







2025年广东省职业院校技能大赛 “大数据应用开发”赛项技能测试试卷(一)
文章目录
任务 A:大数据平台搭建(容器环境)(15 分)
环境说明:

子任务一:Hadoop 完全分布式安装配置
本任务需要使用 root 用户完成相关配置,安装 Hadoop 需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
1、 从 虚 拟 机 bigdata-spark 的 /opt/software 目 录 下 将 安 装 包 hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz 复制到容器 master中的/opt/software 路径中(若路径不存在,则需新建),将 master 节点 JDK 安装包解压到/opt/module 路径中(若路径不存在,则需新建),将 JDK解压命令复制并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
2、 修改容器中~/.bashrc 文件,设置 JDK 环境变量并使其生效,配置完毕后在 Master 节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
3、 请完成 host 相关配置,将三个节点分别命名为 master、slave1、slave2,并做免密登录,用 scp 命令并使用绝对路径从 master 复制 JDK 解压后的安装文件到 slave1、slave2 节点(若路径不存在,则需新建),并配置 slave1、 slave2 相关环境变量,将全部 scp 复制 JDK 的命令复制并粘贴至物理机桌面
【Release\任务 A 提交结果.docx】中对应的任务序号下;
4、 在 master 将 Hadoop 解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至 slave1、slave2 中,其中 master、slave1、slave2 节点均作为 datanode,配置好相关环境,初始化 Hadoop 环境 namenode,将初始化命令及初始化结果截图,截取初始化结果日志最后 20 行(需包含出现成功格式化提示的行),粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
5、 启动 Hadoop 集群(包括 hdfs 和 yarn),使用 jps 命令查看 master 节点与 slave1 节点、slave2 节点的 Java 进程,将 jps 命令与结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下。
子任务二:Spark on Yarn 安装配置
本任务需要使用 root 用户完成相关配置,已安装 Hadoop 及需要配置前置环境,具体要求如下:
1、 从 虚 拟 机 bigdata-spark 的 /opt/software 目 录 下 将 安 装 包 spark-3.2.1-bin-hadoop3.2.tgz 复制到容器 master 中的/opt/software
(若路径不存在,则需新建)中,将 Spark 包解压到/opt/module 路径中(若路径不存在,则需新建),将完整解压命令复制粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
2、 修改容器中~/.bashrc 文件,设置 Spark 环境变量并使环境变量生效,在/opt目录下运行命令 spark-submit --version,将命令与结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
3、 完 成 on yarn 相 关 配 置 , 使 用 spark on yarn 的 模 式 提 交
$SPARK_HOME/examples/jars/spark-examples_2.12-3.2.1.jar 运行的主类为 org.apache.spark.examples.SparkPi,将运行结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下(截取 Pi 结果的前后各 5 行)。
子任务三:HBase 分布式安装配置
本任务需要使用 root 用户完成相关配置, 安装 HBase 需要配置 Hadoop 和 ZooKeeper 等前置环境。命令中要求使用绝对路径,具体要求如下:
1、 从 虚 拟 机 bigdata-spark 的 /opt/software 目 录 下 将 安 装 包 apache-zookeeper-3.5.7-bin.tar.gz、hbase-2.2.3-bin.tar.gz 复制到容器 master 中的/opt/software 路径中(若路径不存在,则需新建),将 ZooKeeper、HBase 安装包解压到/opt/module 目录下,将 HBase 的解压命令复制并粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
2、 完成 ZooKeeper 相关部署,用 scp 命令并使用绝对路径从容器 master 复制 HBase 解压后的包分发至 slave1、slave2 中,并修改相关配置,配置好环境变量,在容器 Master 节点中运行命令 hbase version,将全部复制命令复制并将 hbase version 命令的结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序号下;
3、 启动HBase 后在三个节点分别使用jps 命令查看,正常启动后在hbase shell中查看命名空间,将三个节点查看的 hbase 服务进程和查看命名空间的结果截图粘贴至物理机桌面【Release\任务 A 提交结果.docx】中对应的任务序
号下。
任务 B:离线数据处理(25 分)
环境说明:

