







Abstract
TransVG通过 Transformer 建立视觉和语言的多模态对应关系,并通过直接回归框坐标的方式来定位图像中与语言描述相关的区域。尽管 TransVG 提出了更简化的多模态融合方法,但 TransVG 中的核心融合 Transformer 是一个独立的模型,必须从头开始在有限的视觉定位数据上进行训练。这使得优化变得困难,且可能导致性能不理想。
TransVG++对模型进行了两方面的改进:
- 使用 Vision Transformer(ViT):将框架升级为完全基于 Transformer 的模型,通过 Vision Transformer 来编码视觉特征。ViT 是一种使用 Transformer 架构处理图像的技术,能够提供高效的视觉特征表示。
- 语言条件的视觉 Transformer(LC-ViT):提出了一种新的方法,移除了外部的融合模块,利用 Vision Transformer 在中间层进行视觉和语言信息的融合。这种方法能够有效地进行视觉-语言的融合,并提高了模型的整体性能。
INTRODUCTION
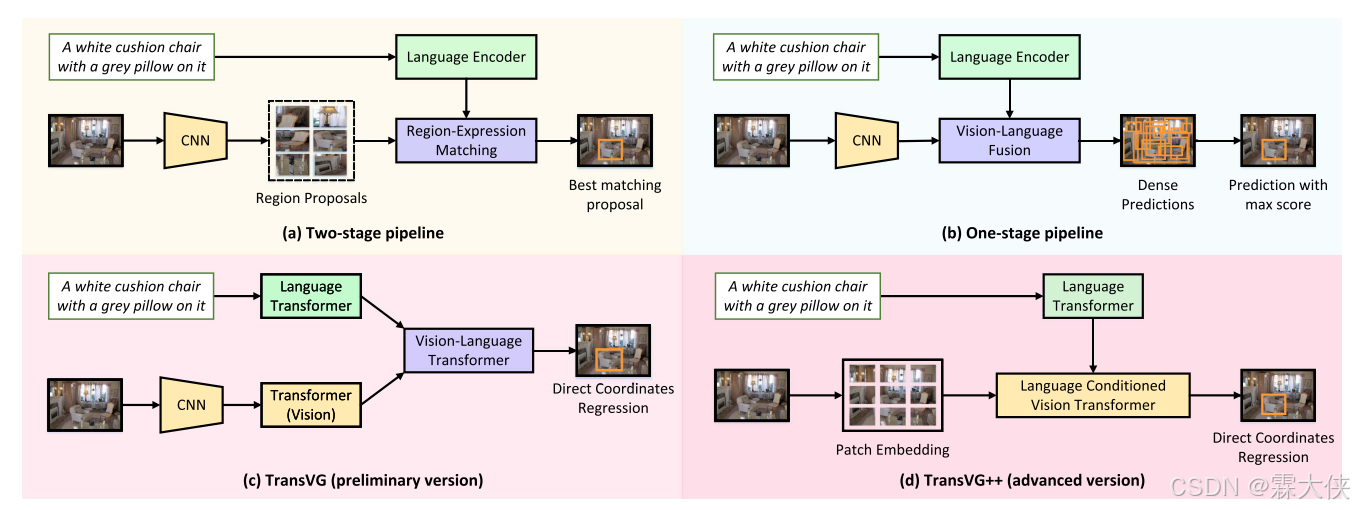
作者一开始提出的TransVG的基本元架构其实和one stage和Two Stage提出的元架构是一样的,包括两个独立的单模态特征编码器、一个独立的多模态融合或匹配模块以及一个预测模块,在这个元架构中,视觉编码器和语言
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









