







 文章探讨了多线程环境下线程安全的重要性,指出线程不安全主要是由于抢占式执行、多个线程修改同一变量、非原子操作和内存可见性问题导致。通过例子展示了两个线程自增同一变量可能导致的不确定性。解决线程安全问题通常采用加锁机制,如Java中的`synchronized`关键字,以及`volatile`关键字来保证内存可见性和避免指令重排序。
文章探讨了多线程环境下线程安全的重要性,指出线程不安全主要是由于抢占式执行、多个线程修改同一变量、非原子操作和内存可见性问题导致。通过例子展示了两个线程自增同一变量可能导致的不确定性。解决线程安全问题通常采用加锁机制,如Java中的`synchronized`关键字,以及`volatile`关键字来保证内存可见性和避免指令重排序。
线程安全问题
是多线程中的重点和难点
线程安全:
在多线程各种随机的调度顺序下,都能够输出符合预期的结果,或者按照预期要求来执行代码没有产生bug。
线程不安全:
如果在多线程随机调度下代码出现bug,此时就认为是线程不安全。
线程不安全情况:
线程不安全的原因:
1.抢占式执行。
(线程不安全的罪魁祸首)
由CPU
内核实现的,
多个线程的调度执行过程,可以视为是“全随机"的。
(也不能理解成纯的随机--但是确实在应用层程序
这里是没有规律的)
2.多个线程修改同一个变量。
一个线程修改一个变量,没事。
多个线程读同一个变量.没事,
多个线程修改不同变量.还没事。
3.修改操作不是原子的。
解决线程安全问题,最常见的办法,就是从这里入手。
把多个操作通过特殊手段, 打包成一个原子操作。
4.内存可见性问题
也会引发线程不安全。
JVM的代码优化引入的bug 。
5.指令重排序
也会引发线程不安全
2.多个线程修改同一个变量 / 修改操作不是原子的。
问题:
创建两个线程,对同一个变量各自,自增50000
预期结果应该是10_0000但是输出结果是随机的,
此时出现了BUG(与需求不符)
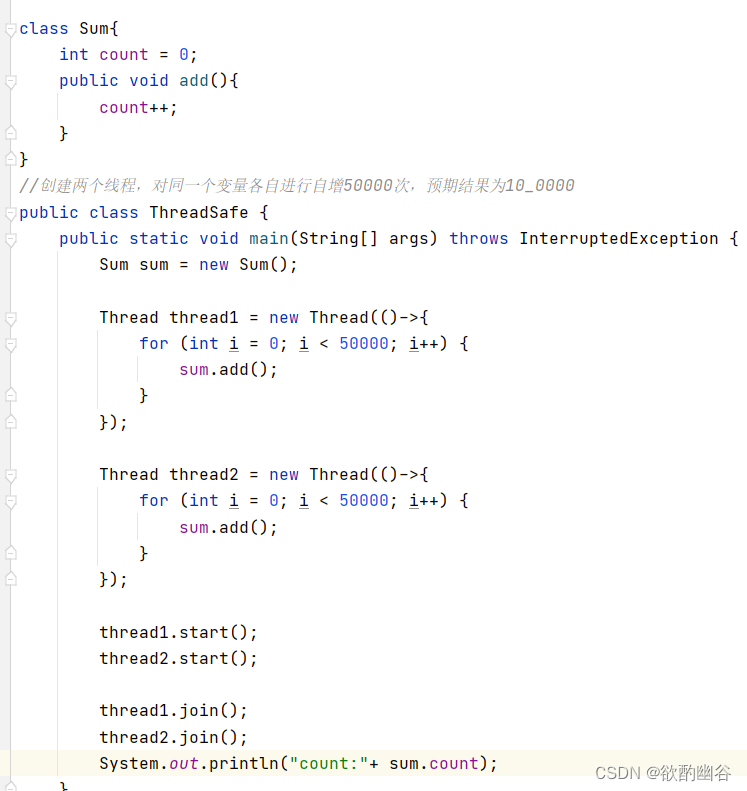
可以看出三次所得结果都不一样
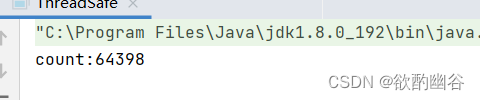
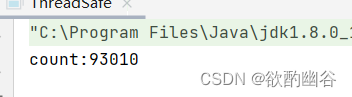
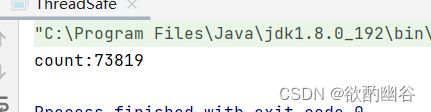
上述问题是怎么出现的呢?
进行的count ++操作,操作系统底层,是三条指令在CPU上完成的:
(1)把内存的数据读取到CPU寄存器中:
load
(2)把CPU的寄存器中的值,进行+ 1:
add
(3)把寄存器中的值,写回到内存中:
save
由于当前是两个线程修改一个变量,
由于并且每次修改是三个步骤(不是原子的)
由于每个线程之间的调度顺序是不确定,
因此两个线程在真正执行这些操作的时候,就可能有多种执行的排列顺序。
例如下图这种操作
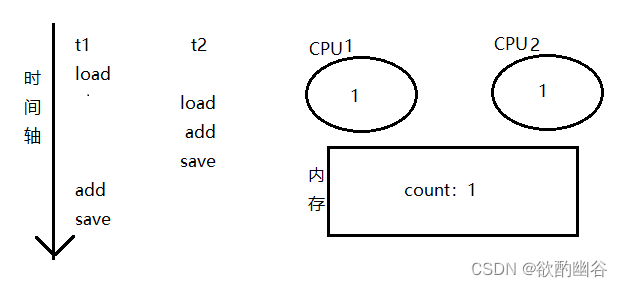
(1)
count初始值为0
,t1将内存中count值先读取到CPU1(t1.load)
(2)
count值为0,t2将内存中count值读取到CPU2(t2.load)
(3)CPU2中count++,此时
CPU2中count = 1
(t2.add)
(4)CPU2将count值写回到内存中去,此时内存中count值为1(
t2.save)
(5)
CPU1中count++,此时
CPU1中count = 1
(t1.add)
(6)CPU1将count值写回到内存中去,此时
内存中count值为1
(
t1.save)
最终通过上面执行步骤内存中的值为1-->count两次add操作只增加了1
自增数值会出现不确定结果
在形如这样的排列顺序下,此时多线程自增就会存在“线程安全问题" 。
整个线程调度过程中,执行的顺序都是随机的。
由于在调度过程中,出现"串行执行"两种情况的次数和其他情况的次数,不确定
因此得到的结果就是不确定的值。
结果大概范围
虽然结果不确定,可以知道结果的范围:
考虑极端情况下:
如果两个线程之间的调度全是串行执行,结果就是10w
如果两个线程之间的调度全都是其他情况,一次串行执行都没有,结果就是5w
最终的结果5w- 10w之间的数字(正常来说是这个样子的)
极少数情况,会得到了小于 5w的结果。
得到小于5w结果

