







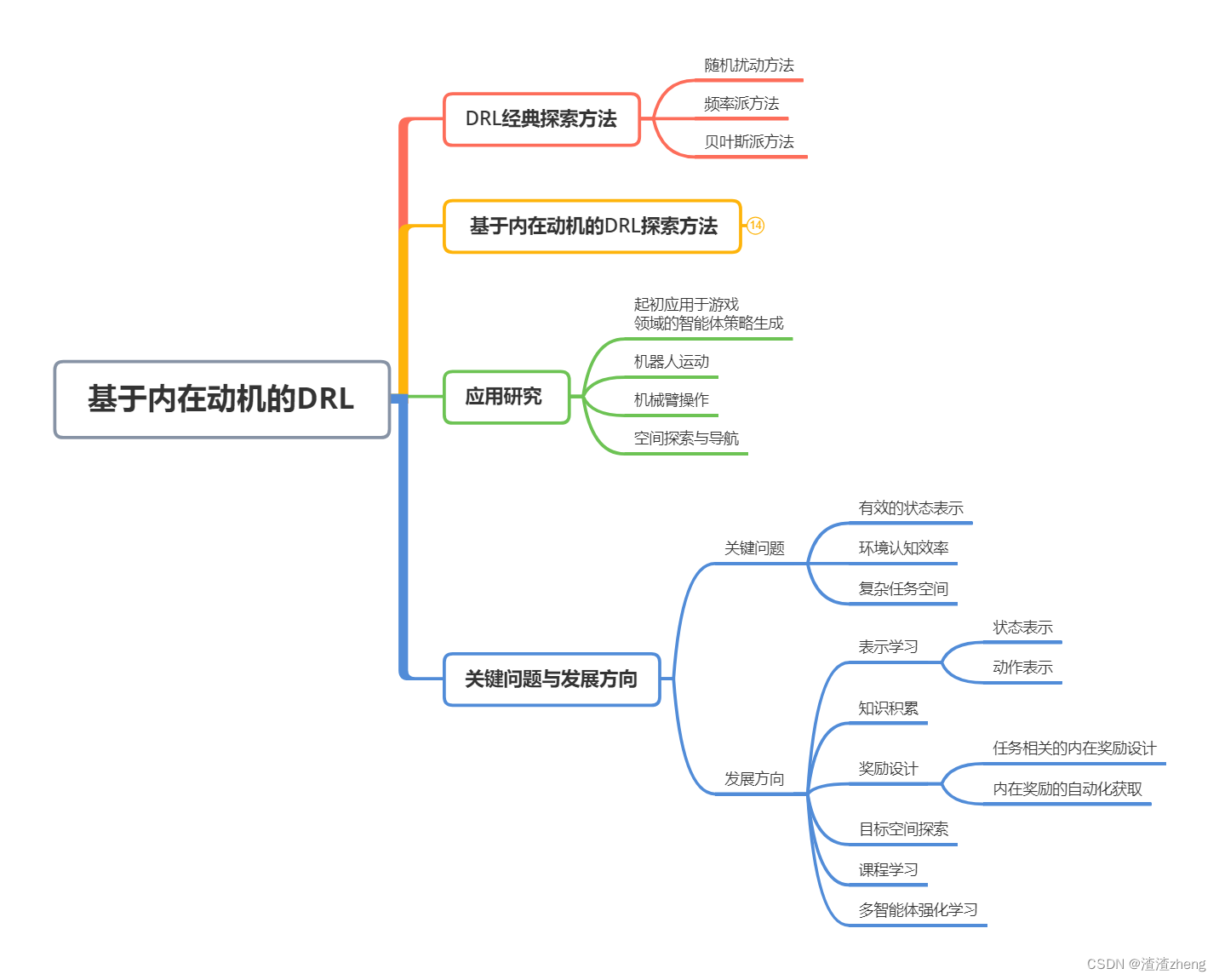
 本文介绍了强化学习、深度强化学习以及基于内在动机的深度强化学习,探讨了在稀疏奖励和随机噪声环境中的探索难题。深度强化学习在游戏、机器人等领域取得显著成果,但面临探索效率低下的问题。基于内在动机的探索方法,如新颖性、好奇心和学习提升,旨在提高智能体在复杂环境中的探索效率。然而,这种方法在动态、高维环境中的应用仍面临有效状态表示、环境认知效率和复杂任务空间探索等关键问题,未来的研究方向包括表示学习、知识积累、奖励设计等。
本文介绍了强化学习、深度强化学习以及基于内在动机的深度强化学习,探讨了在稀疏奖励和随机噪声环境中的探索难题。深度强化学习在游戏、机器人等领域取得显著成果,但面临探索效率低下的问题。基于内在动机的探索方法,如新颖性、好奇心和学习提升,旨在提高智能体在复杂环境中的探索效率。然而,这种方法在动态、高维环境中的应用仍面临有效状态表示、环境认知效率和复杂任务空间探索等关键问题,未来的研究方向包括表示学习、知识积累、奖励设计等。
一、前言
强化学习(reinforcement learning, RL)是监督学习、 无监督学习之外的另一机器学习范式, 通过设置反映目标任务的奖励函数, 驱动智能体在与环境的交互与试错中学习能使累计收益最大化的策略.强化学习一般采用马尔科夫决策过程(Markov decision process, MDP)进行问题形式化描述.强化学习智能体的目标是学习一个策略(policy) 𝜋: 表示从状态到动作概率的映射.
