







 本文介绍了线性判别分析(LDA)的基本原理、优缺点和算法流程,并阐述了支持向量机(SVM)的简介和应用,包括在月亮数据集和鸢尾花数据集上的实践。
本文介绍了线性判别分析(LDA)的基本原理、优缺点和算法流程,并阐述了支持向量机(SVM)的简介和应用,包括在月亮数据集和鸢尾花数据集上的实践。
一、线性判别分析(LDA)简述
1.简介
线性判别分析(linear discriminant analysis,LDA)是对费舍尔的线性鉴别方法的归纳,这种方法使用统计学,模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们。所得的组合可用来作为一个线性分类器,或者,更常见的是,为后续的分类做降维处理。
2.基本原理
给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点中心尽可能远离。更简单的概括为一句话,就是“投影后类内方差最小,类间方差最大”。
3.优缺点
LDA算法的主要优点有:
①在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
②LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点有:
①LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
②LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
③LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
④LDA可能过度拟合数据。
4.算法流程
输入:数据集 D = {(x1, y1), (x1, y1), … ,(xm, ym)},任意样本xi为n维向量,yi∈{C1, C2, … , Ck},共k个类别。现在要将其降维到d维;
输出:降维后的数据集D’。
(1)计算类间散度矩阵 SB;
(2)计算类内散度矩阵 SW;
(3)将 SB 和 SW 代入上面公式计算得到特征值 λ 和特征向量 w,取前面几个最大的特征值向量λ’与特征向量相乘得到降维转换矩阵 λ’w;
(4)将原来的数据与转换矩阵相乘得到降维后的数据 (λ’w)Tx ;
参考:https://www.jianshu.com/p/13ec606fdd5f
二、支持向量机(SVM)简述
1、简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
2、算法原理
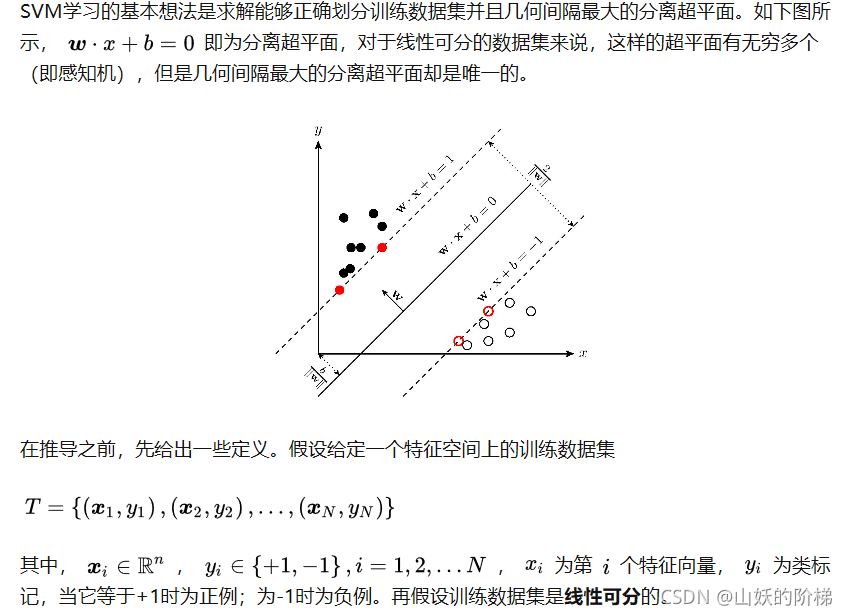











三、应用
1、LDA
(1)导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#计算均值,要求输入数据为numpy的矩阵格式,行表示样本数,列表示特征
def meanX(data):
return np.mean(data, axis=0) #axis=0表示按照列来求均值,如果输入list,则axis=1
(2)算法实现
#计算类内离散度矩阵子项si
def compute_si(xi):
n = xi.shape[0]
ui = meanX(xi)
si = 0
for i in range(0, n):
si = si + ( xi[i, :] - ui).T * (xi[i, :] - ui )
return si
#计算类间离散度矩阵Sb
def compute_Sb(x1, x2):
dataX=np.vstack((x1,x2))#合并样本
print ("dataX:", dataX)
#计算均值
u1=meanX(x1)
u2=meanX(x2)
u=meanX(dataX) #所有样本的均值
Sb = (u-u1).T * (u-u1) + (u-u2).T * (u-u2)
return Sb
def LDA(x1, x2):
#计算类内离散度矩阵Sw
s1 = compute_si(x1)
s2 = compute_si(x2)
#Sw=(n1*s1+n2*s2)/(n1+n2)
Sw = s1 + s2
#计算类间离散度矩阵Sb
#Sb=(n1*(m-m1).T*(m-m1)+n2*(m-m2).T*(m-m2))/(n1+n2)
Sb = compute_Sb(x1, x2)
#求最大特征值对应的特征向量
eig_value, vec = np.linalg.eig(np.mat(Sw).I*Sb) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2863
2863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









