







2025年广东省职业院校技能大赛高职组“大数据应用开发”赛项任务书(五)
文章目录
任务 A:大数据平台搭建(容器环境)(15 分)
环境说明:

子任务一:Hadoop 完全分布式安装配置
本任务需要使用 root 用户完成相关配置,安装 Hadoop 需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
1、 从 虚 拟 机 bigdata-spark 的 /opt/software 目 录 下 将 安 装 包 hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz 复制到容器 master中的/opt/software 路径中(若路径不存在,则需新建),将 master 节点 JDK 安装包解压到/opt/module 路径中(若路径不存在,则需新建),将 JDK解压命令复制并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
2、 修改容器中~/.bashrc 文件,设置 JDK 环境变量并使其生效,配置完毕后在 Master 节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
3、 请完成 host 相关配置,将三个节点分别命名为 master、slave1、slave2,并做免密登录,用 scp 命令并使用绝对路径从 master 复制 JDK 解压后的安装文件到 slave1、slave2 节点(若路径不存在,则需新建),并配置 slave1、 slave2 相关环境变量,将全部 scp 复制 JDK 的命令复制并粘贴至物理机桌面
【Release\任务 A 提交结果.docx】中对应的任务序号下;
4、 在 master 将 Hadoop 解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至 slave1、slave2 中,其中 master、slave1、slave2 节点均作为 datanode,配置好相关环境,初始化 Hadoop 环境 namenode,将初始化命令及初始化结果截图,截取初始化结果日志最后 20 行(需包含出现成功格式化提示的行),粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
5、 启动 Hadoop 集群(包括 hdfs 和 yarn),使用 jps 命令查看 master 节点与 slave1 节点、slave2 节点的 Java 进程,将 jps 命令与结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下。
子任务二:ClickHouse 单节点安装配置
本任务需要使用 root 用户完成相关配置,具体要求如下:
1、 从虚拟机 bigdata-spark 的/opt/software 将 clickhouse 开头的相关文件复制到容器 Master 中的/opt/module/clickhouse 路径中(若路径不存在,则需新建),将全部解压命令复制并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
2、 执行启动各个相关脚本,将全部启动命令复制并将执行结果(截取结果最后倒数 15 行即可)截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
3、 设置远程访问并移除默认监听文件(listen.xml),同时由于 9000 端口被 Hadoop 占用,需要将 clickhouse 的端口更改为 9001,并启动 clickhouse,启动后查看 clickhouse 运行状态,并将启动命令复制、查看运行状态命令复制并将执行结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下。
子任务三:Hudi 安装配置
本任务需要使用 root 用户完成相关配置,具体要求如下:
1、 从虚拟机bigdata-spark 的/opt/software 目录下将hudi-0.12.0.src.tgz、 spark-3.2.1-bin-hadoop3.2.tgz 等相关安装包复制到容器 Master 中的
/opt/software(若路径不存在,则需新建)中,将 hudi-0.12.0.src.tgz、 spark-3.2.1-bin-hadoop3.2.tgz 相关安装包解压到/opt/module/ 目录下
(若路径不存在,则需新建),将命令复制并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
2、 完 成 解 压 安 装 及 配 置 后 使 用 maven 离 线 编 译 对 Hudi 进 行 构 建
( spark3.2,scala-2.12 ) , 编译完成后与 Spark 集成, 集成后使用 spark-shell 操作 Hudi,将 spark-shell 启动使用 spark-shell 运行下面给到的案例,并将最终查询结果的完整截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下。
(提示:编译前需要完成以下步骤:
1.将 虚 拟 机 bigdata-spark 上 的 /opt/hudi-spark-bundle/ 、
/opt/hudi-utilities-bundle 拷贝到容器 master 的/opt/目录下,
2.修改 HoodieParquetDataBlock.java 部分行代码
hudi-common/src/main/java/org/apache/hudi/common/table/log/block/Hood ieParquetDataBlock.java;
3.使用/opt/hudi-spark-bundle/pom.xml 对 hudi-0.12.0 目录下 packaging/hudi-spark-bundle/pom.xml 替换;
4.使 用 /opt/hudi-utilities-bundle/pom.xml 对 hudi-0.12.0 目 录 下 packaging/hudi-utilities-bundle/pom.xml 替换)
测试 Spark 和 hudi 的 demo 程序
import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow" val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) df.write.format("hudi").
options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName).
