



- 核心差异:从优化目标、训练范式、数据依赖三个维度对比
- 技术类比:PPO像 教练+裁判 双人训练,DPO是 直接模仿学霸答题
- 场景选择:根据数据规模、反馈延迟、资源条件决定技术选型
首先,PPO是一种强化学习算法,常用于训练策略模型,通过限制策略更新的幅度来确保稳定性。
而DPO是另一种优化方法,可能更直接地利用人类偏好数据来调整模型,不需要显式的奖励模型,接下来,我需要明确他们的核心区别,比如是否需要奖励模型、训练效率、对数据的依赖等。
然后,结合真实项目案例。比如,在对话生成或者推荐系统中,如何选择使用PPO还是DPO,两者的效果对比,有什么样的结果差异。需要具体说明在项目遇到的问题,如何选择方法,调参过程,以及最终效果。
答题思路可能需要先定义PPO和DPO,然后分点对比它们的区别,在结合实际项目说明应用场景和效果。最后总结各自的适用情况。
不过,可能存在一些混淆点,比如DPO是否属于强化学习的范畴,或者它们如何利用偏好数据。需要确保自己对两者的理解准确,避免技术细节上的错误。另外,项目案例需要具体,比如在微调对话模型时,使用DPO处理人类反馈数据,而PPO用于更复杂的强化学习环境。
可能还需要考虑计算资源和训I练效率,PPO通常需要更多的计算资源,因为涉及多个策略更新步骤和奖励模型的训练,而DPO可能更高效,因为它直接优化偏好数据,不需要奖励模型。这也需要在项目案例中体现,比如资源有限时选择DPO,或者需要更高稳定性时选择PPO。
总结时,要强调两者的不同应用场景,PPO适用于需要精细策略调整和复杂奖励信号的情况,而DPO适合有明确偏好数据且希望简化训练流程的情况。
1.优化目标差异
·PPO(Proximal Policy Optimization):
目标:通过限制策略更新幅度(KL散度约束)最大化奖励期望。
关键点:需预训l练奖励模型(RewardModel),通过策略-奖励交互迭代优化
·DPO (Direct Preference Optimization):
。目标:直接利用人类偏好数据,将策略对齐到偏好分布
。关键点:绕过显式奖励建模,直接通过偏好对(好答案vs坏答案)优化策略
2.训练范式对比
维度
PPO
DPO
数据需求
需要大量无标注数据+奖励模型训练数据
仅需偏好对(<好答案,坏答案>)
计算复杂度
高(需多次策略-奖励模型交互)
低(单阶段端到端训l练)
稳定性
需谨慎调参(KL惩罚系数等)
更鲁棒(隐式约束策略偏离)
适用场景
复杂奖励信号(如游戏AI)
明确偏好反馈(如对话质量排序)
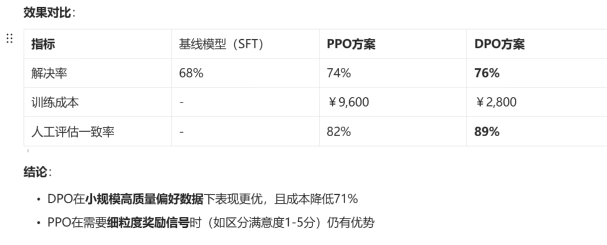
3.项目案例(智能客服满意度优化)
背景:某银行需提升客服对话的解决率(SuccessRate),基线模型(SFT微调)的解决率为68%
实验设计:
·PPO方案:
a,训练奖励模型:标注10万条对话数据(满意度打分1-5)
b.策略优化:基于RewardModel进行5轮PPO迭代
c.资源消耗:8卡A100×36小时
·DPO方案:
a,数据构造:从历史对话中抽取3万组<好回答,坏回答>对
b,单阶段训l练:基于Zephyr-7B进行DPO微调
c.资源消耗:4卡A100×12小时
示例回答
PPO和DPO的核心区别在于如何利用反馈信号。比如在银行客服项目中,PPO需要先训练一个打分模型,再让AI反复试错优化,成本较高但适合复杂场景;而DPO直接让人标注‘好回答vs坏回答’对,让AI模仿学习,成本降低70%且效果更好。最终我们选择DPO,将解决率从68%提升到76%。
总结要点
1.技术选型指南:
。数据量少但质量高→DPO(医疗、金融等垂直领域)
。需多维奖励信号→PPO(游戏、复杂决策场景)
。资源紧张→DPO(训I练速度提升3-5倍)
2.实战技巧:
。DPO数据构造:通过对比学习采样(如同一问题不同回复的胜率排序)
。PPO调参关键:KL散度系数(通常0.1-0.2)和奖励缩放系数
3.趋势扩展:
。混合训I练:PPO+DPO分阶段训练(DPO初始化一PPO精细优化)
。泛化改进:DPO与RLAIF结合(用AI替代人类生成偏好对)

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









