






目录
1. 支持openAI,DeepSeek,Qwen等,也支持本地模型的调用
(三) SpringBoot项目中使用LangChain4j
一、 引言

- 所以 LangChain4j 就是一个通过
抽象统一API、提供便捷可用的工具箱来简化 Java 应用程序集成LLMs的框架 - LangChain4j 与 Spring AI 的宗旨基本一致,为简化 Java 应用快速接入 LLMs 而生,只是其各自侧重点、框架的能力有所不同而已。
二、介绍
记录本人对LangChain4j的学习使用,以及对AI模型的使用!
本文没有实现过程,只记录实现结果,和学习过程中的总结
LangChain4j官网 :LangChain4j | LangChain4j
三、LangChain4j的学习使用
(一) LangChain4j的初步了解
集成能力
- 集成 15+个 语言大模型 : Comparison Table of all supported Language Models | LangChain4j
- 集成 15+个 向量数据库 : Comparison table of all supported Embedding Stores | LangChain4j
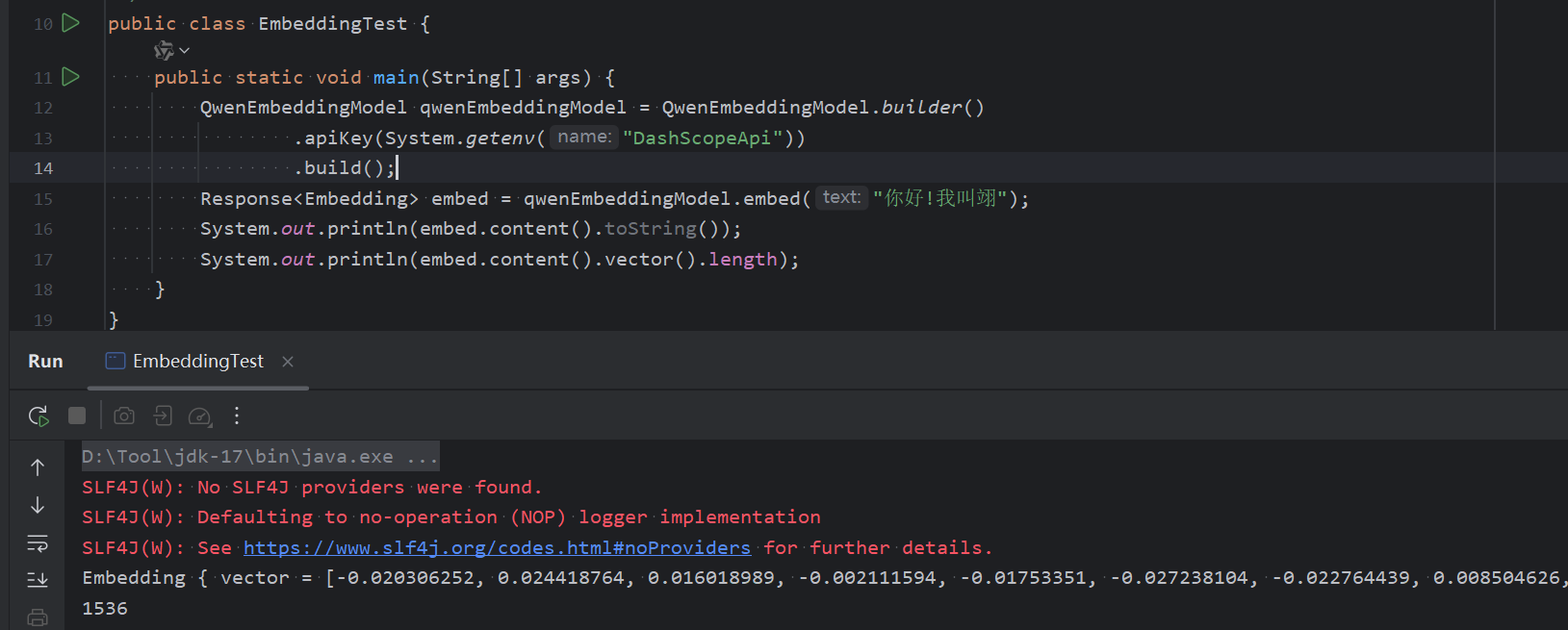
- 集成 10+个 嵌入模型 : Embedding Models | LangChain4j
- 集成 5+ 个 图片大模型 : https://docs.langchain4j.dev/category/image-models/
- 集成 5+个 评分重排名模型 : Scoring (Reranking) Models | LangChain4j
- 集成 2个 代码执行引擎,支持动态函数调用(Function Calling) : Code Execution Engines | LangChain4j
功能能力
- 同步、流式聊天模式,支持多种格式化输出方法 : Response Streaming | LangChain4j
- 提示词模板、聊天记忆 : Chat Memory | LangChain4j
- 支持工具(函数调用 Function Calling): Tools (Function Calling) | LangChain4j