此时t2先进行两次add操作,count = 2,放回内存,接着t1进行一次add操作count = 1,放回内存。此时内存中count=1。也就是说总共count执行3次add操作,但是结果为1,则最终可能出现结果小于5w
如何解决线程不安全问题:
加锁
解决线程安全问题,最常见的办法,就是
把多个操作通过特殊手段,打包成一个原子操作。
Java代码中,进行加锁,使用
synchronized
关键字。
synchronized修饰方法
以下是我们最基本的使用,
使用synchronized关键字,来修饰一个普通方法
当进入方法的时候,就会加锁,
方法执行完毕,自然解锁。
锁,具有独占特性。
如果当前锁没人来加,加锁操作就能成功.
如果当前锁已经被人给加上了,加锁操作就会阻塞等待。
如果只给一个线程加锁,这个是没用的。
一个线程加锁不涉及到"锁竞争'
也就不会阻塞等待,
也就不会并发修改->串行修改。
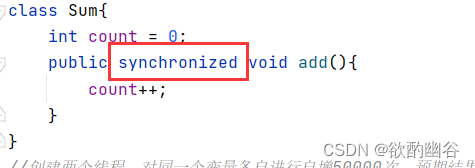
得出结果为预期结果
当对线程1和线程2的相同count变量进行加锁后,两个for循环是并发执行的,而
sum.add()方法中count++操作会被上锁,只有当线程1整个操作完成时,才会执行线程2

这个操作确实相当于把'并发"变成了“串行"。
也会减慢程序的执行效率。
但相对于确确实实的串行来说,效率还是高一些,因为只针对被加锁的对象或者方法,变量相对于串行执行,但是未被加锁的程序还是并发执行的。
加锁不是说CPU 一下执行完所有操作。中间也是有可能会有调度切换的.
即使t1切换走了,t2仍然是BLOCKED状态,无法在CPU上运行的--
(线程调度出CPU,但是锁没释放,这个时候被加锁的线程还是无法被CPU调度)
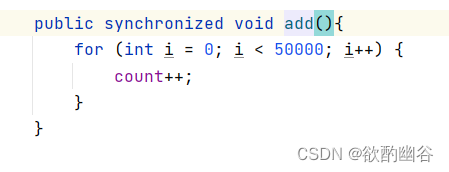

如果把for也写到加锁的代码里头,
这个时候就和完全串行就一样了。
add里面涉及到
加锁你要考虑好锁哪段代码。
锁的代码范围不一样, 对代码执行效果
会有很大的影响
,
因此这个代码仍然比两个循环串行执行要快,但是肯定比不加锁要慢。
锁的代码越多,就叫做
“
锁的粒度越大/越粗
"
.锁的代码越少,就叫做“
锁的粒度越小/越细
"
synchronized修饰代码块

