






 本文介绍了图像生成的不同模型,如VAE、Flow-based模型、Diffusion模型和GAN,着重讲解了Diffusion模型的denoising过程和StableDiffusion的进步。讨论了文本到图像生成中的编码器影响,以及CLIP在预训练中的应用。FID作为评估指标,强调生成质量的重要性。
本文介绍了图像生成的不同模型,如VAE、Flow-based模型、Diffusion模型和GAN,着重讲解了Diffusion模型的denoising过程和StableDiffusion的进步。讨论了文本到图像生成中的编码器影响,以及CLIP在预训练中的应用。FID作为评估指标,强调生成质量的重要性。
图像生成模型
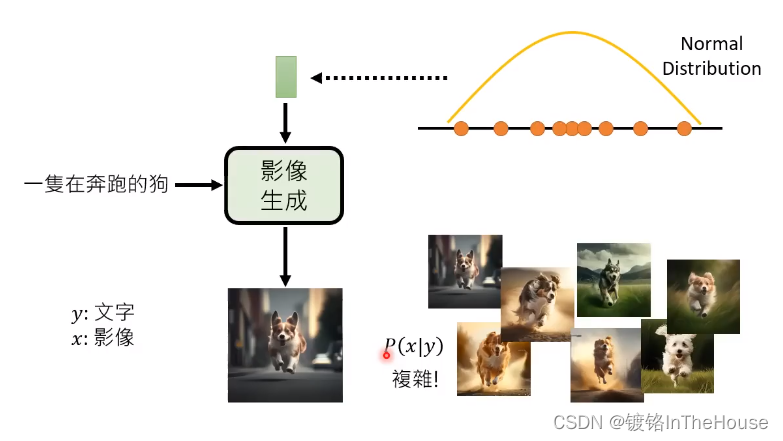
文字生成多采取Autoregressive(各个击破),影像生成似乎可以同理,逐个生成像素颜色的几率,但太耗费时间了,所以多采取一次到位。
输入高维的分布生成高维的向量加上输入的文字。
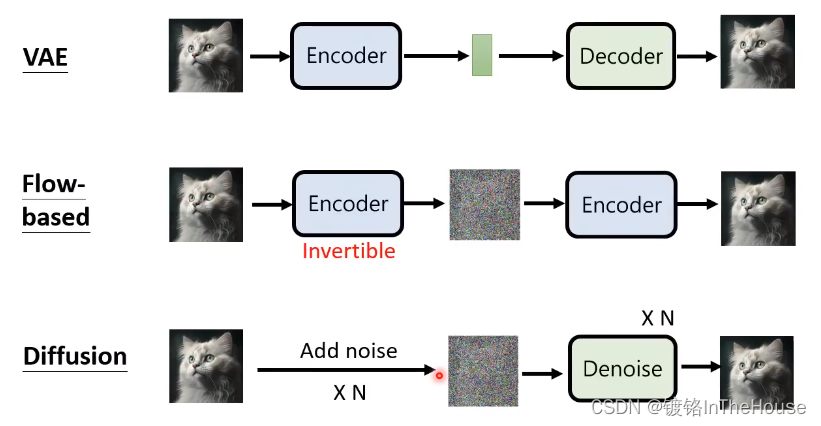
- VAE:用decoder获得向量对应输出,encoder可以把图像对应给向量。
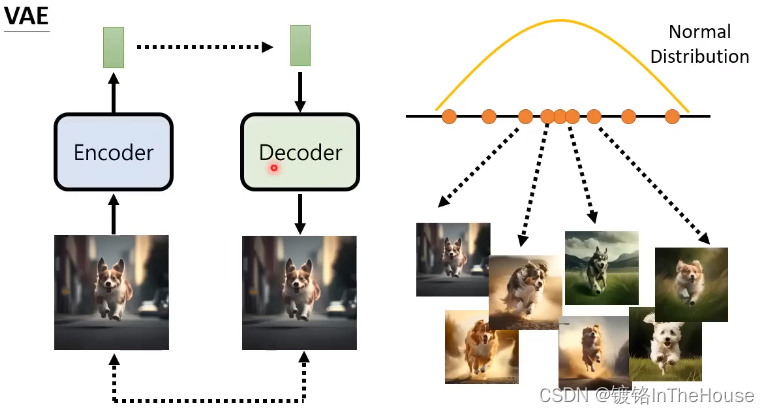
- Flow-based model:吃一张图片输出的向量正态分布,且强迫encoder是可逆的,从而输出图片,所以向量和图像大小是一样的。
- Diffusion model:图像add noise再denoise。
- GAN:训练discriminator,分辨真实图片和生成的图片,如果discriminator has poor performance,那么decoder的功能就更好。
简略介绍Diffusion Model
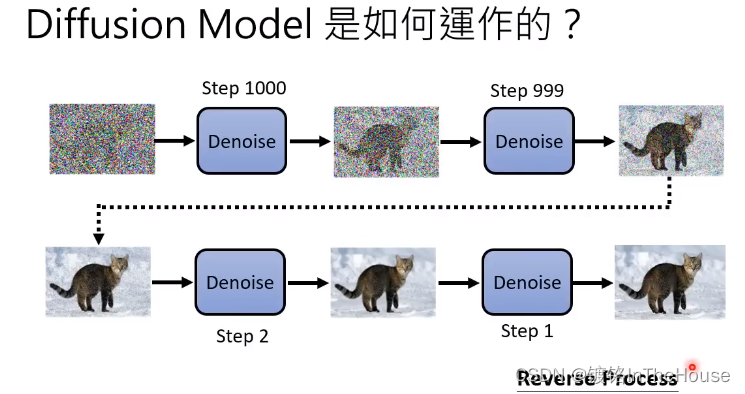
同一个denoise model反复使用效果一般,所以denoise输入有图像以及step数。
- noise predicter:预测这张图片中的噪音图
- 再减掉噪音,输出结果。
- 产生噪音图和结果图困难程度不同。
如何训练noise predictor?