- 更高层次的抽象 : AI Services | LangChain4j
- 支持检索增强生成技术 : https://docs.langchain4j.dev/tutorials/rag/
(二) LangChain4j语言大模型使用
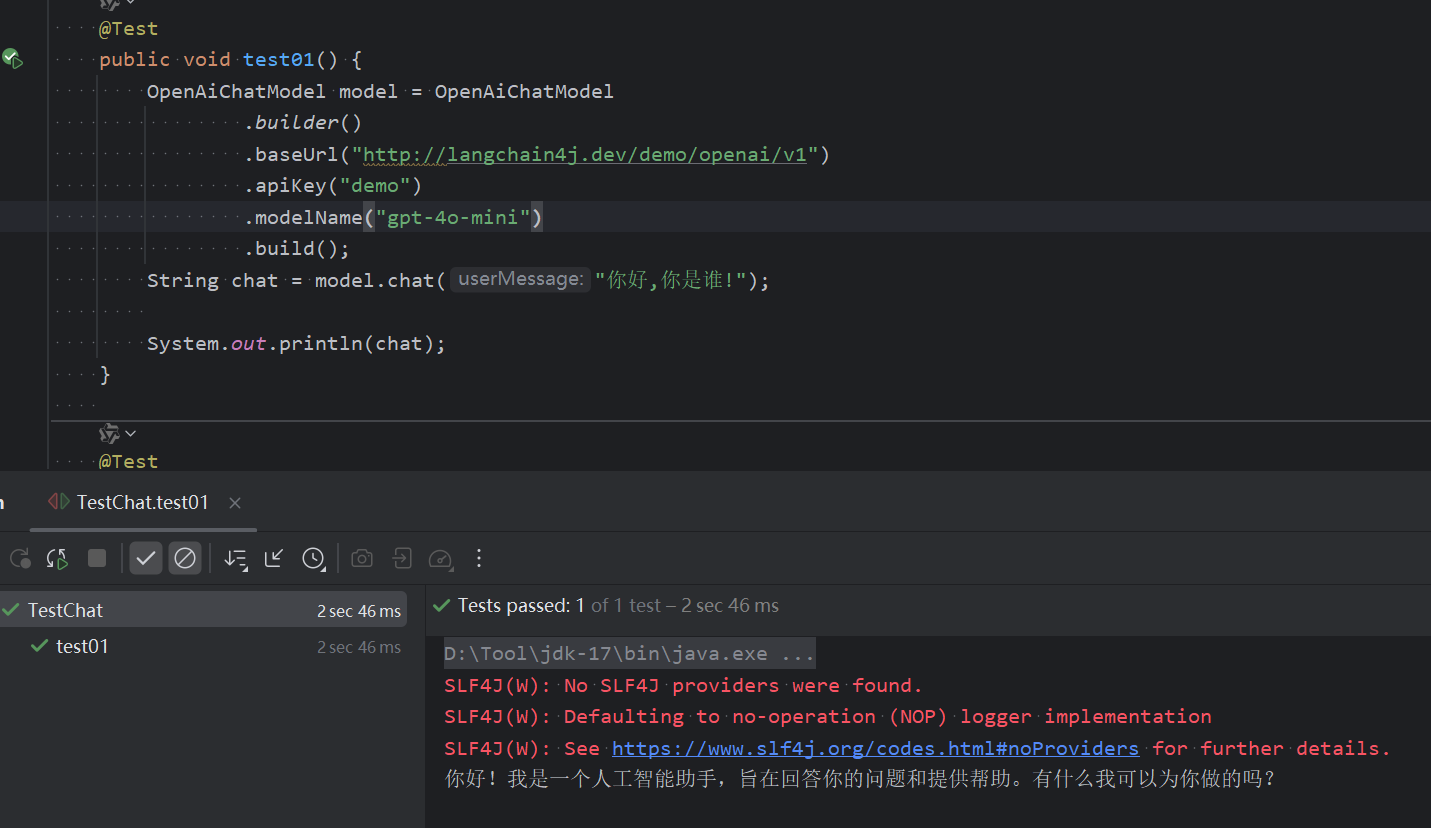
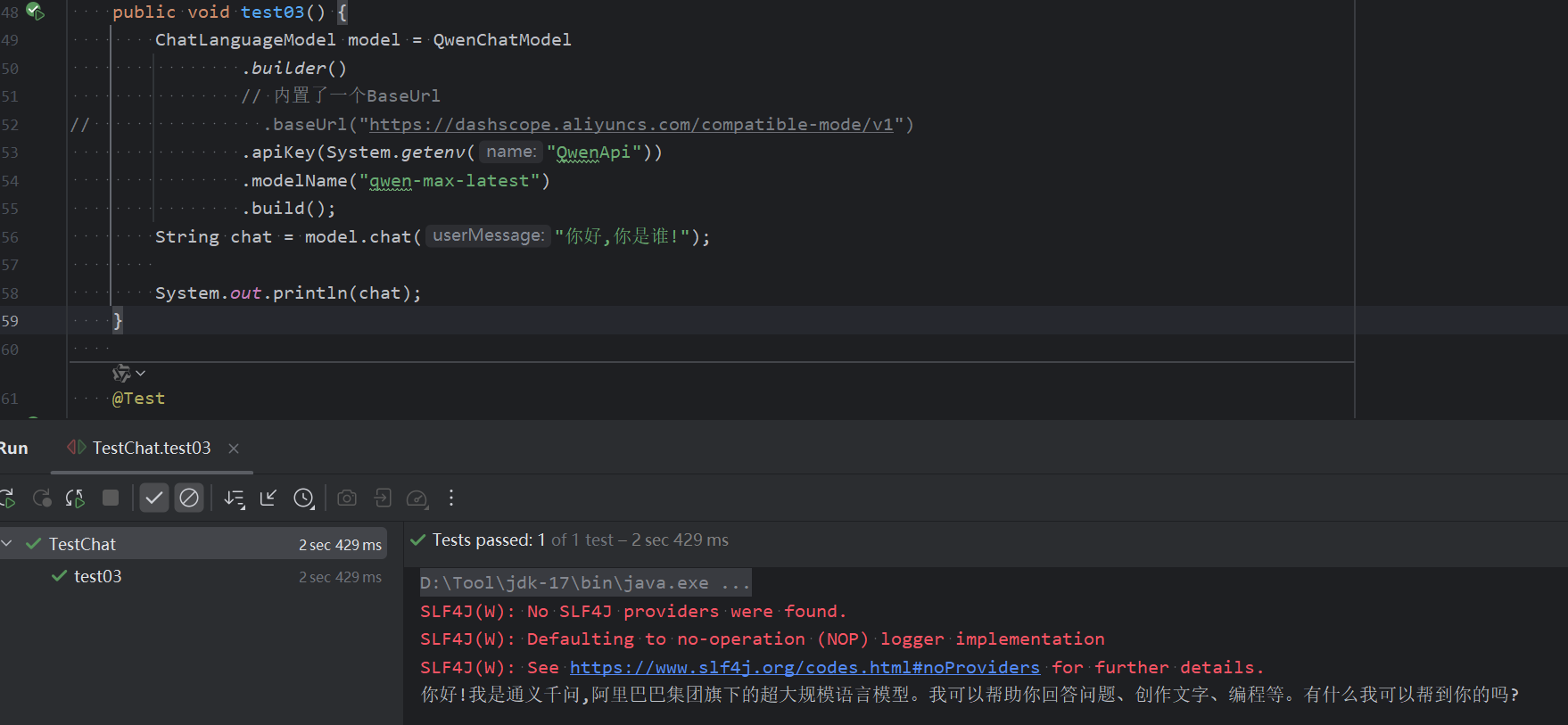
1. 支持openAI,DeepSeek,Qwen等,也支持本地模型的调用
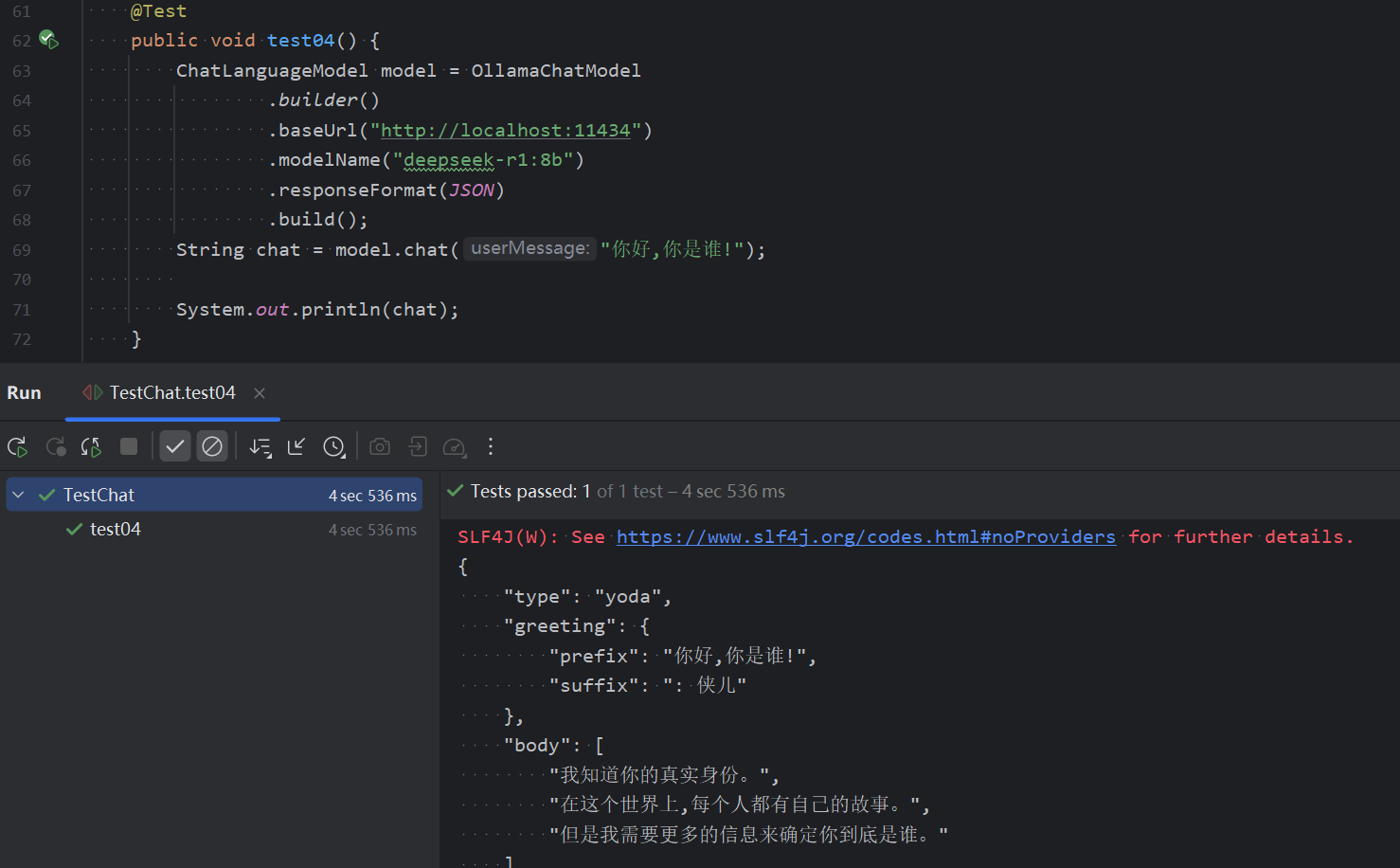
本地模型
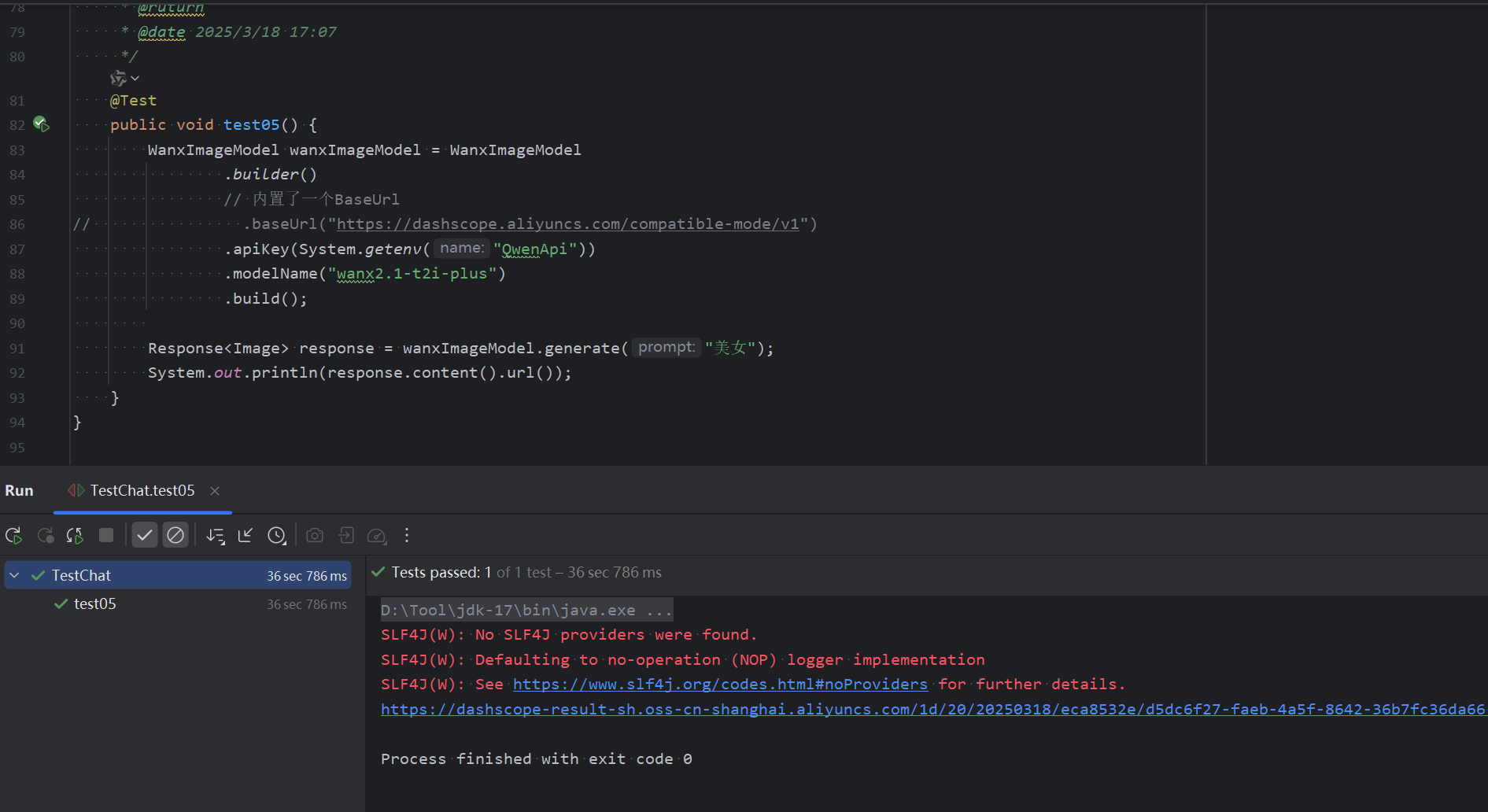
2. 图片大模型
https://dashscope-result-sh.oss-cn-shanghai.aliyuncs.com/1d/20/20250318/eca8532e/d5dc6f27-faeb-4a5f-8642-36b7fc36da66-1.png?Expires=1742375527&OSSAccessKeyId