







朴素贝叶斯分类器
- 优势:以贝叶斯定理为基础,简单易懂,学习效率高
- 劣势:以各特征相互独立,连续变量的正态性假设为前提 ==》 算法精度会因此受到影响
- 先验概率
- 根据以往经验核分析得到的概率,如P(好瓜) = 60%
- 后验概率
- 事情已经发生,判断这件事由于某个原因引起的可能性大小,一定程度上类似于条件概率
- 如:P(纹理清晰|好瓜)
- 联合概率,由于贝叶斯分类器中默认各特征之间相互独立,因此p{X=i,Y=j}=pij
- 那么p{X=i,Y=j}=p{Y=y|X=i}p{X=i}=p{X=i|y=j}p{Y=j}
- 全概率公式
-
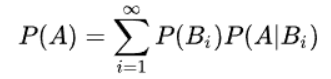
-
在P(A)计算比较困难的时候,用各种条件下A发生的概率之和来求
-
在这个问题上也就是,如果好瓜的概率比较难求的情况下,可以根据各特征下好瓜的概率之和来求好瓜
-
- 贝叶斯定理
-
在条件概率的基础上寻找事件发生的原因
-
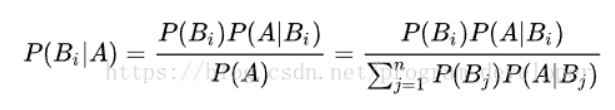
-
在这个问题上就是,条纹清晰中好瓜的概率 = 条纹清晰并且好瓜的概率 / 各种瓜的条纹清晰的概率之和
-
所有瓜条纹清晰的概率可以根据全概率公式转化为各种瓜条纹清晰的概率之和
-
条纹清晰并且好瓜的概率可以根据条件概率公式转化为好瓜的概率×好瓜中条纹清晰的概率
-
10.1 贝叶斯最优分类器
- 寻找一个判定准则h,最小化后验概率获得的分类产生的期望损失
- 也就是最小化分类错误率
10.2 朴素贝叶斯分类器
-
前提:各特征相互独立
-
由于贝叶斯定理中的分母部分为各特征概率之积,是相同的,因此只需要判断分子部分就可以了
-
而分子部分为各特征下好瓜的概率,由于各特征相互独立
- 因此等于好瓜的概率×各特征下好瓜概率之积 (用的是联合密度)
-
因此比较后验概率只需要比较分子部分即可,也只需要计算分子部分
-
举个例子:
-
好瓜的后验概率的分子部分

-
坏瓜的后验概率的分子部分

-
-
在比较下可以发现在这么多特征下好瓜的概率>坏瓜的概率,因此就可以预测在这些特征下的瓜为好瓜
10.2.1 拉普拉斯修正
- 为了避免条件概率由于某一个属性值没有出现过而被计算为0,即p(x|yi)=0,也就是条纹清晰的前提下没有好瓜
- 拉普拉斯修正就是为每一个类别下的符合条件的西瓜数+1
- 那么分母的变化也是一样的,还是不用管分母,只管比分子就行了
10.3 半朴素贝叶斯分类器
- 由于所有特征相互独立几乎是不可能存在的,但是如果考虑特征之间的相关性就会让计算极其复杂
- 半朴素就是让一部分特征独立,但是另一部分特征之间存在依赖关系
- 独依赖估计:每个特征最多依赖一个特征
- 被依赖的特征就是依赖特征的父属性
10.3.1 超父与TAN
-
超父
- 所有特征都依赖于一个特征,这个特征就被称为超父属性
-
TAN树
-
在最大带权生成树算法下生成的树形结构
-
步骤
-
计算两个属性值之间条件的互信息值
- 互信息值就是一个信息量里面包含另一个随机变量的信息量
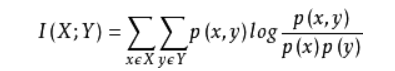
-
以属性为结点构建完全图,结点间的权重就是互信息值
-
挑选根变量,将边置为有向边
-
-
只保留了强相关属性之间的依赖
-
-
AODE算法
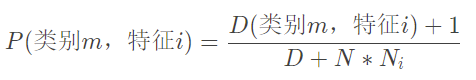
10.4 学习过程
- 找到最恰当的贝叶斯网(信念网)
-
就是找到最恰当的特征之间的依赖关系
-
贝叶斯网组成部分
- 一个有向无环图,表示变量之间的依赖关系
- 一个概率表,表示各结点与父节点之间的依赖关系
-
先定义一个评分函数对贝叶斯网与训练数据做评价,然后基于评分函数来寻找结构最优贝叶斯网
-
每个贝叶斯网描述了一个正在训练数据集上的概率分布,需要找到那个综合编码长度最小的贝叶斯网,即符合"最小描述长度"准则
-
评分函数:
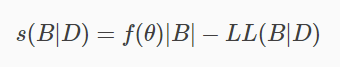
- |B|是指贝叶斯网的参数个数
- LL是对B的对数似然
- 因此第一项就是计算贝叶斯网B所需的字节数,第二项是计算B所对应的概率分布PB需要多少个字节来描述D

-
在有了评分函数之后,就转化为了优化任务,即找到一个贝叶斯网使得评分函数最小
- 贪心算法
- 结构约束消减搜索空间
-
推断
- 吉布斯采样算法
- 先随机产生一个与证据一致的样本作为初始点,然后每步从当前样本出发产生下一个样本。
- 实际上是在贝叶斯网所有变量联合状态空间与证据一致的子空间中进行“随机漫步”,每一步仅仅依赖前一步的状态,是一个马尔科夫链。
- 但是马尔科夫链很长时间才能趋于平稳,因此收敛速度较慢。
- 此外若贝叶斯网中存在极端概率0或1,将不能保证马尔科夫链存在平稳分布,此时吉布斯采样会给出错误的估计结果
- 吉布斯采样算法
-
10.5 EM算法
- 应对不完整的训练样本
- 参数:
- X :已观测变量集
- Z :隐变量集(未观测变量集)
- Θ :模型参数
- 需要做的就是对Θ做最大似然估计
- 若参数Θ已知,可以根据训练数据推断出最优隐变量的值(E步)
- 如果Z已知,可以对Θ进行极大似然估计(M步)
- 具体步骤:
- 初始化Θ,基于Θ推断隐变量Z的期望Zt
- 基于X和Zt对参数Θ做最大似然估计
- 基于最大似然估计计算隐变量Z的概率分布
- E步:以当前Θ推断隐变量分布P(Z|X,Θ),并计算对数似然LL(Θ|X,Z)关于Z的期望
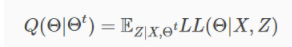



















 7863
7863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











