
print(numbers)
# [2, 3, 4, 5, 6]
这是在程序之间共享数据的简单方式。
8.4.2 保存与读取用户生成的数据
使用json保存的用户数据大有裨益,因为如果不是以某种方式存储,用户的信息会在程序停止运行时丢失。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