=LTAI5tQZd8AEcZX6KZV4G8qL&Signature=BmQFVVLlN1AqGIznRLJAlmSFa2c%3D(三) SpringBoot项目中使用LangChain4j
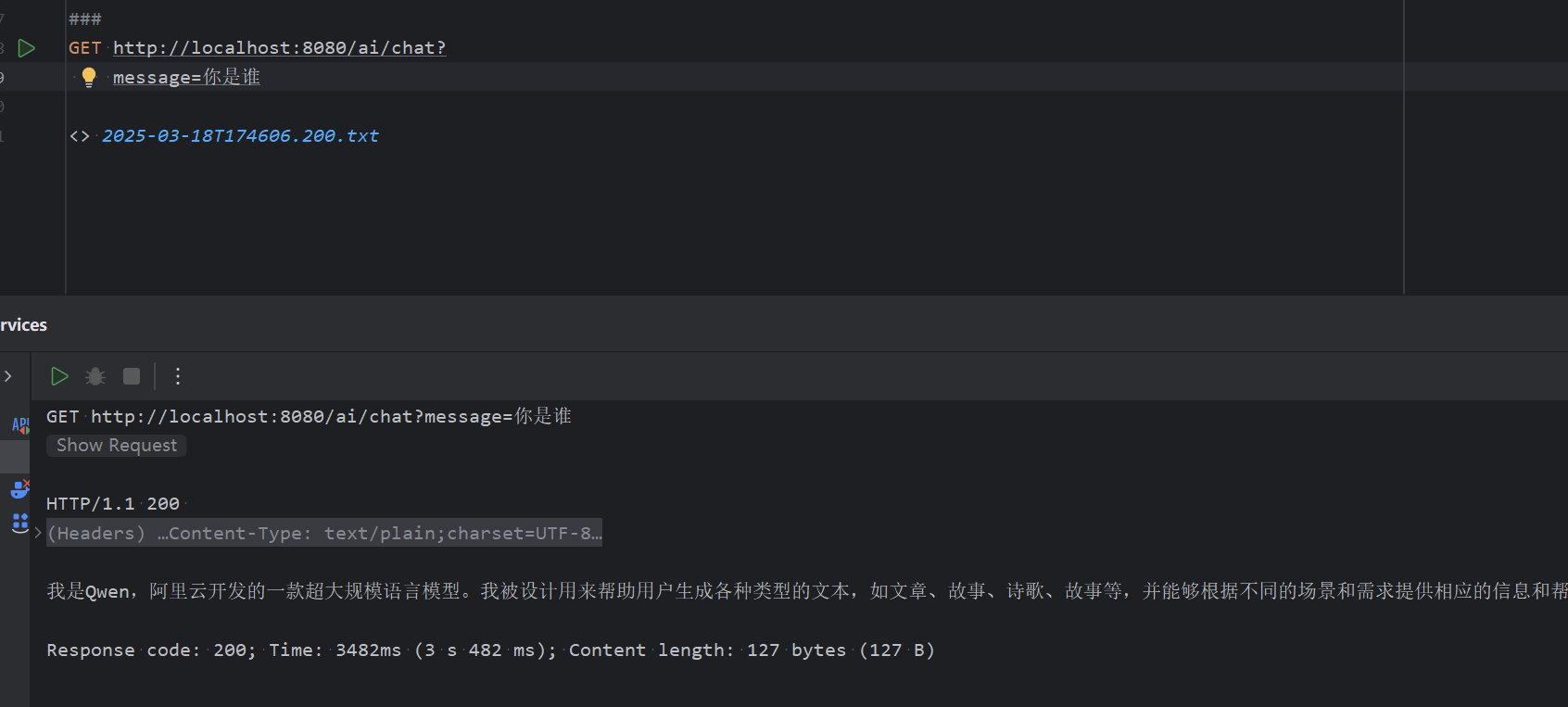
1. 普通的使用
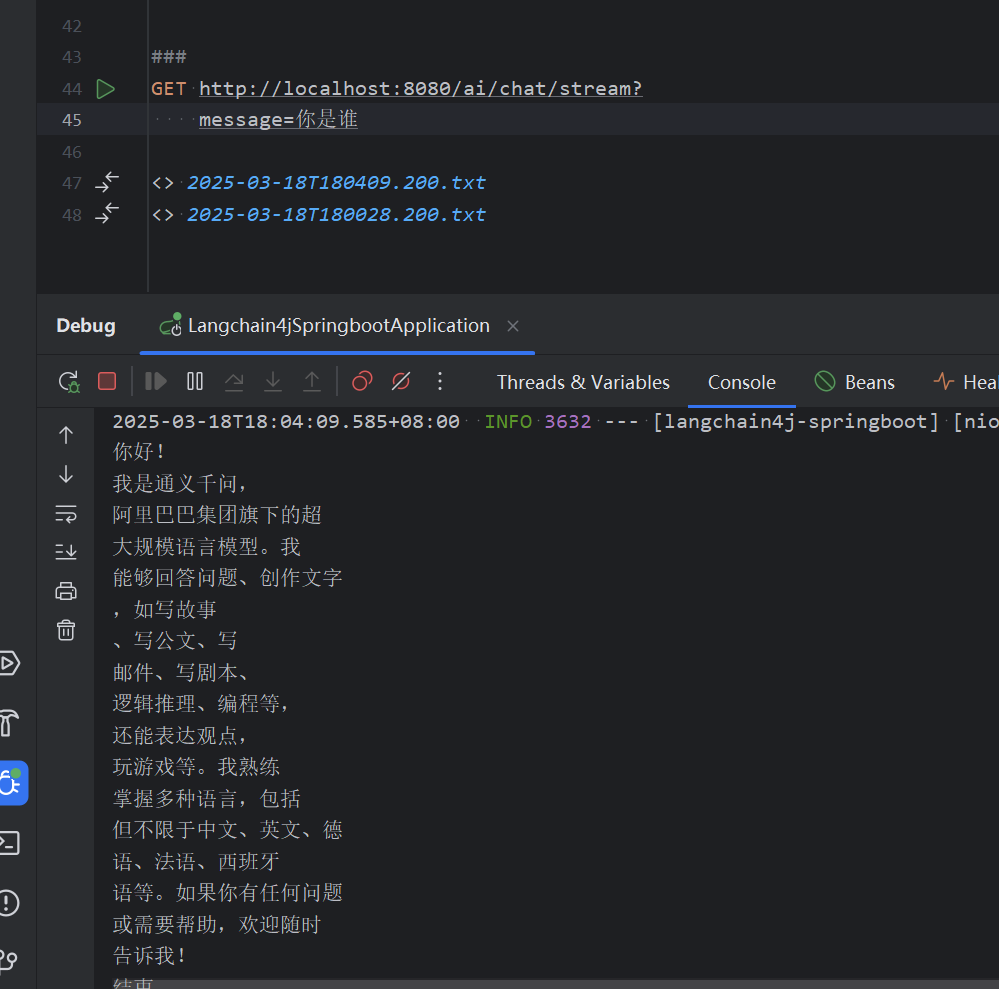
2. Stream流的使用
在页面上的直观感受是AI在进行思考般对话
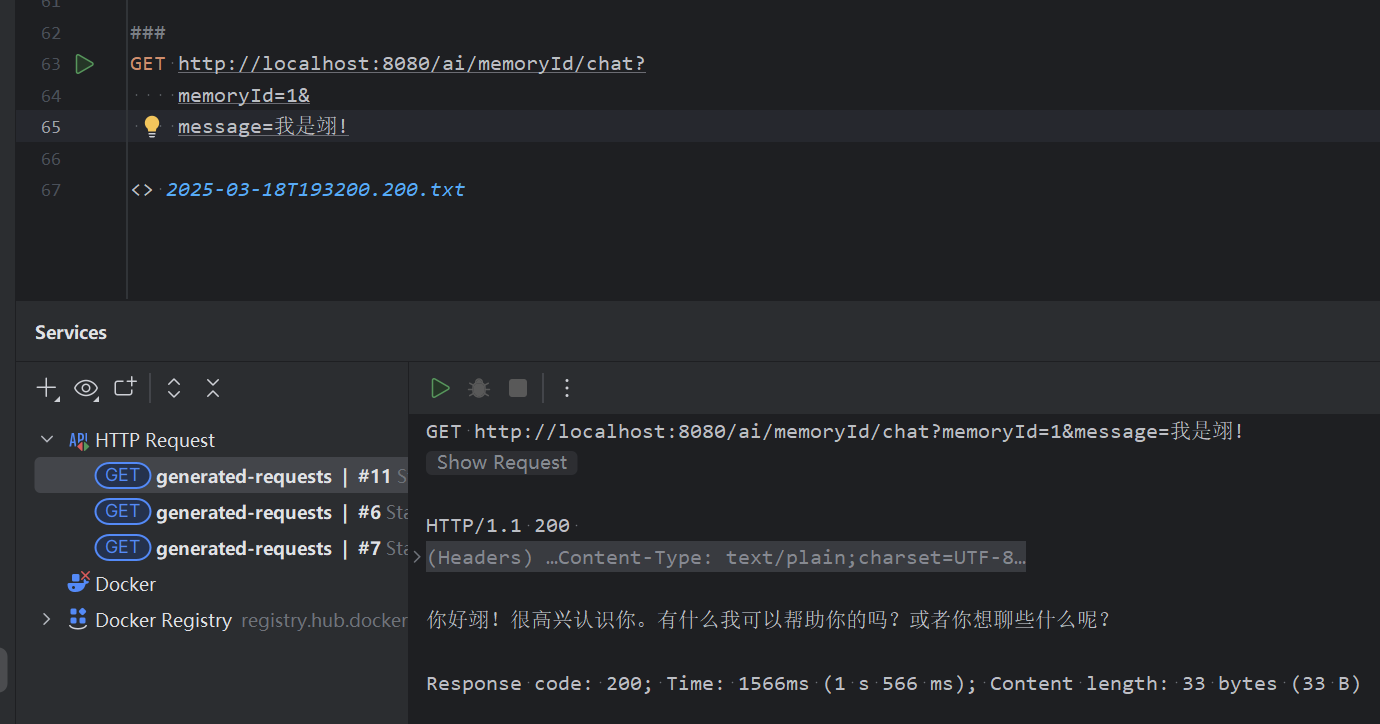
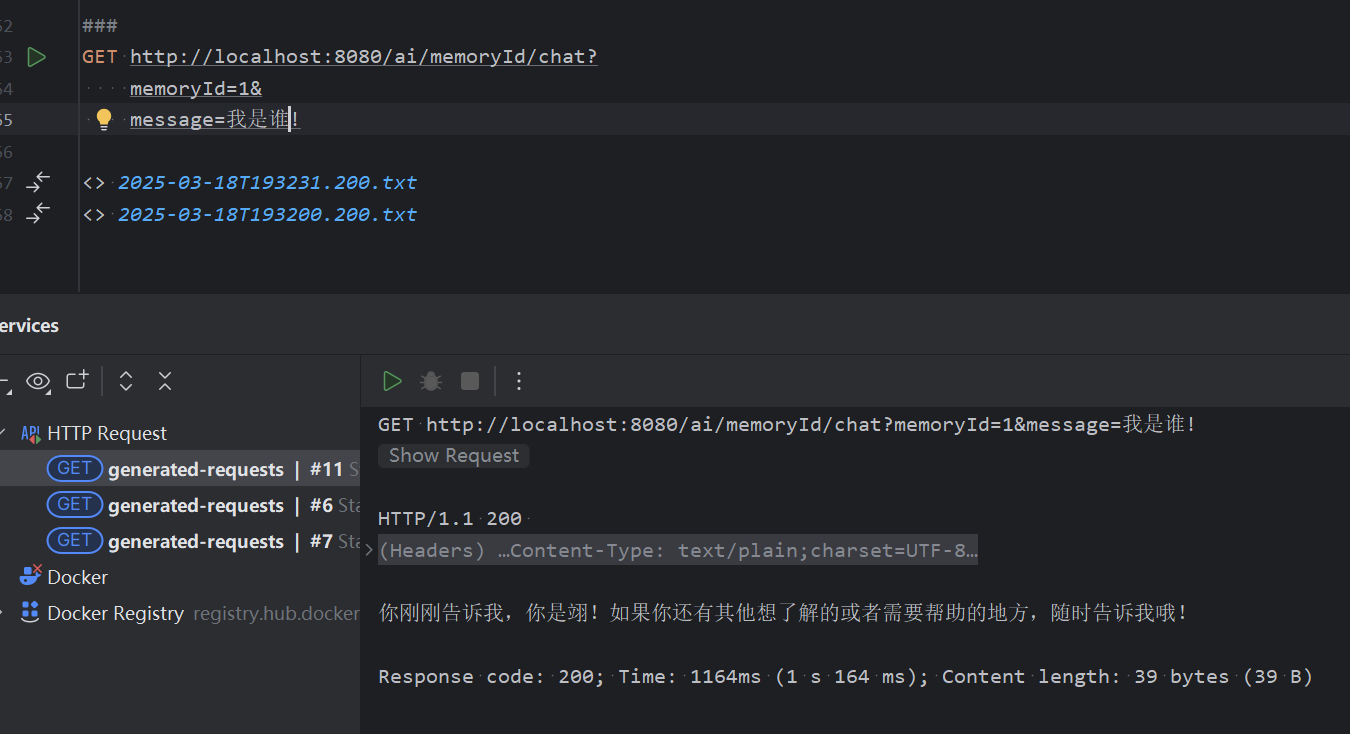
3. Chat Memory
普通对话不会保存上段对话的记忆

会话记忆保存
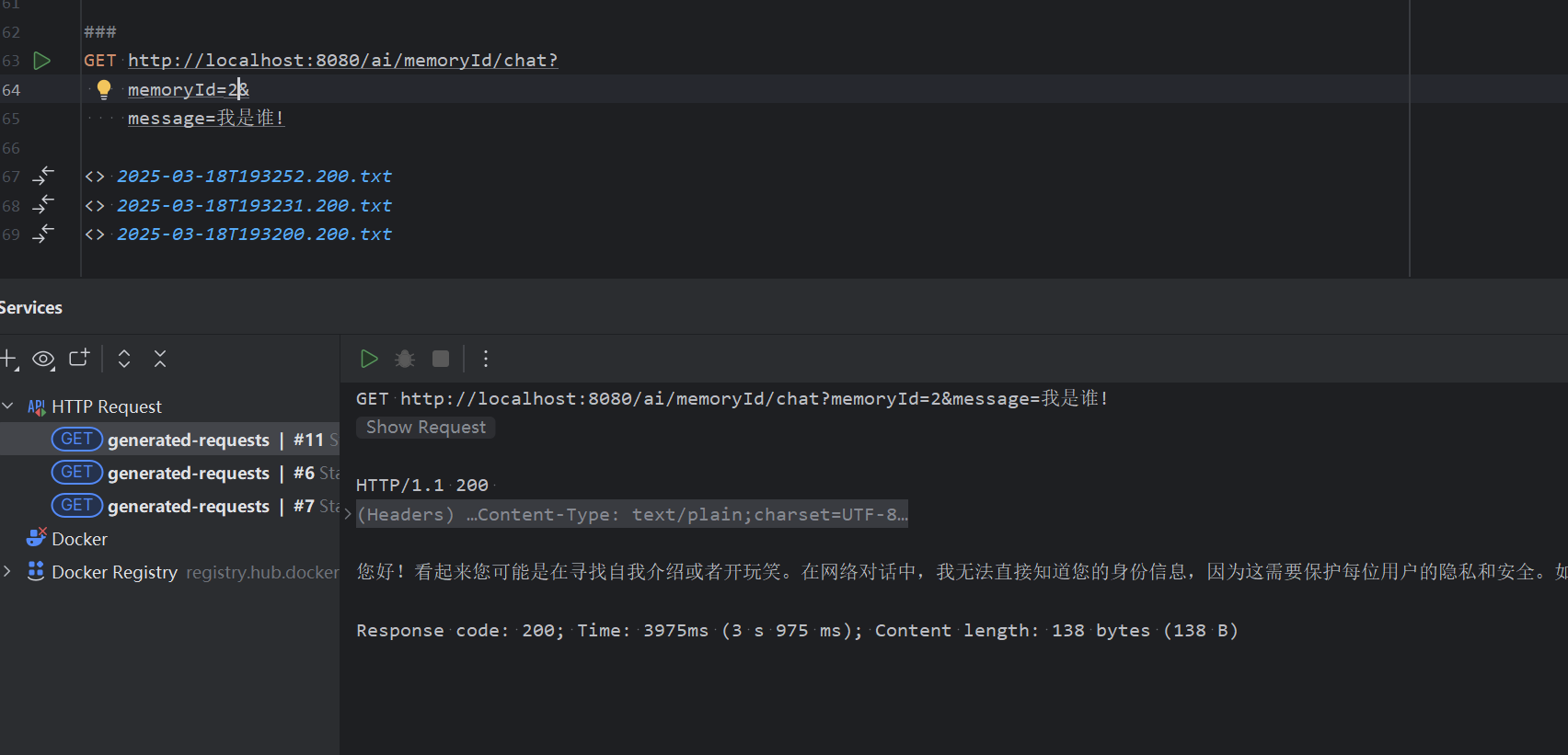
4. function-call
设置一个预设的场景"某个地区有多少个名字",当 对话中有触发的场景,走到方法中
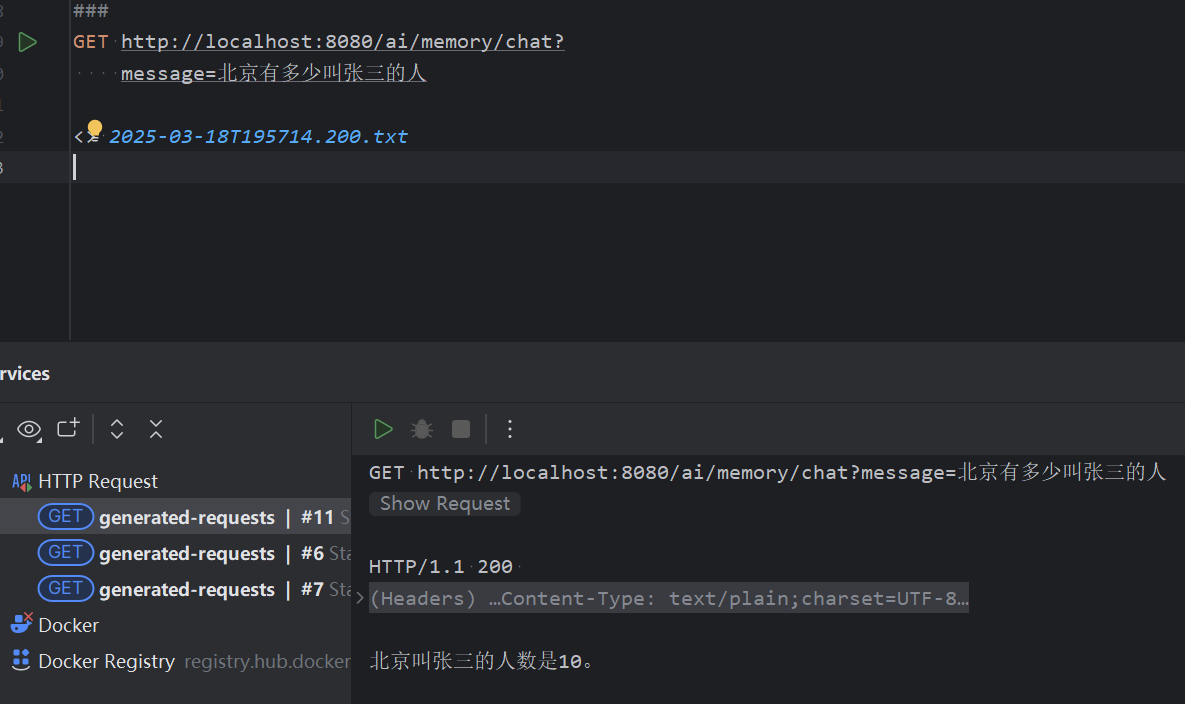
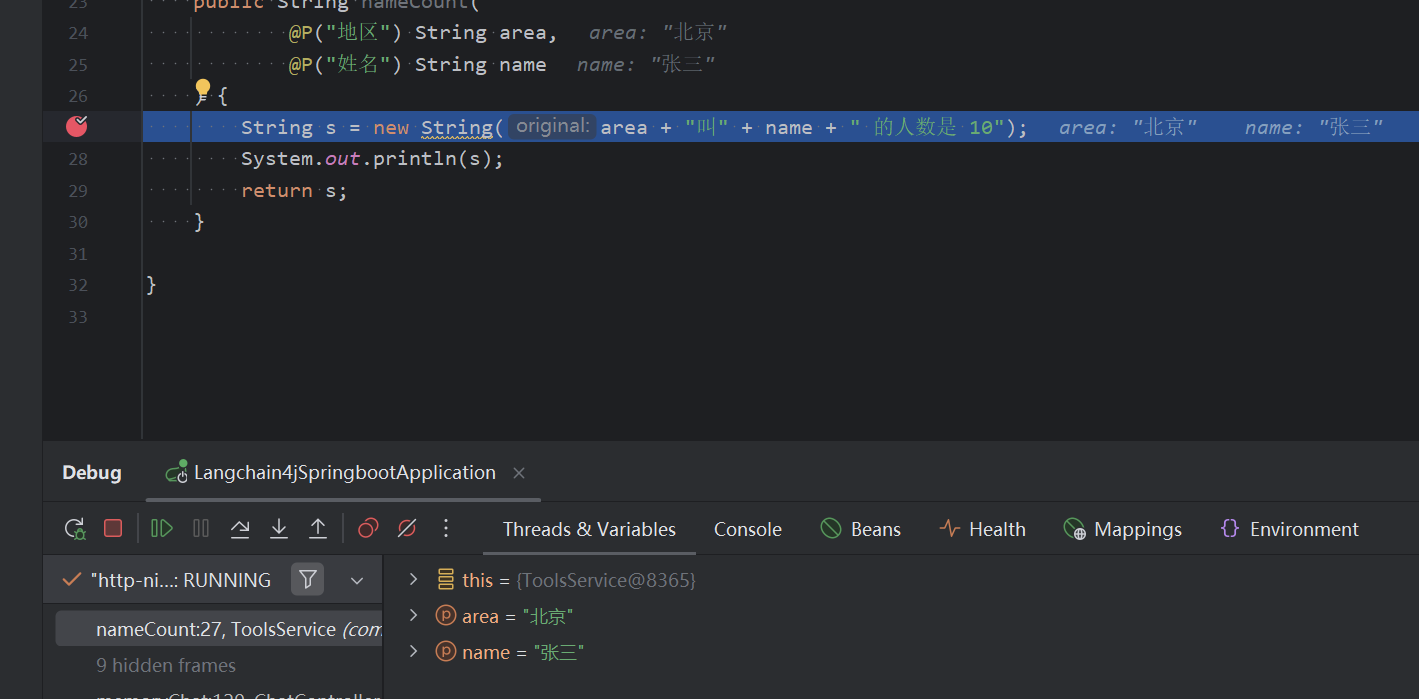