深度强化学习(deep reinforcement learning, DRL) 是在强化学习提供的最优决策能力的基础上, 结合深度学习(deep learning, DL)强大的高维数据表征能力来拟合价值函数或策略, 进而基于交互样本训练得到最优价值函数或最优策略, 被认为是结合感知智能和认知智能的有效方法. 深度强化学习在游戏人工智能、机器人、自然语 言处理、金融等诸多领域取得了超越人类的性能表现 , 但在具备稀疏奖励、随机噪声等特性的环境中, 难以通过随机探索方法获得包含有效奖励信息的状态动作样本, 导致训练过程效率低下甚至无法学习到有效策略. 具体来说, 一方面现实应用中往往存在大量奖励信号十分稀疏甚至没有奖励的场景. 智能体在这类场景探索时需要执行一系列特定的动作, 以到达少数特定的状态来获得奖励信号, 这使得在初始时缺乏所处环境知识的智能体很难收集到有意义的奖励信号来进行学习. 例如, 多自由度机械臂在执行移动物体任务中, 需要通过系列复杂的位姿控 制将物体抓取并放置到指定位置, 才能获得奖励. 另一方面, 现实环境往往具有高度随机性, 存在意料之外的无关环境要素(如白噪声等), 大大降低了智能体的探索效率, 使其难以构建准确的环境模型来学习有效策略. 例如, 部署应用在商场的服务机器人在执行视觉导航任务时, 既要受到商场中大量的动态广告图片或视频的传感干扰, 还可能面临动作执行器与环境交互时的结果不确定性, 同时长距离的导航任务也使其难以获得有效正奖励信号. 因此深度强化学习领域亟需解决探索困难问题, 这对提高 DRL 的策略性能和训练效率都十分重要.
针对奖励稀疏、随机噪声等引起的探索困难问题, 研究者们提出了基于目标、不确定性度量、模仿学习 等探索方法, 但对任务指标的提升效果有限, 并增加了额外的数据获取的代价. 近年来, 源自心理学的内在动机(intrinsic motivation)概念因对人类发育过程的合理解释, 逐渐被广泛应用在 DRL 的奖励设计中以解决探索问题.
二、DRL经典探索方法
2.1 随机扰动方法
随机扰动方法可按照加入噪声的位置差异分为 2 类: 一是在动作选择的过程中增加随机性或噪声,如 在𝜀-贪婪算法中.二是在拟合策略的网络参数上加入噪声, 比如参数空间噪声模型和 NoisyNet 模型等.
2.2 频率派方法
频率派基于实际数据样本的估计来衡量状态的不确定性, 在数据量有限的情况下一般采用带有置 信 水 平 的 区 间 估 计 方 法 .
2.3 贝叶斯派方法
贝叶斯学派观点认为, 面对未知环境人们维护 着对于所有可能模型的概率分布以表达其不确定性, 随着观测证据的增多, 后验分布一般比先验分布更 能反映不同备选模型与真实模型的接近程度. 由于 在选择动作时不仅依据观测状态, 也必须考虑对信 念状态的更新, 贝叶斯强化学习方法被认
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









