




1.安装包并运行
install.packages("xgboost")
require(xgboost)2.导入数据
set.seed(2021)seed:随机种子,用于产生可复现的结果
data("agaricus.train",package="xgboost")
data("agaricus.test",package="xgboost")
train <- agaricus.train
test <-agaricus.test
这份数据需要我们通过一些蘑菇的若干属性判断这个品种是否有毒。数据以 1 或 0 来标记某个属性存在与否。
class(train$data)可以看到样例数据为稀疏矩阵类型

如果数据不是稀疏矩阵类型,则需要进行预处理。
3.数据预处理
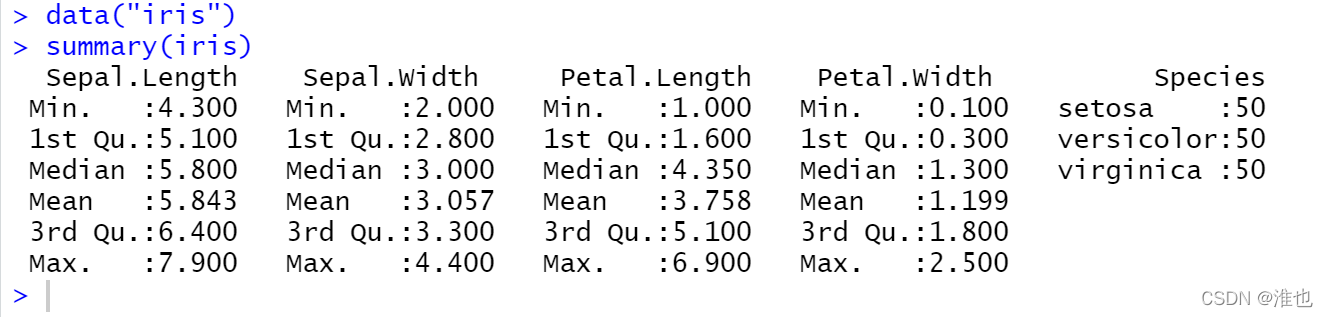
这部分以iris为例
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3107
3107






 到【灌水乐园】发言
到【灌水乐园】发言