mode(Overwrite). save(basePath)
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*") tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot") spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
任务 B:离线数据处理(25 分)
环境说明:

子任务一:数据抽取
编 写 Scala 代 码 , 使 用 Spark 将 MySQL 的 spark_test 库 中 表 clothing_sales_spark 的 数 据 全 量 抽 取 到 Hive 的 ods 库 中 对 应 表 clothing_sales_spark 中
1、 抽取 MySQL 的 spark_test 库中 clothing_sales_spark 表的全量数据进入 Hive 的 ods 库中表 clothing_sales_spark,字段排序、类型不变,分区字段为 etldate,类型为 String,且值为当前比赛日的前一天日期(分区字段格式为 yyyy-MM-dd),使用 Hive 的 cli 执行 select count(*) from ods. clothing_sales_spark 命令,将执行结果截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下。
子任务二:数据清洗
编写Scala 代码,使用 Spark 将ods 库中相应表数据全量抽取到Hive 的dwd 库对应表中。表中有涉及到 timestamp 类型的,均要求按照 yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加 00:00:00,添 加之后使其符合 yyyy-MM-dd HH:mm:ss。(若 dwd 库中部分表没有数据,正常抽取即可)
抽 取 ods 库 中 clothing_sales_spark 表 中 全 量 数 据 进 入 dwd 库 表 clothing_sales_spark 中,分区字段为 etldate,值与 ods 库的相对应表该值相等且要符合以下几个要求:
1、 如果订单折扣率字段有缺失值,则使用(零售单价-折后单价)/零售单价计算后进行填充,将查询日销明细单 ID 为
RXDMX-00c28b80a3e60f5c18f69b2a93861112-5、 RXDMX-1e3f59d9979d8655ce833b9b985c09e9-7、
RXDMX-1b9d52484507a08ad34e0e71be5031c1-2 的三个订单结果截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
2、 处理日销单明细 id 重复的数据,根据交易时间取较新的一条数据,交易信 息老旧一条数据进行删除,请统计出该张表去除重复数据后一共有多少数据,截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
3、 如果订单明细中的零售单价字段为空,则根据折扣率和折后单价计算零售单价进行填充,请统计处理后宽表中零售单价的平均数,截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下。
子任务三:指标计算
编写 Scala 代码,使用 Spark 计算相关指标。
1、 根据 dwd 层表,计算 2024 年每个门店的单品(款式)销售表现,包括销售数量和销售金额,并计算每个门店的单品(款式)销售效率(即销售金额与销售数量的比值),找出每个门店单品销售效率排名前 5 的单品,将计算结果存入Hive 的dws 数据库的product_sales_efficiency 表中(表结构如下),然后使用 hive cli,根据门店编码、门店名称、单品销售效率的排名均为升排序,查询前 8 行,将 SQL 语句复制粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
| 字段名 | 类型 | 中文含义 | 备注 |
|---|---|---|---|
| store_code | int | 门店编码 | |
| store_name | string | 门店名称 | |
| product_code | string | 款式编码 | |
| sales_quantity | int | 销售数量 | |
| sales_amount | double | 销售金额 | |
| sales_efficiency | double | 单品销售效率 | 单品销售效率( 销售金额/ 销售数量) |
| ranking_by_efficiency | int | 销售效率排名 | 按单品销售效率排序的排名 |
2、 根据 dwd 层表,通过计算门店的销售效率与顾客服务效率,评估门店 2024年的经营状况。销售效率通过“实际支付总价”与“销售数量”之比计算,顾客服务效率通过“销售数量”与“交易次数”之比计算,分析每个门店的销售效率与顾客服务效率,并输出表现最好的门店。将查询结构存入 MySQL数据库 spark_result 的 store_sales_efficiency 表中(表结构如下),然后在 Linux 的 MySQL 命令行中,根据综合效率排名升序排序,查询出前 5 条,将 SQL 语句复制粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
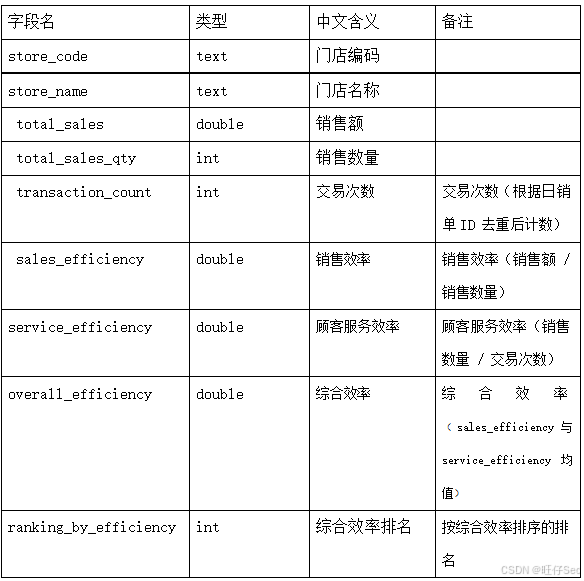
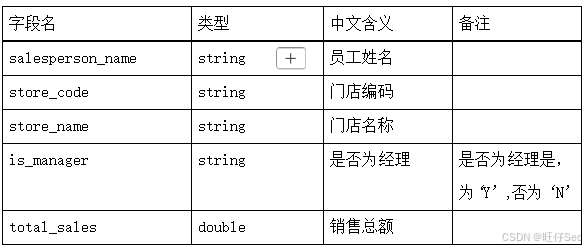
