







刘二大人《PyTorch深度学习实践》p7处理多维特征的输入
一、零碎知识点
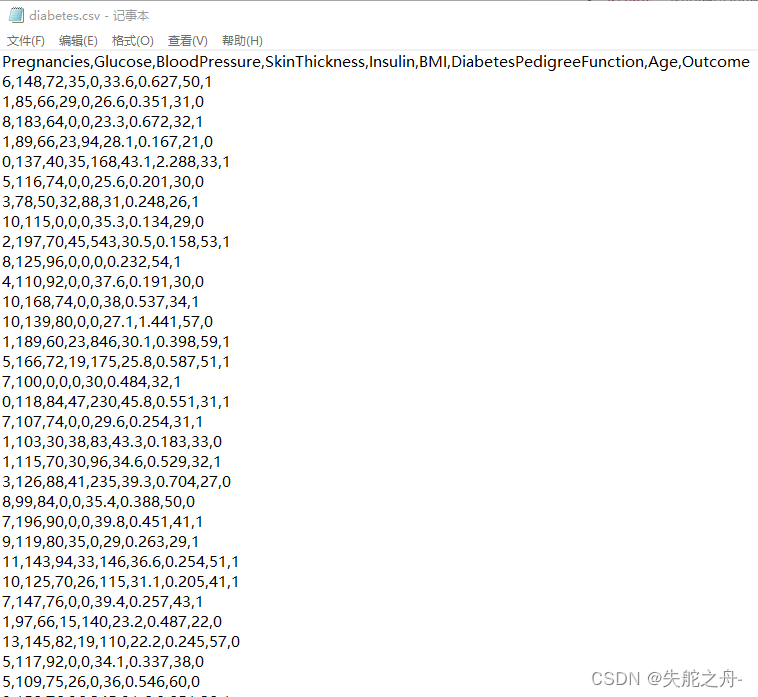
1.糖尿病数据集

每一行称为一个样本sample
每一列称为一个特征feature
Y表示一年后病人的病情是否会加重
2.np.loadtxt
np.loadtxt是NumPy库中的一个函数,用于从文本文件中加载数据,并将其转化为NumPy数组的形式。
np.loadtxt函数的基本语法如下:
np.loadtxt(fname, dtype=float, delimiter=None)
fname:要加载数据的文件路径(包含文件名)或文件对象。dtype:返回数组的数据类型,默认为浮点型。delimiter:分隔符,默认为任意空白字符。
举个栗子:
xy = np.loadtxt('diabetes.csv',delimiter=',',dtype=np.float32)
加载糖尿病数据集的数据,分隔符为逗号,,返回数组的类型为32位的浮点数
3.torch.from_numpy
torch.from_numpy是PyTorch中的一个函数,用于将NumPy数组转换为对应的PyTorch张量tensor。
举个栗子:
x_data是数据的前8个特征的所有值,y_data是每一个样本输出的预测结果
x_data = torch.from_numpy(xy[:,:-1]) #行取所有行,列取第一列到倒数第二列(最后一列是y的数据,所以舍去)
y_data = torch.from_numpy(xy[:,[-1]]) #行取所有行,列只取最后一列
4.过拟合
机器学习的学习能力并不是越强越好,它可能会过度关注训练数据中的细节和噪声,而无法捕捉到普遍的模式和规律,训练集里面的噪声和真实应用场景的噪声不是一样的。
学习能力要具有泛化能力,不仅仅是机器学习,我们也是。
二、课程代码
我觉得这节的理论学习注重的是线性代数的矩阵变化。

import torch
import numpy as np
import matplotlib.pyplot as plt
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
losses=[]
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(range(100), losses)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.show()
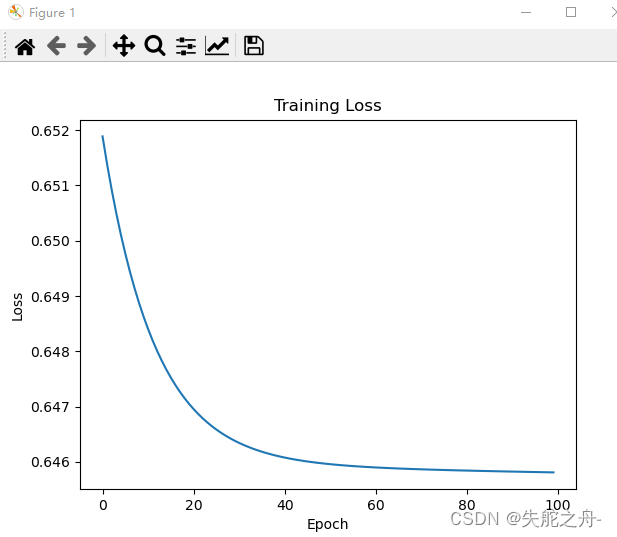
随着训练次数的增加,损失值逐渐降低,拟合程度呈现较好的趋势。


















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