子任务一:数据抽取
编 写 Scala 代 码 , 使 用 Spark 将 MySQL 的 spark_test 库 中 表 supermarket_spark 的 数 据 全 量 抽 取 到 Hive 的 ods 库 中 对 应 表 supermarket_spark 中:
1、抽取 MySQL 的 spark_test 库中 supermarket_spark 表的全量数据进入 Hive的ods 库中表supermarket_spark,字段排序、类型不变,分区字段为etldate,类型为 String , 且值为当前比赛日的前一天日期( 分区字段格式为 yyyy-MM-dd ) , 使 用 hive cli 执 行 select count ( * ) from ods.supermarket_spark 命令, 将执行结果截图粘贴至物理机桌面
【Release\任务 B 提交结果.docx】中对应的任务序号下;
子任务二:数据清洗
编写Scala 代码,使用 Spark 将ods 库中相应表数据全量抽取到Hive 的dwd 库对应表中。表中有涉及到 timestamp 类型的,均要求按照 yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加 00:00:00,添 加之后使其符合 yyyy-MM-dd HH:mm:ss。(若 dwd 库中部分表没有数据,正常抽取即可)抽 取 ods 库 中 supermarket_spark 表 中 全 量 数 据 进 入 dwd 库 表 supermarket_spark 中,分区字段为 etldate,值与 ods 库的相对应表该值相等且要符合以下几个要求:
1、 2023 年没有 2 月 29 日,所以删除 2023 年 2 月 29 日的数据。使用 hive cli执 行 select * from dwd.supermarket_spark where order_date='2023-02-29’查询 supermarket_spark 的数据,将删除前后的查询结果截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
2、 如果销售数量有缺失值, 则删除销售数量为缺失值的记录。 查询 supermarket_spark 中销售数量为缺失值的记录,将删除前后部分行的结果截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
3、 商品单价、销售数量,销售金额存在异常值,(1)删除商品单价和销售金额为 0 的记录,将删除前后部分行的结果截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;(2)增加一个字段作为是否退货标识,将销售金额少于 0 的记录标记为 1 表示退货,查询部分行并截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
(3)存在单价*数量不等于销售金额的情况,说明实际销售价格可能会有所变化,加一个字段显示实际销售价格。将处理前后部分行的结果截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下。
子任务三:指标计算
编写 Scala 代码,使用 Spark 计算相关指标。
注:在指标计算中,不考虑退货的订单,若退货标识为 1,则忽略该条订单记录。
1、 根据 dwd 层表统计每个月每个大类销售的总金额,并按照 year,month 进行分组,按照总金额 total_amount 降序排序,形成 sequence 值,将计算结果存入 Hive 的 dws 数据库的 consumption_categories 表中(表结构如下),然后使用 hive cli 根据年、月、次序均为升序排序,查询出前 5 条,将 SQL语句复制粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
| 字段 | 类型 | 中文含义 | 备注 |
|---|---|---|---|
| major_category_id | string | 大类编号 | |
| major_category_name | string | 大类名称 | |
| total_amount | double | 销售总金额 | 当月每个大类订单总金额 |
| sequence | int | 次序 | |
| year | string | 年 | 销售的年 |
| month | string | 月 | 销售的月 |
2、 根据 dwd 层表查询顾客本次购买金额及上一次的购买金额,若顾客为首次购买,则上次购买金额用 0 填充,查询结果存入 MySQL 数据库 spark_result的 userorderamount 表(表结构如下)中,然后在 Linux 的 MySQL 命令行中根据顾客编号、销售日期均为升序排序,查询出前 5 条,将 SQL 语句复制粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下;
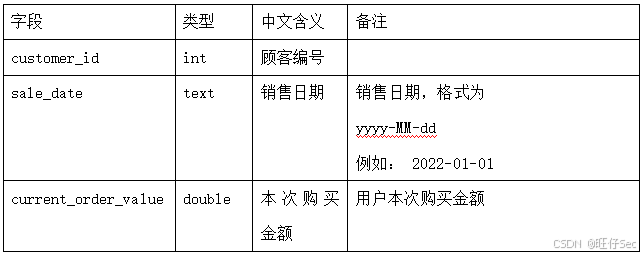

3、 根据 dwd 层表统计在两天内连续下单并且购买金额保持增长的用户,存入 MySQL 数据库 spark_result 的 usercontinueorder 表(表结构如下)中,然后在 Linux 的 MySQL 命令行中根据顾客编号、销售日期均为升序排序,查询出前 5 条,将 SQL 语句复制粘贴至物理机桌面【Release\任务 B 提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至物理机桌面【Release\任务 B提交结果.docx】中对应的任务序号下。
| 字段 | 类型 | 中文含义 | 备注 |
|---|---|---|---|
| customer_id | int | 顾客编号 | |
| day | text | 日 | 记录销售日的时间,格式为 yyyy-MM-dd_yyyy-MM-dd例如: 2022-01-01_2022-01-02 |
| total_consumption | double | 购 买 总 金额 | 连续两天的购买总金额 |
任务 C:数据挖掘(10 分)
环境说明:

子任务一:特征工程
使用 Idea Spark 工程或 Spark-shell,读取虚拟机 bigdata-spark 的/opt/data目录下的 user_churn_trian.csv:
1、将 Churn 列的值按 True 为 1,False 为 0 做映射,并将列名 Churn 改为 ChurnLabel,使用 Dataframe show 前 5 行,将对应 show 代码以及 show结果的截图粘贴至物理机桌面【Release\任务 C 提交结果.docx】中对应的任务序号下。
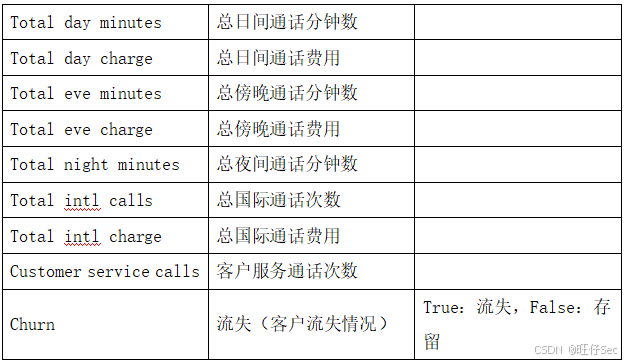
2、使用 StringIndexer 对列 International plan 进行特征工程处理,并将该输出列改为 indexedInternationalPlan, 使用 VectorAssembler 对 indexedInternationalPlan、Total day minutes、Total day charge、 Total eve minutes、Total eve charge、Total night minutes、Total intl calls、Total intl charge、Customer service calls 进行特征工程处理,使用 transform 处理,使用 Dataframe 的 show(5, truncate
=false)只打印特征列的前 5 行。将对应 show 代码以及 show 结果的截图粘贴至物理机桌面【Release\任务 C 提交结果.docx】中对应的任务序号下。
子任务二:用户流失预测
使用 Idea Spark 工程或 Spark-shell,读取虚拟机 bigdata-spark 的/opt/data目录下的 user_churn_test.csv:
1、 接子任务一,user_churn_trian.csv 划分 70%训练集和 30%测试集,使用 Idea Spark 工程或 Spark-shell,基于随机森林模型(随机森林相关参数可自定义,不做限制)编写完整的用户预测流失程序,使用 70%训练集训练处模型后,使用 30%测试集训练模型,并使用 show(5, truncate =false)输出预测结果中"prediction", “ChurnLabel”, "probability"三列结果。将对应 show 的代码以及 show 结果的截图粘贴至物理机桌面【Release\ 任务 C 提交结果.docx】中对应的任务序号下
2、 结合已训练好的模型,预测虚拟机 bigdata-spark 的/opt/data 目录下的 user_churn_test.csv 新数据集,并使用 show(10, truncate = false)输出预测结果中以下列
“Total day minutes”, “Customer service calls”, “Total intl charge”, “Total day charge”, “Total intl calls”, “prediction”, “probability”
将对应 show 的代码以及 show 结果的截图粘贴至物理机桌面【Release\任务 C提交结果.docx】中对应的任务序号下
任务 D:数据采集与实时计算(20 分)
环境说明:

子任务一:实时数据采集
1、 在虚拟机 bigdata-spark 使用 Flume 采集实时数据生成器 10050 端口的 socket 数据(实时数据生成器脚本放在虚拟机 bigdata-spark 的/opt/data目录下的flink_data,将数据存入到 Kafka 的Topic 中,Topic 名称为order,分区数为 3,使用 Kafka 自带的消费者消费 order(Topic)中的数据,将前 2 条数据的结果截图粘贴至物理机桌面【Release\任务 D 提交结果.docx】中对应的任务序号下;
注:需在虚拟机 bigdata-spark 先启动已配置好的 Flume、终端启动 netcat 服务(nc -lk 10050)再启动脚本,否则脚本将无法成功启动,启动方式为进入
/opt/data 目录执行./flink_data(如果没有权限,请执行授权命令 chmod 777
/opt/data/flink_data)
子任务二:使用Flink 处理Kafka 中的数据
编写 Scala 代码,使用 Flink 消费 Kafka 中 Topic 为 order 的数据并进行相应的数据统计计算(订单信息对应表结构 order_info,订单详细信息对应表结构 order_detail(来源类型和来源编号这两个字段不考虑,所以在实时数据中不会出现), 同时计算中使用 order_info 或 order_detail 表中 create_time 或 operate_time 取两者中值较大者作为 EventTime,若 operate_time 为空值或无此列,则使用 create_time 填充,允许数据延迟 5s,订单状态分别为 1001:创建订单、1002:支付订单、1003:取消订单、1004:完成订单、1005:申请退回、1006:退回完成。另外对于数据结果展示时,不要采用例如:1.9786518E7 的科学计数法)。
1、 使用 Flink 消费 Kafka 中的数据,统计商城实时订单实收金额(需要考虑订单状态,若有取消订单、申请退回、退回完成则不计入订单实收金额,其他状态的则累加),将 key 设置成 totalprice 存入 Redis 中。使用 redis cli以get key 方式获取totalprice 值,将结果截图粘贴至物理机桌面【Release\任务 D 提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔 1 分钟以上,第一次截图放前面,第二次截图放后面;
2、 在任务 1 进行的同时,使用侧边流,监控若发现 order_status 字段为退回完成, 将 key 设置成 totalrefundordercount 存入 Redis 中,value 存放用户退款消费额。使用 redis cli 以 get key 方式获取 totalrefundordercount值,将结果截图粘贴至物理机桌面【Release\任务 D 提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔 1 分钟以上,第一次截图放前面,第二次截图放后面;
任务 E:数据可视化(15 分)
环境说明:

子任务一:用柱状图展示销售金额最高的 6 个月
编写 Vue 工程代码, 读取虚拟机 bigdata-spark 的/opt/data 目录下的 supermarket_visualization.csv,用柱状图展示2024 年销售金额最高的6 个月,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务二:用柱状图展示销售金额最高的大类名称
编写 Vue 工程代码, 读取虚拟机 bigdata-spark 的/opt/data 目录下的 supermarket_visualization.csv,用柱状图展示 2024 年销售金额最高的 6 个大类名称,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务三:用折线图展示销售金额变化
编写 Vue 工程代码, 读取虚拟机 bigdata-spark 的/opt/data 目录下的 supermarket_visualization.csv,用折线图展示 2023~2024 年销售金额变化,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务四:用散点图展示中类名称的销售数量
编写 Vue 工程代码, 读取虚拟机 bigdata-spark 的/opt/data 目录下的 supermarket_visualization.csv,用基础散点图展示 2023~ 2024 年中类名称销售数量变化情况,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面
【Release\任务 E 提交结果.docx】中对应的任务序号下。
子任务五:用基础南丁格尔玫瑰图展示中类名称的销售金额
编写 Vue 工程代码, 读取虚拟机 bigdata-spark 的/opt/data 目录下的 supermarket_visualization.csv,用基础南丁格尔玫瑰图展示 2023 年中类名称销量金额前 10 名,同时将用于图表展示的数据结构在 vscode 终端中进行打印输出,将图表可视化结果和 vscode 终端打印结果分别截图并粘贴至物理机桌面
【Release\任务 E 提交结果.docx】中对应的任务序号下。
任务 F:综合分析(10 分)
子任务一:请简述Kafka 如何保证消息的顺序性和可靠性?
请简述 Kafka 如何保证消息的顺序性和可靠性?请分析其实现机制,将内容编写至客户端桌面【Release\任务 F 提交结果.docx】中对应的任务序号下。
子任务二:请简述HBase 的行键设计有哪些原则?
请简述 HBase 的行键设计有哪些原则?将内容编写至客户端桌面【Release\任务 F 提交结果.docx】中对应的任务序号下。
子任务三:请简述 Spark 中出现数据倾斜的原因并给出至少两种解决方法。
本次竞赛中使用到了 Spark,请简述 Spark 中出现数据倾斜的原因并给出至少两种解决方法。将内容编写至客户端桌面【Release\任务 F 提交结果.docx】中对应的任务序号下。
附录:补充说明
截图样例(保证清晰,选取可视区域截取)
表结构说明
1.1超市订单记录表(supermarket_spark)
| 标签 | 中文含义 | 备注 |
|---|---|---|
| customer_id | 顾客编号 | |
| major_category_id | 大类编码 | |
| major_category_name | 大类名称 | |
| medium_category_id | 中类编码 | |
| medium_category_name | 中类名称 | |
| minor_category_id | 小类编码 | |
| minor_category_name | 小类名称 | |
| sale_date | 销售日期 | |
| product_id | 商品编码 | |
| specification_model | 规格型号 | |
| product_type | 商品类型 | |
| unit | 单位 | |
| sale_quantity | 销售数量 | |
| sale_amount | 销售金额 | |
| product_unit_price | 商品单价 | |
| is_promotion | 是否促销 |
1.2用户通话数据文件(user_churn_trian.csv)

测试数据:
通过网盘分享的文件:公开测试数据.zip
链接: https://pan.baidu.com/s/1MG4n1Ft-qbwxcsnK0lp8MQ?pwd=u9v6 提取码: u9v6
–来自百度网盘超级会员v6的分享



















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