3、 根据 dwd 层表,计算 2024 年每个门店员工的销售额与其业绩表现。销售额使用实际支付总价来衡量。通过 IS_MANAGER 字段,区分门店经理和普通员工,计算每位门店员工(包括普通员工与门店经理)的销售业绩,输出每个门店员工姓名、门店编码、所属门店、是否为经理、销售总额,存入 Hive的 dws 数据库的 employee_sales 表中(表结构如下),然后使用 hive cli,根据门店编码、门店名称升序、销售总额降序排序,查询出前 5 条,将 SQL语句复制粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务 B 提交结果.docx】中对应的任务序号下。
任务 C:数据挖掘(10 分)
环境说明:

子任务一:特征工程
使用 Idea Spark 工程或 Spark-shell , 读取虚拟机 bigdata-spark 的
/opt/data 目录下的 credit_train.csv:
1、 使用 VectorAssembler 对 Age、Income、dist_home_val、dist_avg_income、 high_avg 进行特征工程处理,使用 transform 处理,使用 Dataframe 的 show(5, truncate =false)打印特征向量列的前 5 行。将对应 show 代码以及 show 结果的截图粘贴至物理机桌面【Release\任务 C 提交结果.docx】中对应的任务序号下。
2、 使用 StandardScaler 对 VectorAssembler 处理后的特征向量列进行标准化处理,使用 transform 处理,使用 Dataframe 的 show(5, truncate =false)打印特征向量列、标准化向量列的前 5 行。将对应 show 代码以及 show 结果的截图粘贴至物理机桌面【Release\任务 C 提交结果.docx】中对应的任务序号下。
子任务二:信用卡支出预测
使用 Idea Spark 工程或 Spark-shell , 读取虚拟机 bigdata-spark 的
/opt/data 目录下的 credit_test.csv:
1、 接子任务一,将 credit_train.csv 划分 80%训练集和 20%测试集,使用 Idea Spark 工程或 Spark-shell,基于 GBTR 梯度提升决策树模型(GBTR 相关参数可自定义,不做限制)编写信用卡支出预测,使用 80%训练集训练处模型后,使用 20%测试集进行预测,并使用 show(5, truncate =false)输出预测结果中 prediction,avg_exp 三列结果。将对应 show 的代码以及 show 结果的截图粘贴至物理机桌面【Release\任务 C 提交结果.docx】中对应的任务序号下
2、 结合已训练好的模型,预测虚拟机 bigdata-spark 的/opt/data 目录下的 credit_test.csv 新数据集,并使用 show(5, truncate = false)输出预测结果中以下列
“Age” “Income”
“dist_home_val” “dist_avg_income” “high_avg” “avg_exp” “prediction”
将对应 show 的代码以及 show 结果的截图粘贴至物理机桌面【Release\任务 C 提交结果.docx】中对应的任务序号下
任务 D:数据采集与实时计算(20 分)
环境说明:

子任务一:实时数据采集
1、 在虚拟机 bigdata-spark 使用 Flume 采集/opt/data 目录下实时日志文件中的 数 据 ( 如 果 没 有 权 限 , 请 执 行 授 权 命 令 chmod 777
/opt/data/ChangeRecord),将数据存入到 Kafka 的 Topic 中(Topic 名称分别为 ChangeRecord、ProduceRecord 和 EnvironmentData,分区数为 4),将 Flume 采集 ChangeRecord 主题的配置截图粘贴至客户端桌面【Release\任务 D 提交结果.docx】中对应的任务序号下;
子任务二:使用Flink 处理Kafka 中的数据
编写 Scala 工程代码,使用 Flink 消费 Kafka 中的数据并进行相应的数据统计计算。
1、 使用 Flink 消费 Kafka 中 ProduceRecord 主题的数据,统计在已经检验的产品中,各设备每 5 分钟生产产品总数,将结果存入 Redis 中,key 值为 “totalproduce”,value 值为“设备 id,最近五分钟生产总数”。使用 redis cli 以 HGETALL key 方式获取 totalproduce 值,将结果截图粘贴至客户端桌面【Release\任务 D 提交结果.docx】中对应的任务序号下;
注:ProduceRecord 主题,生产一个产品产生一条数据; change_handle_state 字段为 1 代表已经检验,0 代表未检验;时间语义使用 Processing Time。
2、 使用 Flink 消费 Kafka 中 ChangeRecord 主题的数据,当某设备 30 秒状态连续为“预警”,输出预警信息。当前预警信息输出后,最近 30 秒不再重复
预警(即如果连续 1 分钟状态都为“预警”只输出两次预警信息),将结果存入 Redis 中,key 值为“warning30sMachine”,value 值为“设备 id,预警信息”。使用 redis cli 以 HGETALL key 方式获取 warning30sMachine 值,将结果截图粘贴至客户端桌面【Release\任务 D 提交结果.docx】中对应的任务序号下(如有中文,需在 redis-cli 中展示中文);
注:时间使用 change_start_time 字段,忽略数据中的 change_end_time 不参与任何计算。忽略数据迟到问题。
Redis 的 value 示例:115,2022-01-01 09:53:10:设备 115 连续 30 秒为预警状态请尽快处理!