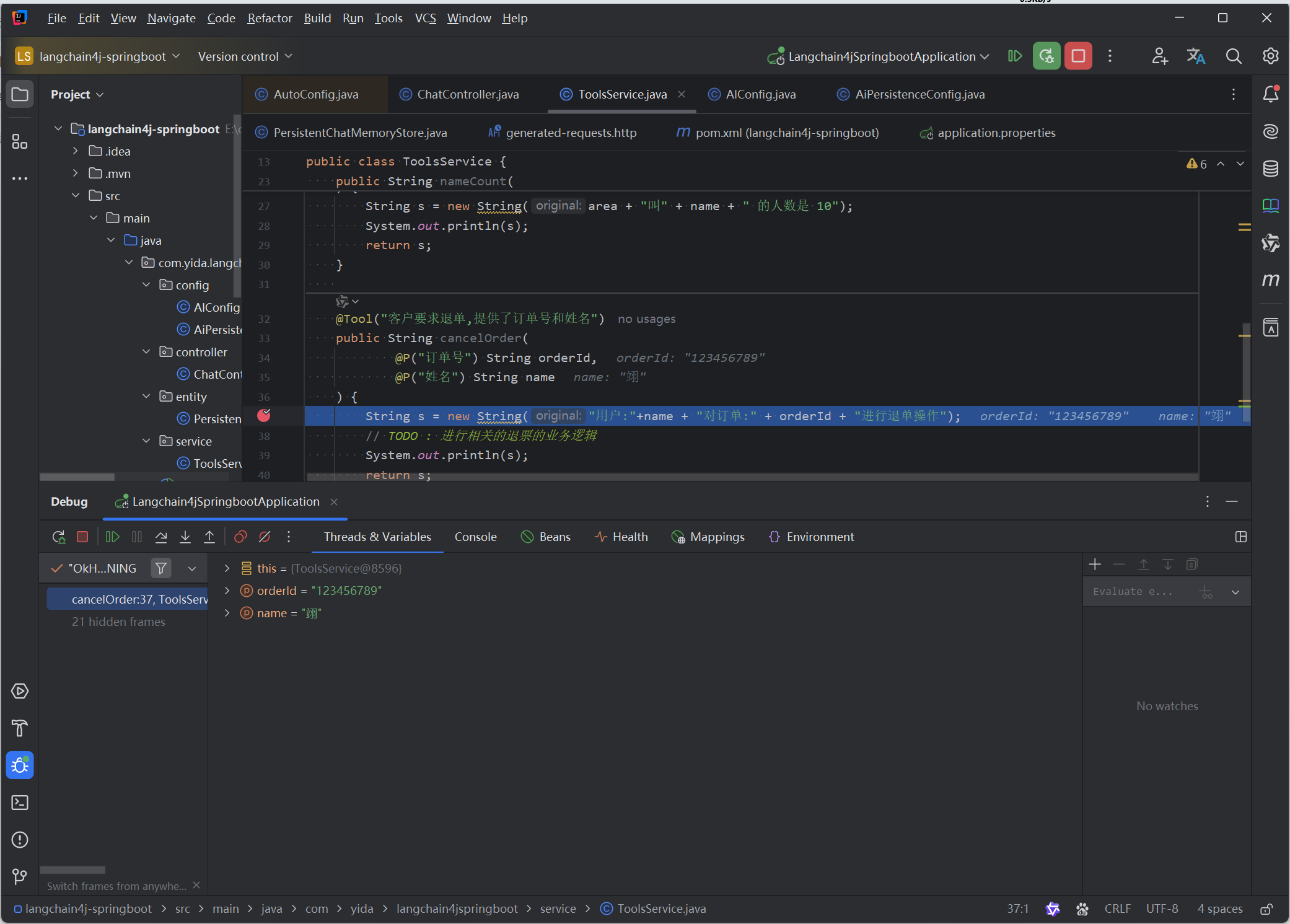
5. 更高层次的抽象
- 可以预设语言模型的信息,充当助手的功能

- 当配合上function-call 可以实现一定的业务逻辑处理


6. RAG
检索增强生成(Retrieval-augmented Generation)对于基础大模型来说,他只具备通用信息,他的参数都是拿公网进行训练,并且有一定的时间延迟,无法得知一些具体业务数据和实时数据,这些数据往往在各种文件中(比如txt、word、html、数据库)
虽然function-call、SystemMessage可以用来解决一部分问题但是它只能少量,如果你要提供大量的业务领域信息,就需要给他外接一个知识库:
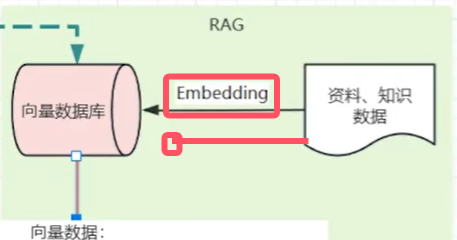
向量:向量通常用来做相似性搜索,比如语义的一维向量,可以表示词语或短语的语义相似性。例如,“你好”、"hello”和“见到你很高兴”可以通过一维向量来表示它们的语义接近程度。然而,对于更复杂的对象,比如小狗,无法仅通过一个维度来进行相似性搜索。