- 训练资料由人创造,forward process(diffusion process)
text-to-image
- noise predicter 多一个文字的输入。
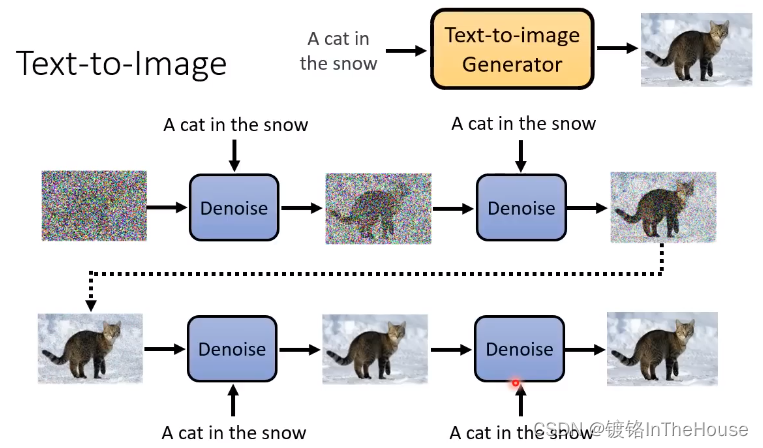
Stable Diffusion
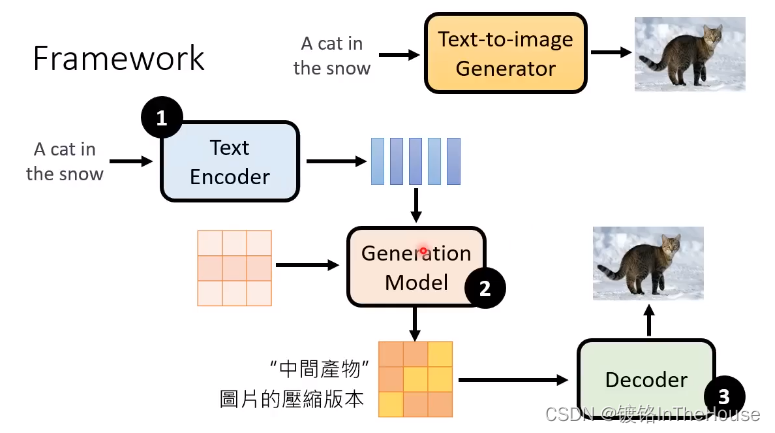
text encoder:
- impact of encoder size:越大越好
- impact of U-Net size:noise predictor的大小,作用有限。
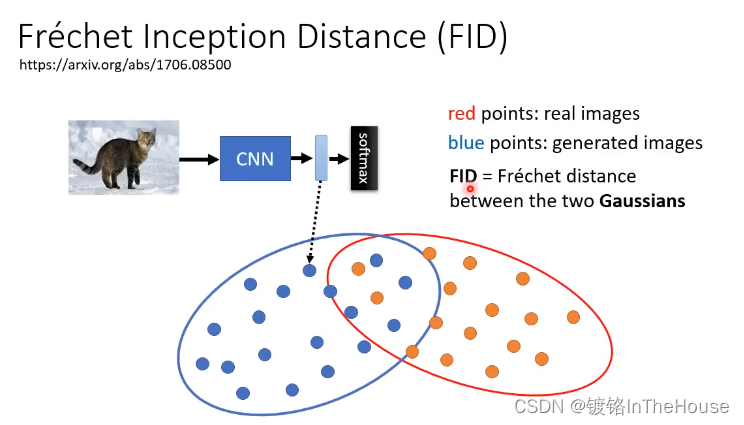
FID :Frechet inception distance,越小越好。
CLIP:contrastive language-image pre-training
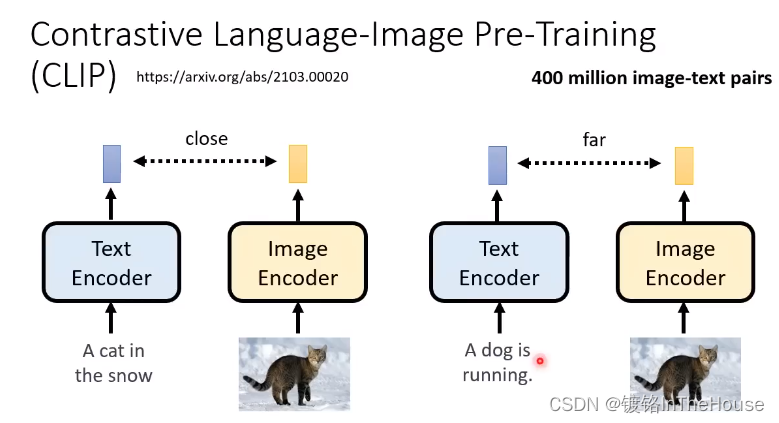
同样的距离近,不同的距离远。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