( )里面要填个东西,填的东西就是你要针对哪个对象进行加锁。
this指当前对象加锁,一般情况下this满足大多数需求,具体场景具体分析。
(被用来加锁的对象,就简称为“锁对象" )
注意:
使用锁的时候,一定要明确,当前是针对哪个对象加锁很关键!!!直接影响到后面锁操作是否会触发阻塞!!
在Java中,任意的对象都可以作为锁对象(这一点和其他编程语言 差别很大. C++/Python/Go等语言中,正常的对象都不能作为锁对
象只有特定的对象可以用于加.).
任意对象都可以在synchronized里面作为锁对象。写多线程代码的时候不关心这个锁对象究竟是谁,是哪种形态。只是关心,两个线程是否是锁同一个对象.是锁同一个对象就有竞争。锁不同对象就无竞争!!
4.内存可见性

系统执行上述操作,首先要将count值读取到内存(Load),然后再由
CPU
进行比较。
读内存(LOAD)消耗的时间
和比较(CMP)消耗的时间哪个更费时间?
CPU读写数据最快,内存次之,硬盘最慢。
CPU比内存快3-4个数量级,内存又比硬盘快3-4个数量级。(不是硬盘慢,而是CPU实在是太快了!)
因此LOAD消耗时间长比CMP慢3-4个数量级(1w倍)。load比cmp慢太多,所以
既然你频繁执行LOAD,并且LOAD结果还一样,干脆就执行一次LOAD就行了,
后续进行CMP就不再重新读内存了。
这样就导致了下面的问题,系统只读一次内存,当另一个线程修改值后,t1数据不会发生变化,也就是
t2修改内存,t1没有感知到此时就造成了
内存可见性问题
,它是编译器优化带来的问题,这种优化取决于代码内容还有运行环境。
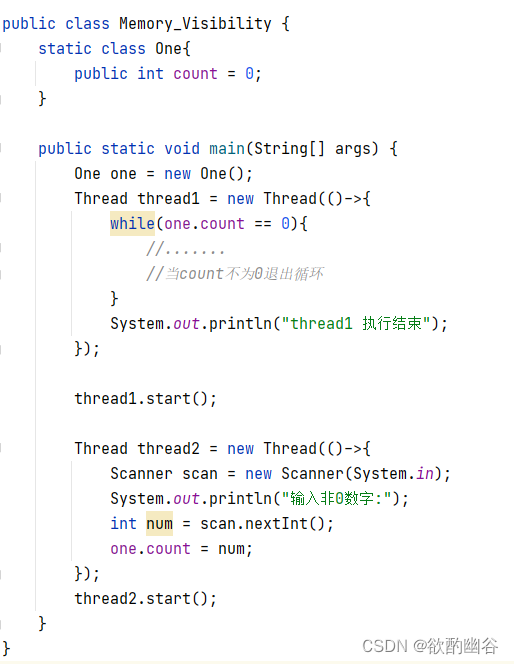
但是刚才的修改,对于t1的读内存操作不会有影响。
因为t1已经被优化成不再循环读内存了(读取一次就完了)因此
输入1发现并没结束线程 。
既然编译器自己的判定不准了,把不该优化的给优化了,就可让我们显式的提醒编译器,这个地方不要优化,
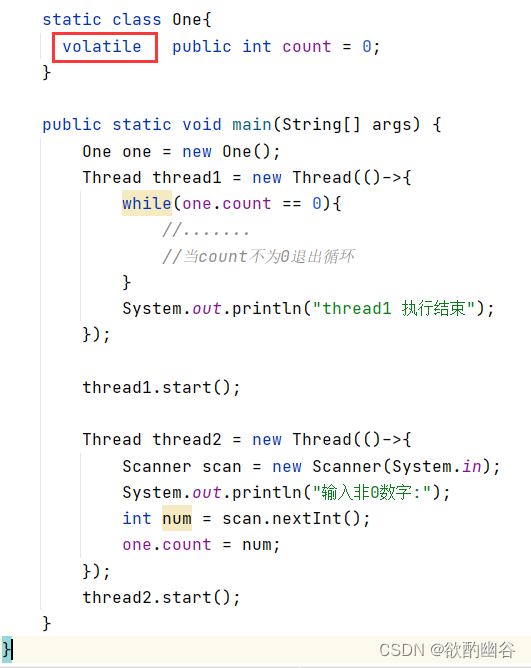
也就是volatile关键字的作用。
Volatile:保证内存可见性,避免指令重排序,不保证原子性
(1)Volatile(
"可变的"
)
可以使用这个关键字来修饰一个变量,
此时被修饰的变量,编译器就不会做出"不读内存,只读寄存器"这样的优化!!
(2)Volatile禁止了编译器优化,避免了直接读取CPU寄存器中缓存的数据,而是每次都重新读内存
即使不加volatile也会正常退出

上述现象原因:
编译器是否优化取决于代码内容还有运行环境,由于上述循环体内睡眠1秒,对于程序来说优化与不优化没有明显区别,当执行速度较快时(只进行比较等执行速度快的操作),若编译器进行优化,减少将数据读取到内存的时间,此时提升效果明显因此编译器会进行优化,只读取一次数据。

















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