这时,我们需要提取多个特征,如颜色、大小、品种等,将每个特征表示为向量的一个维度,从而形成一个多维向量。例如,一只棕色的小型泰迪犬可以表示为一个多维向量[棕色,小型,泰迪犬。如果需要检索见过更加精准,我们肯定还需要更多维度的向量,组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。我们需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。向量数据库会帮我实现。
文本向量化
- 文本向量化分为两个阶段
-
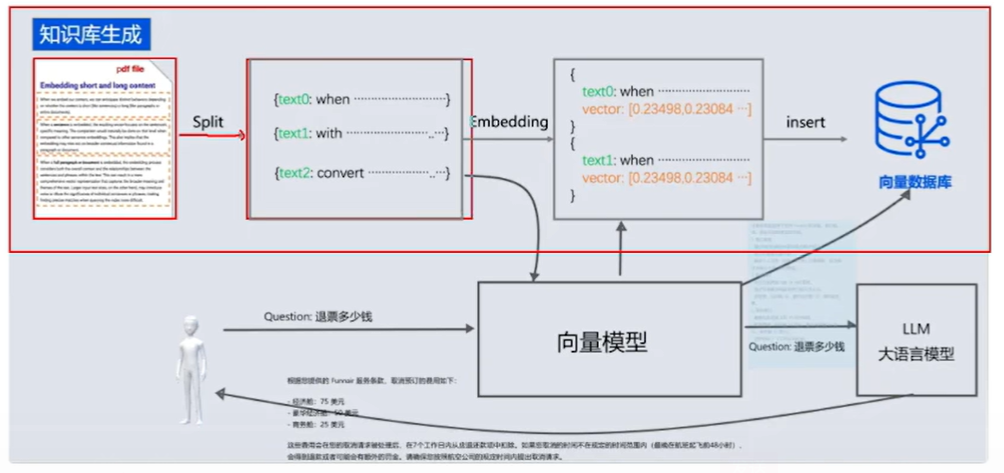
- 数据嵌入阶段:将 文本信息 -->调用向量模型(Embedding) --> 转换为向量数据-->将向量数据存放在向量数据库中
- 数据检索阶段: 数据准备好之后 -->在用户提出问题后(退单操作)--> 由向量模型将问题向量化后-->在从向量数据库中查询相似性的信息-->将相似性的信息结合用户提问信息一起发送给LLM(大语言模型)-->LLM结合对话信息和相似向量数据,返回给用户数据!