(2022-01-01 09:53:10 为 change_start_time 字段值,中文内容及格式必须为示例所示内容。)
任务 E:数据可视化(15 分)
环境说明:

子任务一:用柱状图展示销售金额最高的导购人员名称
编 写 Vue 工 程 代 码 , 读 取 虚 拟 机 bigdata-spark 的 /opt/data 目 录 下 clothing_sales_data.csv 文件,用柱状图展示 2024 年销售金额最高的前 10 个导购,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务一:用柱状图展示销售数量最低的门店
编 写 Vue 工 程 代 码 , 读 取 虚 拟 机 bigdata-spark 的 /opt/data 目 录 下 clothing_sales_data.csv 文件,用柱状图展示 2023~2024 年销售数量最低的前 5 个门店,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务三:用折线图展示不同月份销售量变化
编 写 Vue 工 程 代 码 , 读 取 虚 拟 机 bigdata-spark 的 /opt/data 目 录 下
clothing_sales_data.csv 文件,用折线图展示 2023 年不同月份销售量变化,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务五:用饼状图展示不同门店的销售金额
编 写 Vue 工 程 代 码 , 读 取 虚 拟 机 bigdata-spark 的 /opt/data 目 录 下 clothing_sales_data.csv 文件,用饼状图展示 2023-2024 年不同门店的销售金额,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务五:用基础南丁格尔玫瑰图展示销量最高的门店
编 写 Vue 工 程 代 码 , 读 取 虚 拟 机 bigdata-spark 的 /opt/data 目 录 下 clothing_sales_data.csv 文件,用基础南丁格尔玫瑰图展示 2023~2024 年销售数量最高的前 10 门店,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
任务 F:综合分析(10 分)
子任务一:详细分析 Flink 中 Checkpoint 的 Barrier 协议如何确保 Checkpoint 的一致性。
将内容编写至客户端桌面【Release\任务 F 提交结果.docx】中对应的任务序号下。
子任务二:在高吞吐量场景中,State Backend 的存储可能成为瓶颈。如何优化RocksDB Backend 的性能,降低 Checkpoint 延迟?
将内容编写至客户端桌面【Release\任务 F 提交结果.docx】中对应的任务序号下。
子任务三:Fair Scheduler 如何解决高优先级任务长时间等待资源?
将内容编写至客户端桌面【Release\任务 F 提交结果.docx】中对应的任务序号下。
附录:补充说明
截图样例(保证清晰,选取可视区域截取)
表结构说明
1.1门店服装销售数据表(clothing_sales_spark)
| 标签 | 中文含义 | 备注 |
|---|---|---|
| daily_sales_detail_id | 日销单明细 ID | |
| daily_sales_id | 日销单 ID | |
| style_combo_code | 款式组合编码 | |
| sales_quantity | 销售数量 | |
| retail_unit_price | 零售单价 | |
| discount_rate | 折扣率 | |
| discounted_unit_price | 折后单价 | |
| discounted_total_price | 折后总价 | |
| store_code | 门店编码 | |
| salesperson_code | 导购员编码 | |
| transaction_time | 交易时间 | |
| product_combo_name | 款式组合名称 | |
| product_code | 款式编码 | |
| salesperson_name | 导购员姓名 | |
| is_manager | 是否门店经理 | |
| store_name | 门店名称 |
1.2信用卡支出数据文件(credit_train.csv)
| 标签 | 中文含义 | 备注 |
|---|---|---|
| Age | 年龄 | |
| Income | 收入 | |
| dist_home_val | 所在小区房屋均价( 万元) | |
| dist_avg_income | 当地人均收入 | |
| high_avg | 高出当地平均收入 | |
| avg_exp | 信用卡支出(元) |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