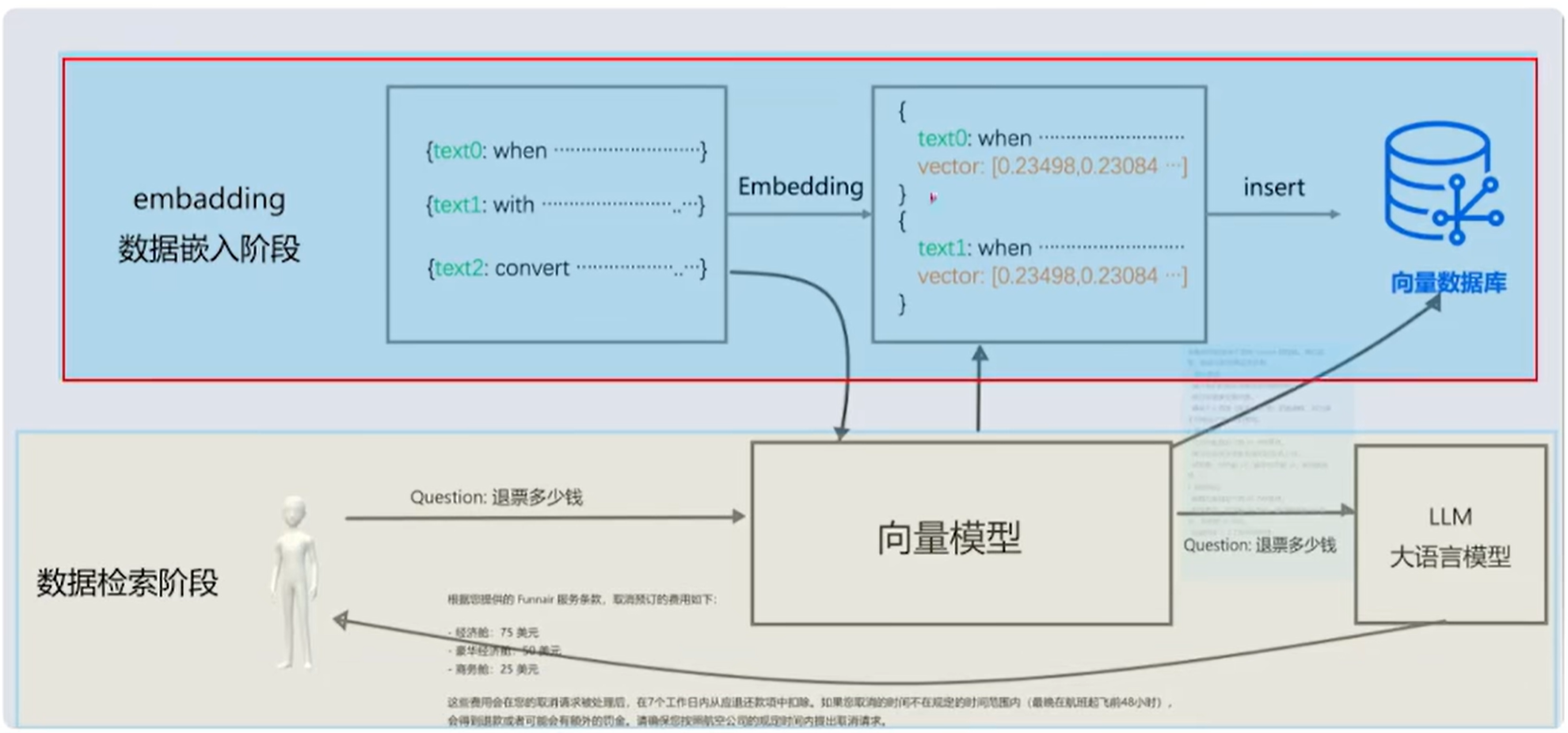
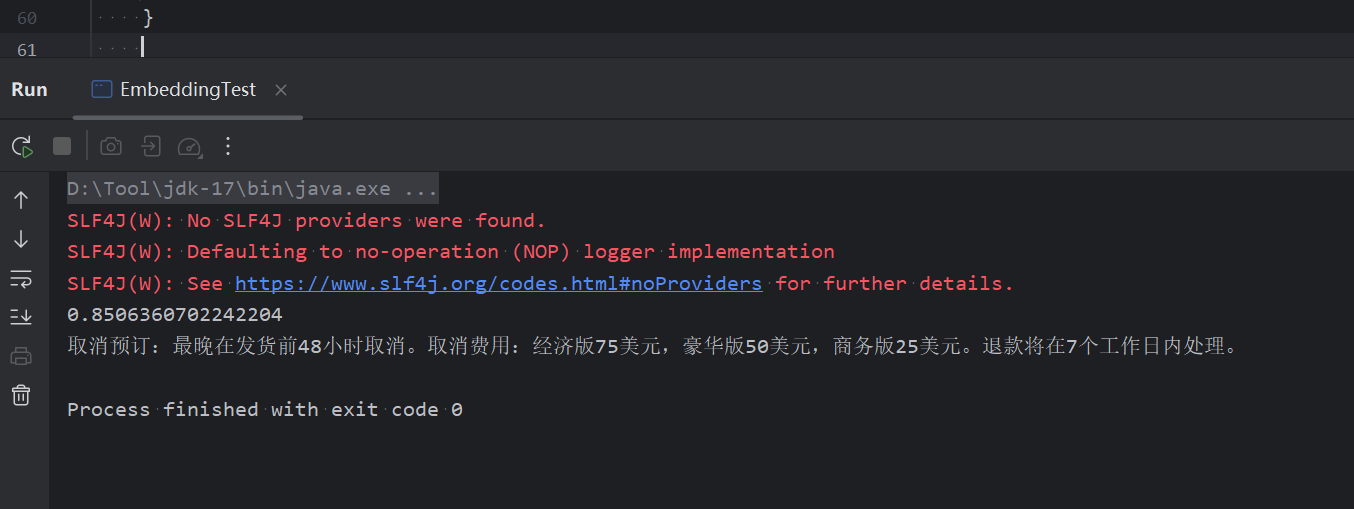
知识库RAG演练
- 两个阶段: 数据嵌入阶段,数据使用阶段
-
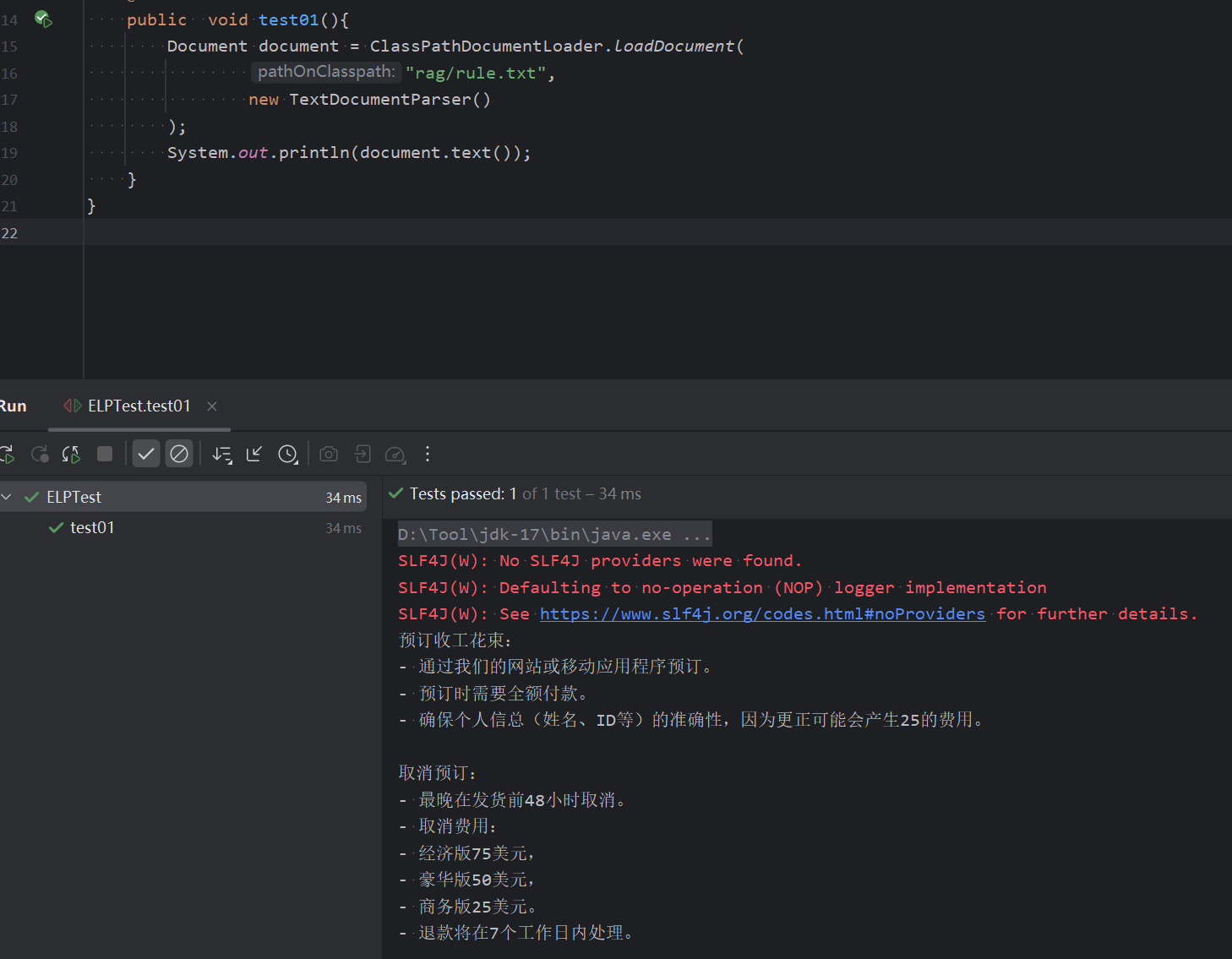
解析器
TextDocumentParser来自 langchain4j模块的TextDocumentParser,它可以解析纯文本格式(e.g.TXT、HTML、MD等)的文件。
ApachePdfBoxDocumentParser 来自 langchain4j-document-parser-apache-pdfbox,它可以解析PDF文件
ApachePoiDocumentParser 来自 langchain4j-document-parser-apache-poi,可以解析 MS Office文件格式(e.g.DOC、DOCX、PPT、PPTX、XLS、XLSX等)
ApacheTikaDocumentParser来自 langchain4j-document-parser-apache-tika模块中,可以自动检测和解析几乎所有现有的文件格式
FileSystemDocumentLoader 来自dev.langchain4j.data.document.loader.FileSystemDocumentLoader,可以自动检测和解析几乎所有现有的文件格式
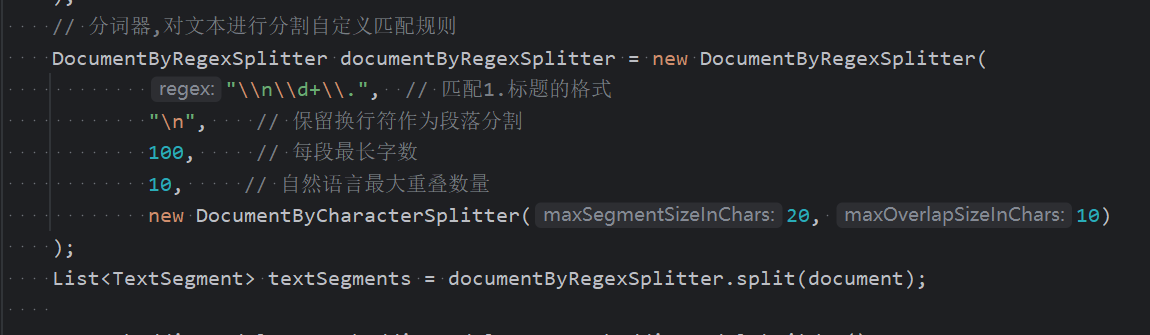
文本分割,对获取到的文本进行一定的分词处理
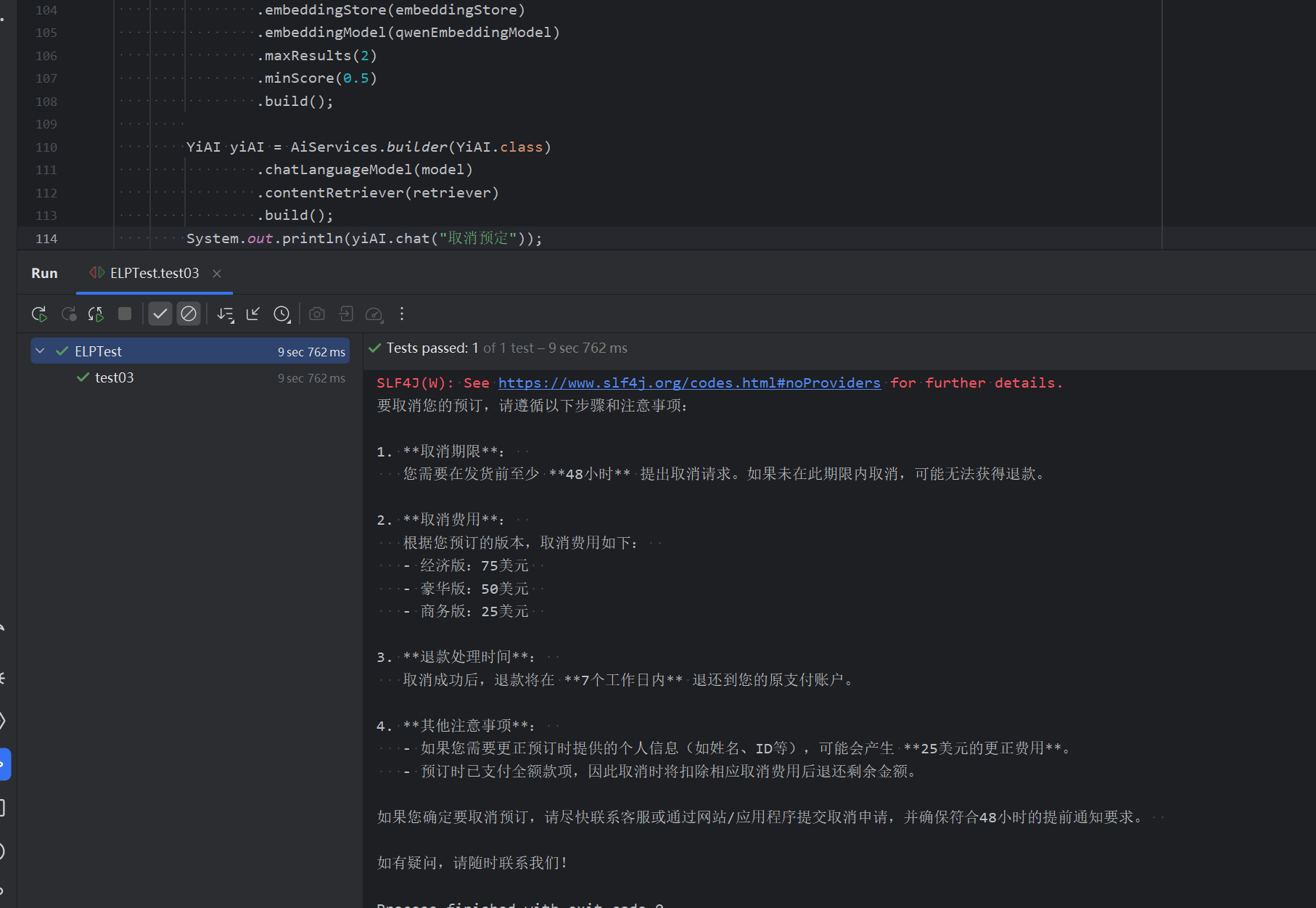
7. 检索增强阶段
当 RAG(本地知识库)中设置了某些信息的时候,在对话的时候出现一些词汇,会从本地知识库中进行检索
四、结尾
通过 LangChain4j的学习使用语言模型,加深了对于AI模型的了解,学习完成!

















 8318
8318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









